
Function and Expression
Function and Expression
Arithmetic Operators and Functions
Arithmetic Operators
Unary Arithmetic Operators
Supported operators: +, -
Supported input data types: INT32, INT64 and FLOAT
Output data type: consistent with the input data type
Binary Arithmetic Operators
Supported operators: +, -, *, /, %
Supported input data types: INT32, INT64, FLOAT and DOUBLE
Output data type: DOUBLE
Note: Only when the left operand and the right operand under a certain timestamp are not null, the binary arithmetic operation will have an output value.
Example
select s1, - s1, s2, + s2, s1 + s2, s1 - s2, s1 * s2, s1 / s2, s1 % s2 from root.sg.d1
Result:
+-----------------------------+-------------+--------------+-------------+-------------+-----------------------------+-----------------------------+-----------------------------+-----------------------------+-----------------------------+
| Time|root.sg.d1.s1|-root.sg.d1.s1|root.sg.d1.s2|root.sg.d1.s2|root.sg.d1.s1 + root.sg.d1.s2|root.sg.d1.s1 - root.sg.d1.s2|root.sg.d1.s1 * root.sg.d1.s2|root.sg.d1.s1 / root.sg.d1.s2|root.sg.d1.s1 % root.sg.d1.s2|
+-----------------------------+-------------+--------------+-------------+-------------+-----------------------------+-----------------------------+-----------------------------+-----------------------------+-----------------------------+
|1970-01-01T08:00:00.001+08:00| 1.0| -1.0| 1.0| 1.0| 2.0| 0.0| 1.0| 1.0| 0.0|
|1970-01-01T08:00:00.002+08:00| 2.0| -2.0| 2.0| 2.0| 4.0| 0.0| 4.0| 1.0| 0.0|
|1970-01-01T08:00:00.003+08:00| 3.0| -3.0| 3.0| 3.0| 6.0| 0.0| 9.0| 1.0| 0.0|
|1970-01-01T08:00:00.004+08:00| 4.0| -4.0| 4.0| 4.0| 8.0| 0.0| 16.0| 1.0| 0.0|
|1970-01-01T08:00:00.005+08:00| 5.0| -5.0| 5.0| 5.0| 10.0| 0.0| 25.0| 1.0| 0.0|
+-----------------------------+-------------+--------------+-------------+-------------+-----------------------------+-----------------------------+-----------------------------+-----------------------------+-----------------------------+
Total line number = 5
It costs 0.014s
Arithmetic Functions
Currently, IoTDB supports the following mathematical functions. The behavior of these mathematical functions is consistent with the behavior of these functions in the Java Math standard library.
| Function Name | Allowed Input Series Data Types | Output Series Data Type | Required Attributes | Corresponding Implementation in the Java Standard Library |
|---|---|---|---|---|
| SIN | INT32 / INT64 / FLOAT / DOUBLE | DOUBLE | / | Math#sin(double) |
| COS | INT32 / INT64 / FLOAT / DOUBLE | DOUBLE | / | Math#cos(double) |
| TAN | INT32 / INT64 / FLOAT / DOUBLE | DOUBLE | / | Math#tan(double) |
| ASIN | INT32 / INT64 / FLOAT / DOUBLE | DOUBLE | / | Math#asin(double) |
| ACOS | INT32 / INT64 / FLOAT / DOUBLE | DOUBLE | / | Math#acos(double) |
| ATAN | INT32 / INT64 / FLOAT / DOUBLE | DOUBLE | / | Math#atan(double) |
| SINH | INT32 / INT64 / FLOAT / DOUBLE | DOUBLE | / | Math#sinh(double) |
| COSH | INT32 / INT64 / FLOAT / DOUBLE | DOUBLE | / | Math#cosh(double) |
| TANH | INT32 / INT64 / FLOAT / DOUBLE | DOUBLE | / | Math#tanh(double) |
| DEGREES | INT32 / INT64 / FLOAT / DOUBLE | DOUBLE | / | Math#toDegrees(double) |
| RADIANS | INT32 / INT64 / FLOAT / DOUBLE | DOUBLE | / | Math#toRadians(double) |
| ABS | INT32 / INT64 / FLOAT / DOUBLE | Same type as the input series | / | Math#abs(int) / Math#abs(long) /Math#abs(float) /Math#abs(double) |
| SIGN | INT32 / INT64 / FLOAT / DOUBLE | DOUBLE | / | Math#signum(double) |
| CEIL | INT32 / INT64 / FLOAT / DOUBLE | DOUBLE | / | Math#ceil(double) |
| FLOOR | INT32 / INT64 / FLOAT / DOUBLE | DOUBLE | / | Math#floor(double) |
| ROUND | INT32 / INT64 / FLOAT / DOUBLE | DOUBLE | 'places' : Round the significant number, positive number is the significant number after the decimal point, negative number is the significant number of whole number | Math#rint(Math#pow(10,places))/Math#pow(10,places) |
| EXP | INT32 / INT64 / FLOAT / DOUBLE | DOUBLE | / | Math#exp(double) |
| LN | INT32 / INT64 / FLOAT / DOUBLE | DOUBLE | / | Math#log(double) |
| LOG10 | INT32 / INT64 / FLOAT / DOUBLE | DOUBLE | / | Math#log10(double) |
| SQRT | INT32 / INT64 / FLOAT / DOUBLE | DOUBLE | / | Math#sqrt(double) |
Example:
select s1, sin(s1), cos(s1), tan(s1) from root.sg1.d1 limit 5 offset 1000;
Result:
+-----------------------------+-------------------+-------------------+--------------------+-------------------+
| Time| root.sg1.d1.s1|sin(root.sg1.d1.s1)| cos(root.sg1.d1.s1)|tan(root.sg1.d1.s1)|
+-----------------------------+-------------------+-------------------+--------------------+-------------------+
|2020-12-10T17:11:49.037+08:00|7360723084922759782| 0.8133527237573284| 0.5817708713544664| 1.3980636773094157|
|2020-12-10T17:11:49.038+08:00|4377791063319964531|-0.8938962705202537| 0.4482738644511651| -1.994085181866842|
|2020-12-10T17:11:49.039+08:00|7972485567734642915| 0.9627757585308978|-0.27030138509681073|-3.5618602479083545|
|2020-12-10T17:11:49.040+08:00|2508858212791964081|-0.6073417341629443| -0.7944406950452296| 0.7644897069734913|
|2020-12-10T17:11:49.041+08:00|2817297431185141819|-0.8419358900502509| -0.5395775727782725| 1.5603611649667768|
+-----------------------------+-------------------+-------------------+--------------------+-------------------+
Total line number = 5
It costs 0.008s
ROUND
Example:
select s4,round(s4),round(s4,2),round(s4,-1) from root.sg1.d1
+-----------------------------+-------------+--------------------+----------------------+-----------------------+
| Time|root.db.d1.s4|ROUND(root.db.d1.s4)|ROUND(root.db.d1.s4,2)|ROUND(root.db.d1.s4,-1)|
+-----------------------------+-------------+--------------------+----------------------+-----------------------+
|1970-01-01T08:00:00.001+08:00| 101.14345| 101.0| 101.14| 100.0|
|1970-01-01T08:00:00.002+08:00| 20.144346| 20.0| 20.14| 20.0|
|1970-01-01T08:00:00.003+08:00| 20.614372| 21.0| 20.61| 20.0|
|1970-01-01T08:00:00.005+08:00| 20.814346| 21.0| 20.81| 20.0|
|1970-01-01T08:00:00.006+08:00| 60.71443| 61.0| 60.71| 60.0|
|2023-03-13T16:16:19.764+08:00| 10.143425| 10.0| 10.14| 10.0|
+-----------------------------+-------------+--------------------+----------------------+-----------------------+
Total line number = 6
It costs 0.059s
Comparison Operators and Functions
Basic comparison operators
Supported operators >, >=, <, <=, ==, != (or <> )
Supported input data types: INT32, INT64, FLOAT and DOUBLE
Note: It will transform all type to DOUBLE then do computation.
Output data type: BOOLEAN
Example:
select a, b, a > 10, a <= b, !(a <= b), a > 10 && a > b from root.test;
IoTDB> select a, b, a > 10, a <= b, !(a <= b), a > 10 && a > b from root.test;
+-----------------------------+-----------+-----------+----------------+--------------------------+---------------------------+------------------------------------------------+
| Time|root.test.a|root.test.b|root.test.a > 10|root.test.a <= root.test.b|!root.test.a <= root.test.b|(root.test.a > 10) & (root.test.a > root.test.b)|
+-----------------------------+-----------+-----------+----------------+--------------------------+---------------------------+------------------------------------------------+
|1970-01-01T08:00:00.001+08:00| 23| 10.0| true| false| true| true|
|1970-01-01T08:00:00.002+08:00| 33| 21.0| true| false| true| true|
|1970-01-01T08:00:00.004+08:00| 13| 15.0| true| true| false| false|
|1970-01-01T08:00:00.005+08:00| 26| 0.0| true| false| true| true|
|1970-01-01T08:00:00.008+08:00| 1| 22.0| false| true| false| false|
|1970-01-01T08:00:00.010+08:00| 23| 12.0| true| false| true| true|
+-----------------------------+-----------+-----------+----------------+--------------------------+---------------------------+------------------------------------------------+
BETWEEN ... AND ... operator
| operator | meaning |
|---|---|
BETWEEN ... AND ... | within the specified range |
NOT BETWEEN ... AND ... | Not within the specified range |
Example: Select data within or outside the interval [36.5,40]:
select temperature from root.sg1.d1 where temperature between 36.5 and 40;
select temperature from root.sg1.d1 where temperature not between 36.5 and 40;
Fuzzy matching operator
For TEXT type data, support fuzzy matching of data using Like and Regexp operators.
| operator | meaning |
|---|---|
LIKE | matches simple patterns |
NOT LIKE | cannot match simple pattern |
REGEXP | Match regular expression |
NOT REGEXP | Cannot match regular expression |
Input data type: TEXT
Return type: BOOLEAN
Use Like for fuzzy matching
Matching rules:
%means any 0 or more characters._means any single character.
Example 1: Query the data under root.sg.d1 that contains 'cc' in value.
IoTDB> select * from root.sg.d1 where value like '%cc%'
+--------------------------+----------------+
| Time|root.sg.d1.value|
+--------------------------+----------------+
|2017-11-01T00:00:00.000+08:00| aabbccdd|
|2017-11-01T00:00:01.000+08:00| cc|
+--------------------------+----------------+
Total line number = 2
It costs 0.002s
Example 2: Query the data under root.sg.d1 with 'b' in the middle of value and any single character before and after.
IoTDB> select * from root.sg.device where value like '_b_'
+--------------------------+----------------+
| Time|root.sg.d1.value|
+--------------------------+----------------+
|2017-11-01T00:00:02.000+08:00|abc|
+--------------------------+----------------+
Total line number = 1
It costs 0.002s
Use Regexp for fuzzy matching
The filter condition that needs to be passed in is Java standard library style regular expression.
Common regular matching examples:
All characters with a length of 3-20: ^.{3,20}$
Uppercase English characters: ^[A-Z]+$
Numbers and English characters: ^[A-Za-z0-9]+$
Starting with a: ^a.*
Example 1: Query the string of 26 English characters for value under root.sg.d1.
IoTDB> select * from root.sg.d1 where value regexp '^[A-Za-z]+$'
+--------------------------+----------------+
| Time|root.sg.d1.value|
+--------------------------+----------------+
|2017-11-01T00:00:00.000+08:00| aabbccdd|
|2017-11-01T00:00:01.000+08:00| cc|
+--------------------------+----------------+
Total line number = 2
It costs 0.002s
Example 2: Query root.sg.d1 where the value is a string consisting of 26 lowercase English characters and the time is greater than 100.
IoTDB> select * from root.sg.d1 where value regexp '^[a-z]+$' and time > 100
+--------------------------+----------------+
| Time|root.sg.d1.value|
+--------------------------+----------------+
|2017-11-01T00:00:00.000+08:00| aabbccdd|
|2017-11-01T00:00:01.000+08:00| cc|
+--------------------------+----------------+
Total line number = 2
It costs 0.002s
Example 3:
select b, b like '1%', b regexp '[0-2]' from root.test;
operation result
+-----------------------------+-----------+------- ------------------+--------------------------+
| Time|root.test.b|root.test.b LIKE '^1.*?$'|root.test.b REGEXP '[0-2]'|
+-----------------------------+-----------+------- ------------------+--------------------------+
|1970-01-01T08:00:00.001+08:00| 111test111| true| true|
|1970-01-01T08:00:00.003+08:00| 333test333| false| false|
+-----------------------------+-----------+------- ------------------+--------------------------+
IS NULL operator
| operator | meaning |
|---|---|
IS NULL | is a null value |
IS NOT NULL | is not a null value |
Example 1: Select data with empty values:
select code from root.sg1.d1 where temperature is null;
Example 2: Select data with non-null values:
select code from root.sg1.d1 where temperature is not null;
IN operator
| operator | meaning |
|---|---|
IN / CONTAINS | are the values in the specified list |
NOT IN / NOT CONTAINS | not a value in the specified list |
Input data type: All Types
return type BOOLEAN
**Note: Please ensure that the values in the collection can be converted to the type of the input data. **
For example:
s1 in (1, 2, 3, 'test'), the data type ofs1isINT32We will throw an exception because
'test'cannot be converted to typeINT32
Example 1: Select data with values within a certain range:
select code from root.sg1.d1 where code in ('200', '300', '400', '500');
Example 2: Select data with values outside a certain range:
select code from root.sg1.d1 where code not in ('200', '300', '400', '500');
Example 3:
select a, a in (1, 2) from root.test;
Output 2:
+-----------------------------+-----------+------- -------------+
| Time|root.test.a|root.test.a IN (1,2)|
+-----------------------------+-----------+------- -------------+
|1970-01-01T08:00:00.001+08:00| 1| true|
|1970-01-01T08:00:00.003+08:00| 3| false|
+-----------------------------+-----------+------- -------------+
Condition Functions
Condition functions are used to check whether timeseries data points satisfy some specific condition.
They return BOOLEANs.
Currently, IoTDB supports the following condition functions:
| Function Name | Allowed Input Series Data Types | Required Attributes | Output Series Data Type | Description |
|---|---|---|---|---|
| ON_OFF | INT32 / INT64 / FLOAT / DOUBLE | threshold: a double type variate | BOOLEAN | Return ts_value >= threshold. |
| IN_RANGR | INT32 / INT64 / FLOAT / DOUBLE | lower: DOUBLE typeupper: DOUBLE type | BOOLEAN | Return ts_value >= lower && value <= upper. |
Example Data:
IoTDB> select ts from root.test;
+-----------------------------+------------+
| Time|root.test.ts|
+-----------------------------+------------+
|1970-01-01T08:00:00.001+08:00| 1|
|1970-01-01T08:00:00.002+08:00| 2|
|1970-01-01T08:00:00.003+08:00| 3|
|1970-01-01T08:00:00.004+08:00| 4|
+-----------------------------+------------+
Test 1
SQL:
select ts, on_off(ts, 'threshold'='2') from root.test;
Output:
IoTDB> select ts, on_off(ts, 'threshold'='2') from root.test;
+-----------------------------+------------+-------------------------------------+
| Time|root.test.ts|on_off(root.test.ts, "threshold"="2")|
+-----------------------------+------------+-------------------------------------+
|1970-01-01T08:00:00.001+08:00| 1| false|
|1970-01-01T08:00:00.002+08:00| 2| true|
|1970-01-01T08:00:00.003+08:00| 3| true|
|1970-01-01T08:00:00.004+08:00| 4| true|
+-----------------------------+------------+-------------------------------------+
Test 2
Sql:
select ts, in_range(ts, 'lower'='2', 'upper'='3.1') from root.test;
Output:
IoTDB> select ts, in_range(ts,'lower'='2', 'upper'='3.1') from root.test;
+-----------------------------+------------+--------------------------------------------------+
| Time|root.test.ts|in_range(root.test.ts, "lower"="2", "upper"="3.1")|
+-----------------------------+------------+--------------------------------------------------+
|1970-01-01T08:00:00.001+08:00| 1| false|
|1970-01-01T08:00:00.002+08:00| 2| true|
|1970-01-01T08:00:00.003+08:00| 3| true|
|1970-01-01T08:00:00.004+08:00| 4| false|
+-----------------------------+------------+--------------------------------------------------+
Logical Operators
Unary Logical Operators
Supported operator !
Supported input data types: BOOLEAN
Output data type: BOOLEAN
Hint: the priority of ! is the same as -. Remember to use brackets to modify priority.
Binary Logical Operators
Supported operators AND:and,&, &&; OR:or,|,||
Supported input data types: BOOLEAN
Output data type: BOOLEAN
Note: Only when the left operand and the right operand under a certain timestamp are both BOOLEAN type, the binary logic operation will have an output value.
Example:
select a, b, a > 10, a <= b, !(a <= b), a > 10 && a > b from root.test;
Output:
IoTDB> select a, b, a > 10, a <= b, !(a <= b), a > 10 && a > b from root.test;
+-----------------------------+-----------+-----------+----------------+--------------------------+---------------------------+------------------------------------------------+
| Time|root.test.a|root.test.b|root.test.a > 10|root.test.a <= root.test.b|!root.test.a <= root.test.b|(root.test.a > 10) & (root.test.a > root.test.b)|
+-----------------------------+-----------+-----------+----------------+--------------------------+---------------------------+------------------------------------------------+
|1970-01-01T08:00:00.001+08:00| 23| 10.0| true| false| true| true|
|1970-01-01T08:00:00.002+08:00| 33| 21.0| true| false| true| true|
|1970-01-01T08:00:00.004+08:00| 13| 15.0| true| true| false| false|
|1970-01-01T08:00:00.005+08:00| 26| 0.0| true| false| true| true|
|1970-01-01T08:00:00.008+08:00| 1| 22.0| false| true| false| false|
|1970-01-01T08:00:00.010+08:00| 23| 12.0| true| false| true| true|
+-----------------------------+-----------+-----------+----------------+--------------------------+---------------------------+------------------------------------------------+
Aggregate Functions
Aggregate functions are many-to-one functions. They perform aggregate calculations on a set of values, resulting in a single aggregated result.
All aggregate functions except COUNT(), COUNT_IF() ignore null values and return null when there are no input rows or all values are null. For example, SUM() returns null instead of zero, and AVG() does not include null values in the count.
The aggregate functions supported by IoTDB are as follows:
| Function Name | Description | Allowed Input Series Data Types | Required Attributes | Output Series Data Type |
|---|---|---|---|---|
| SUM | Summation. | INT32 INT64 FLOAT DOUBLE | / | DOUBLE |
| COUNT | Counts the number of data points. | All data types | / | INT |
| AVG | Average. | INT32 INT64 FLOAT DOUBLE | / | DOUBLE |
| EXTREME | Finds the value with the largest absolute value. Returns a positive value if the maximum absolute value of positive and negative values is equal. | INT32 INT64 FLOAT DOUBLE | / | Consistent with the input data type |
| MAX_VALUE | Find the maximum value. | INT32 INT64 FLOAT DOUBLE | / | Consistent with the input data type |
| MIN_VALUE | Find the minimum value. | INT32 INT64 FLOAT DOUBLE | / | Consistent with the input data type |
| FIRST_VALUE | Find the value with the smallest timestamp. | All data types | / | Consistent with input data type |
| LAST_VALUE | Find the value with the largest timestamp. | All data types | / | Consistent with input data type |
| MAX_TIME | Find the maximum timestamp. | All data Types | / | Timestamp |
| MIN_TIME | Find the minimum timestamp. | All data Types | / | Timestamp |
| COUNT_IF | Find the number of data points that continuously meet a given condition and the number of data points that meet the condition (represented by keep) meet the specified threshold. | BOOLEAN | [keep >=/>/=/!=/</<=]threshold:The specified threshold or threshold condition, it is equivalent to keep >= threshold if threshold is used alone, type of threshold is INT64 ignoreNull:Optional, default value is true;If the value is true, null values are ignored, it means that if there is a null value in the middle, the value is ignored without interrupting the continuity. If the value is true, null values are not ignored, it means that if there are null values in the middle, continuity will be broken | INT64 |
| TIME_DURATION | Find the difference between the timestamp of the largest non-null value and the timestamp of the smallest non-null value in a column | All data Types | / | INT64 |
| MODE | Find the mode. Note: 1.Having too many different values in the input series risks a memory exception; 2.If all the elements have the same number of occurrences, that is no Mode, return the value with earliest time; 3.If there are many Modes, return the Mode with earliest time. | All data Types | / | Consistent with the input data type |
| STDDEV | Calculate the overall standard deviation of the data. Note: Missing points, null points and NaN in the input series will be ignored. | INT32 INT64 FLOAT DOUBLE | / | DOUBLE |
| COUNT_TIME | The number of timestamps in the query data set. When used with align by device, the result is the number of timestamps in the data set per device. | All data Types, the input parameter can only be * | / | INT64 |
COUNT
example
select count(status) from root.ln.wf01.wt01;
Result:
+-------------------------------+
|count(root.ln.wf01.wt01.status)|
+-------------------------------+
| 10080|
+-------------------------------+
Total line number = 1
It costs 0.016s
COUNT_IF
Grammar
count_if(predicate, [keep >=/>/=/!=/</<=]threshold[, 'ignoreNull'='true/false'])
predicate: legal expression with BOOLEAN return type
use of threshold and ignoreNull can see above table
Note: count_if is not supported to use with SlidingWindow in group by time now
example
raw data
+-----------------------------+-------------+-------------+
| Time|root.db.d1.s1|root.db.d1.s2|
+-----------------------------+-------------+-------------+
|1970-01-01T08:00:00.001+08:00| 0| 0|
|1970-01-01T08:00:00.002+08:00| null| 0|
|1970-01-01T08:00:00.003+08:00| 0| 0|
|1970-01-01T08:00:00.004+08:00| 0| 0|
|1970-01-01T08:00:00.005+08:00| 1| 0|
|1970-01-01T08:00:00.006+08:00| 1| 0|
|1970-01-01T08:00:00.007+08:00| 1| 0|
|1970-01-01T08:00:00.008+08:00| 0| 0|
|1970-01-01T08:00:00.009+08:00| 0| 0|
|1970-01-01T08:00:00.010+08:00| 0| 0|
+-----------------------------+-------------+-------------+
Not use ignoreNull attribute (Ignore Null)
SQL:
select count_if(s1=0 & s2=0, 3), count_if(s1=1 & s2=0, 3) from root.db.d1
Result:
+--------------------------------------------------+--------------------------------------------------+
|count_if(root.db.d1.s1 = 0 & root.db.d1.s2 = 0, 3)|count_if(root.db.d1.s1 = 1 & root.db.d1.s2 = 0, 3)|
+--------------------------------------------------+--------------------------------------------------+
| 2| 1|
+--------------------------------------------------+--------------------------------------------------
Use ignoreNull attribute
SQL:
select count_if(s1=0 & s2=0, 3, 'ignoreNull'='false'), count_if(s1=1 & s2=0, 3, 'ignoreNull'='false') from root.db.d1
Result:
+------------------------------------------------------------------------+------------------------------------------------------------------------+
|count_if(root.db.d1.s1 = 0 & root.db.d1.s2 = 0, 3, "ignoreNull"="false")|count_if(root.db.d1.s1 = 1 & root.db.d1.s2 = 0, 3, "ignoreNull"="false")|
+------------------------------------------------------------------------+------------------------------------------------------------------------+
| 1| 1|
+------------------------------------------------------------------------+------------------------------------------------------------------------+
TIME_DURATION
Grammar
time_duration(Path)
Example
raw data
+----------+-------------+
| Time|root.db.d1.s1|
+----------+-------------+
| 1| 70|
| 3| 10|
| 4| 303|
| 6| 110|
| 7| 302|
| 8| 110|
| 9| 60|
| 10| 70|
|1677570934| 30|
+----------+-------------+
Insert sql
"CREATE DATABASE root.db",
"CREATE TIMESERIES root.db.d1.s1 WITH DATATYPE=INT32, ENCODING=PLAIN tags(city=Beijing)",
"INSERT INTO root.db.d1(timestamp,s1,s2,s3) values(1, 2, 10, true)",
"INSERT INTO root.db.d1(timestamp,s1,s2,s3) values(2, null, 20, true)",
"INSERT INTO root.db.d1(timestamp,s1,s2,s3) values(3, 10, 0, null)",
"INSERT INTO root.db.d1(timestamp,s1,s2,s3) values(4, 303, 30, true)",
"INSERT INTO root.db.d1(timestamp,s1,s2,s3) values(5, null, 20, true)",
"INSERT INTO root.db.d1(timestamp,s1,s2,s3) values(6, 110, 20, true)",
"INSERT INTO root.db.d1(timestamp,s1,s2,s3) values(7, 302, 20, true)",
"INSERT INTO root.db.d1(timestamp,s1,s2,s3) values(8, 110, null, true)",
"INSERT INTO root.db.d1(timestamp,s1,s2,s3) values(9, 60, 20, true)",
"INSERT INTO root.db.d1(timestamp,s1,s2,s3) values(10,70, 20, null)",
"INSERT INTO root.db.d1(timestamp,s1,s2,s3) values(1677570934, 30, 0, true)",
SQL:
select time_duration(s1) from root.db.d1
Result:
+----------------------------+
|time_duration(root.db.d1.s1)|
+----------------------------+
| 1677570933|
+----------------------------+
Note: Returns 0 if there is only one data point, or null if the data point is null.
COUNT_TIME
Grammar
count_time(*)
Example
raw data
+----------+-------------+-------------+-------------+-------------+
| Time|root.db.d1.s1|root.db.d1.s2|root.db.d2.s1|root.db.d2.s2|
+----------+-------------+-------------+-------------+-------------+
| 0| 0| null| null| 0|
| 1| null| 1| 1| null|
| 2| null| 2| 2| null|
| 4| 4| null| null| 4|
| 5| 5| 5| 5| 5|
| 7| null| 7| 7| null|
| 8| 8| 8| 8| 8|
| 9| null| 9| null| null|
+----------+-------------+-------------+-------------+-------------+
Insert sql
CREATE DATABASE root.db;
CREATE TIMESERIES root.db.d1.s1 WITH DATATYPE=INT32, ENCODING=PLAIN;
CREATE TIMESERIES root.db.d1.s2 WITH DATATYPE=INT32, ENCODING=PLAIN;
CREATE TIMESERIES root.db.d2.s1 WITH DATATYPE=INT32, ENCODING=PLAIN;
CREATE TIMESERIES root.db.d2.s2 WITH DATATYPE=INT32, ENCODING=PLAIN;
INSERT INTO root.db.d1(time, s1) VALUES(0, 0), (4,4), (5,5), (8,8);
INSERT INTO root.db.d1(time, s2) VALUES(1, 1), (2,2), (5,5), (7,7), (8,8), (9,9);
INSERT INTO root.db.d2(time, s1) VALUES(1, 1), (2,2), (5,5), (7,7), (8,8);
INSERT INTO root.db.d2(time, s2) VALUES(0, 0), (4,4), (5,5), (8,8);
Query-Example - 1:
select count_time(*) from root.db.**
Result
+-------------+
|count_time(*)|
+-------------+
| 8|
+-------------+
Query-Example - 2:
select count_time(*) from root.db.d1, root.db.d2
Result
+-------------+
|count_time(*)|
+-------------+
| 8|
+-------------+
Query-Example - 3:
select count_time(*) from root.db.** group by([0, 10), 2ms)
Result
+-----------------------------+-------------+
| Time|count_time(*)|
+-----------------------------+-------------+
|1970-01-01T08:00:00.000+08:00| 2|
|1970-01-01T08:00:00.002+08:00| 1|
|1970-01-01T08:00:00.004+08:00| 2|
|1970-01-01T08:00:00.006+08:00| 1|
|1970-01-01T08:00:00.008+08:00| 2|
+-----------------------------+-------------+
Query-Example - 4:
select count_time(*) from root.db.** group by([0, 10), 2ms) align by device
Result
+-----------------------------+----------+-------------+
| Time| Device|count_time(*)|
+-----------------------------+----------+-------------+
|1970-01-01T08:00:00.000+08:00|root.db.d1| 2|
|1970-01-01T08:00:00.002+08:00|root.db.d1| 1|
|1970-01-01T08:00:00.004+08:00|root.db.d1| 2|
|1970-01-01T08:00:00.006+08:00|root.db.d1| 1|
|1970-01-01T08:00:00.008+08:00|root.db.d1| 2|
|1970-01-01T08:00:00.000+08:00|root.db.d2| 2|
|1970-01-01T08:00:00.002+08:00|root.db.d2| 1|
|1970-01-01T08:00:00.004+08:00|root.db.d2| 2|
|1970-01-01T08:00:00.006+08:00|root.db.d2| 1|
|1970-01-01T08:00:00.008+08:00|root.db.d2| 1|
+-----------------------------+----------+-------------+
Note:
- The parameter in count_time can only be *.
- Count_time aggregation cannot be used with other aggregation functions.
- Count_time aggregation used with having statement is not supported, and count_time aggregation can not appear in the having statement.
- Count_time does not support use with group by level, group by tag.
String Processing
STRING_CONTAINS
Function introduction
This function checks whether the substring s exists in the string
Function name: STRING_CONTAINS
Input sequence: Only a single input sequence is supported, the type is TEXT.
parameter:
s: The string to search for.
Output Sequence: Output a single sequence, the type is BOOLEAN.
Usage example
select s1, string_contains(s1, 's'='warn') from root.sg1.d4;
+-----------------------------+--------------+-------------------------------------------+
| Time|root.sg1.d4.s1|string_contains(root.sg1.d4.s1, "s"="warn")|
+-----------------------------+--------------+-------------------------------------------+
|1970-01-01T08:00:00.001+08:00| warn:-8721| true|
|1970-01-01T08:00:00.002+08:00| error:-37229| false|
|1970-01-01T08:00:00.003+08:00| warn:1731| true|
+-----------------------------+--------------+-------------------------------------------+
Total line number = 3
It costs 0.007s
STRING_MATCHES
Function introduction
This function judges whether a string can be matched by the regular expression regex.
Function name: STRING_MATCHES
Input sequence: Only a single input sequence is supported, the type is TEXT.
parameter:
regex: Java standard library-style regular expressions.
Output Sequence: Output a single sequence, the type is BOOLEAN.
Usage example
select s1, string_matches(s1, 'regex'='[^\\s]+37229') from root.sg1.d4;
+-----------------------------+--------------+------------------------------------------------------+
| Time|root.sg1.d4.s1|string_matches(root.sg1.d4.s1, "regex"="[^\\s]+37229")|
+-----------------------------+--------------+------------------------------------------------------+
|1970-01-01T08:00:00.001+08:00| warn:-8721| false|
|1970-01-01T08:00:00.002+08:00| error:-37229| true|
|1970-01-01T08:00:00.003+08:00| warn:1731| false|
+-----------------------------+--------------+------------------------------------------------------+
Total line number = 3
It costs 0.007s
Length
Usage
The function is used to get the length of input series.
Name: LENGTH
Input Series: Only support a single input series. The data type is TEXT.
Output Series: Output a single series. The type is INT32.
Note: Returns NULL if input is NULL.
Examples
Input series:
+-----------------------------+--------------+
| Time|root.sg1.d1.s1|
+-----------------------------+--------------+
|1970-01-01T08:00:00.001+08:00| 1test1|
|1970-01-01T08:00:00.002+08:00| 22test22|
+-----------------------------+--------------+
SQL for query:
select s1, length(s1) from root.sg1.d1
Output series:
+-----------------------------+--------------+----------------------+
| Time|root.sg1.d1.s1|length(root.sg1.d1.s1)|
+-----------------------------+--------------+----------------------+
|1970-01-01T08:00:00.001+08:00| 1test1| 6|
|1970-01-01T08:00:00.002+08:00| 22test22| 8|
+-----------------------------+--------------+----------------------+
Locate
Usage
The function is used to get the position of the first occurrence of substring target in input series. Returns -1 if there are no target in input.
Name: LOCATE
Input Series: Only support a single input series. The data type is TEXT.
Parameter:
target: The substring to be located.reverse: Indicates whether reverse locate is required. The default value isfalse, means left-to-right locate.
Output Series: Output a single series. The type is INT32.
Note: The index begins from 0.
Examples
Input series:
+-----------------------------+--------------+
| Time|root.sg1.d1.s1|
+-----------------------------+--------------+
|1970-01-01T08:00:00.001+08:00| 1test1|
|1970-01-01T08:00:00.002+08:00| 22test22|
+-----------------------------+--------------+
SQL for query:
select s1, locate(s1, "target"="1") from root.sg1.d1
Output series:
+-----------------------------+--------------+------------------------------------+
| Time|root.sg1.d1.s1|locate(root.sg1.d1.s1, "target"="1")|
+-----------------------------+--------------+------------------------------------+
|1970-01-01T08:00:00.001+08:00| 1test1| 0|
|1970-01-01T08:00:00.002+08:00| 22test22| -1|
+-----------------------------+--------------+------------------------------------+
Another SQL for query:
select s1, locate(s1, "target"="1", "reverse"="true") from root.sg1.d1
Output series:
+-----------------------------+--------------+------------------------------------------------------+
| Time|root.sg1.d1.s1|locate(root.sg1.d1.s1, "target"="1", "reverse"="true")|
+-----------------------------+--------------+------------------------------------------------------+
|1970-01-01T08:00:00.001+08:00| 1test1| 5|
|1970-01-01T08:00:00.002+08:00| 22test22| -1|
+-----------------------------+--------------+------------------------------------------------------+
StartsWith
Usage
The function is used to check whether input series starts with the specified prefix.
Name: STARTSWITH
Input Series: Only support a single input series. The data type is TEXT.
Parameter:
target: The prefix to be checked.
Output Series: Output a single series. The type is BOOLEAN.
Note: Returns NULL if input is NULL.
Examples
Input series:
+-----------------------------+--------------+
| Time|root.sg1.d1.s1|
+-----------------------------+--------------+
|1970-01-01T08:00:00.001+08:00| 1test1|
|1970-01-01T08:00:00.002+08:00| 22test22|
+-----------------------------+--------------+
SQL for query:
select s1, startswith(s1, "target"="1") from root.sg1.d1
Output series:
+-----------------------------+--------------+----------------------------------------+
| Time|root.sg1.d1.s1|startswith(root.sg1.d1.s1, "target"="1")|
+-----------------------------+--------------+----------------------------------------+
|1970-01-01T08:00:00.001+08:00| 1test1| true|
|1970-01-01T08:00:00.002+08:00| 22test22| false|
+-----------------------------+--------------+----------------------------------------+
EndsWith
Usage
The function is used to check whether input series ends with the specified suffix.
Name: ENDSWITH
Input Series: Only support a single input series. The data type is TEXT.
Parameter:
target: The suffix to be checked.
Output Series: Output a single series. The type is BOOLEAN.
Note: Returns NULL if input is NULL.
Examples
Input series:
+-----------------------------+--------------+
| Time|root.sg1.d1.s1|
+-----------------------------+--------------+
|1970-01-01T08:00:00.001+08:00| 1test1|
|1970-01-01T08:00:00.002+08:00| 22test22|
+-----------------------------+--------------+
SQL for query:
select s1, endswith(s1, "target"="1") from root.sg1.d1
Output series:
+-----------------------------+--------------+--------------------------------------+
| Time|root.sg1.d1.s1|endswith(root.sg1.d1.s1, "target"="1")|
+-----------------------------+--------------+--------------------------------------+
|1970-01-01T08:00:00.001+08:00| 1test1| true|
|1970-01-01T08:00:00.002+08:00| 22test22| false|
+-----------------------------+--------------+--------------------------------------+
Concat
Usage
The function is used to concat input series and target strings.
Name: CONCAT
Input Series: At least one input series. The data type is TEXT.
Parameter:
targets: A series of K-V, key needs to start withtargetand be not duplicated, value is the string you want to concat.series_behind: Indicates whether series behind targets. The default value isfalse.
Output Series: Output a single series. The type is TEXT.
Note:
- If value of input series is NULL, it will be skipped.
- We can only concat input series and
targetsseparately.concat(s1, "target1"="IoT", s2, "target2"="DB")andconcat(s1, s2, "target1"="IoT", "target2"="DB")gives the same result.
Examples
Input series:
+-----------------------------+--------------+--------------+
| Time|root.sg1.d1.s1|root.sg1.d1.s2|
+-----------------------------+--------------+--------------+
|1970-01-01T08:00:00.001+08:00| 1test1| null|
|1970-01-01T08:00:00.002+08:00| 22test22| 2222test|
+-----------------------------+--------------+--------------+
SQL for query:
select s1, s2, concat(s1, s2, "target1"="IoT", "target2"="DB") from root.sg1.d1
Output series:
+-----------------------------+--------------+--------------+-----------------------------------------------------------------------+
| Time|root.sg1.d1.s1|root.sg1.d1.s2|concat(root.sg1.d1.s1, root.sg1.d1.s2, "target1"="IoT", "target2"="DB")|
+-----------------------------+--------------+--------------+-----------------------------------------------------------------------+
|1970-01-01T08:00:00.001+08:00| 1test1| null| 1test1IoTDB|
|1970-01-01T08:00:00.002+08:00| 22test22| 2222test| 22test222222testIoTDB|
+-----------------------------+--------------+--------------+-----------------------------------------------------------------------+
Another SQL for query:
select s1, s2, concat(s1, s2, "target1"="IoT", "target2"="DB", "series_behind"="true") from root.sg1.d1
Output series:
+-----------------------------+--------------+--------------+-----------------------------------------------------------------------------------------------+
| Time|root.sg1.d1.s1|root.sg1.d1.s2|concat(root.sg1.d1.s1, root.sg1.d1.s2, "target1"="IoT", "target2"="DB", "series_behind"="true")|
+-----------------------------+--------------+--------------+-----------------------------------------------------------------------------------------------+
|1970-01-01T08:00:00.001+08:00| 1test1| null| IoTDB1test1|
|1970-01-01T08:00:00.002+08:00| 22test22| 2222test| IoTDB22test222222test|
+-----------------------------+--------------+--------------+-----------------------------------------------------------------------------------------------+
substring
Usage
Extracts a substring of a string, starting with the first specified character and stopping after the specified number of characters.The index start at 1. The value range of from and for is an INT32.
Name: SUBSTRING
Input Series: Only support a single input series. The data type is TEXT.
Parameter:
from: Indicates the start position of substring.for: Indicates how many characters to stop after of substring.
Output Series: Output a single series. The type is TEXT.
Note: Returns NULL if input is NULL.
Examples
Input series:
+-----------------------------+--------------+
| Time|root.sg1.d1.s1|
+-----------------------------+--------------+
|1970-01-01T08:00:00.001+08:00| 1test1|
|1970-01-01T08:00:00.002+08:00| 22test22|
+-----------------------------+--------------+
SQL for query:
select s1, substring(s1 from 1 for 2) from root.sg1.d1
Output series:
+-----------------------------+--------------+--------------------------------------+
| Time|root.sg1.d1.s1|SUBSTRING(root.sg1.d1.s1 FROM 1 FOR 2)|
+-----------------------------+--------------+--------------------------------------+
|1970-01-01T08:00:00.001+08:00| 1test1| 1t|
|1970-01-01T08:00:00.002+08:00| 22test22| 22|
+-----------------------------+--------------+--------------------------------------+
replace
Usage
Replace a substring in the input sequence with the target substring.
Name: REPLACE
Input Series: Only support a single input series. The data type is TEXT.
Parameter:
- first parameter: The target substring to be replaced.
- second parameter: The substring to replace with.
Output Series: Output a single series. The type is TEXT.
Note: Returns NULL if input is NULL.
Examples
Input series:
+-----------------------------+--------------+
| Time|root.sg1.d1.s1|
+-----------------------------+--------------+
|1970-01-01T08:00:00.001+08:00| 1test1|
|1970-01-01T08:00:00.002+08:00| 22test22|
+-----------------------------+--------------+
SQL for query:
select s1, replace(s1, 'es', 'tt') from root.sg1.d1
Output series:
+-----------------------------+--------------+-----------------------------------+
| Time|root.sg1.d1.s1|REPLACE(root.sg1.d1.s1, 'es', 'tt')|
+-----------------------------+--------------+-----------------------------------+
|1970-01-01T08:00:00.001+08:00| 1test1| 1tttt1|
|1970-01-01T08:00:00.002+08:00| 22test22| 22tttt22|
+-----------------------------+--------------+-----------------------------------+
Upper
Usage
The function is used to get the string of input series with all characters changed to uppercase.
Name: UPPER
Input Series: Only support a single input series. The data type is TEXT.
Output Series: Output a single series. The type is TEXT.
Note: Returns NULL if input is NULL.
Examples
Input series:
+-----------------------------+--------------+
| Time|root.sg1.d1.s1|
+-----------------------------+--------------+
|1970-01-01T08:00:00.001+08:00| 1test1|
|1970-01-01T08:00:00.002+08:00| 22test22|
+-----------------------------+--------------+
SQL for query:
select s1, upper(s1) from root.sg1.d1
Output series:
+-----------------------------+--------------+---------------------+
| Time|root.sg1.d1.s1|upper(root.sg1.d1.s1)|
+-----------------------------+--------------+---------------------+
|1970-01-01T08:00:00.001+08:00| 1test1| 1TEST1|
|1970-01-01T08:00:00.002+08:00| 22test22| 22TEST22|
+-----------------------------+--------------+---------------------+
Lower
Usage
The function is used to get the string of input series with all characters changed to lowercase.
Name: LOWER
Input Series: Only support a single input series. The data type is TEXT.
Output Series: Output a single series. The type is TEXT.
Note: Returns NULL if input is NULL.
Examples
Input series:
+-----------------------------+--------------+
| Time|root.sg1.d1.s1|
+-----------------------------+--------------+
|1970-01-01T08:00:00.001+08:00| 1TEST1|
|1970-01-01T08:00:00.002+08:00| 22TEST22|
+-----------------------------+--------------+
SQL for query:
select s1, lower(s1) from root.sg1.d1
Output series:
+-----------------------------+--------------+---------------------+
| Time|root.sg1.d1.s1|lower(root.sg1.d1.s1)|
+-----------------------------+--------------+---------------------+
|1970-01-01T08:00:00.001+08:00| 1TEST1| 1test1|
|1970-01-01T08:00:00.002+08:00| 22TEST22| 22test22|
+-----------------------------+--------------+---------------------+
Trim
Usage
The function is used to get the string whose value is same to input series, with all leading and trailing space removed.
Name: TRIM
Input Series: Only support a single input series. The data type is TEXT.
Output Series: Output a single series. The type is TEXT.
Note: Returns NULL if input is NULL.
Examples
Input series:
+-----------------------------+--------------+
| Time|root.sg1.d1.s3|
+-----------------------------+--------------+
|1970-01-01T08:00:00.002+08:00| 3querytest3|
|1970-01-01T08:00:00.003+08:00| 3querytest3 |
+-----------------------------+--------------+
SQL for query:
select s3, trim(s3) from root.sg1.d1
Output series:
+-----------------------------+--------------+--------------------+
| Time|root.sg1.d1.s3|trim(root.sg1.d1.s3)|
+-----------------------------+--------------+--------------------+
|1970-01-01T08:00:00.002+08:00| 3querytest3| 3querytest3|
|1970-01-01T08:00:00.003+08:00| 3querytest3 | 3querytest3|
+-----------------------------+--------------+--------------------+
StrCmp
Usage
The function is used to get the compare result of two input series. Returns 0 if series value are the same, a negative integer if value of series1 is smaller than series2,
a positive integer if value of series1 is more than series2.
Name: StrCmp
Input Series: Support two input series. Data types are all the TEXT.
Output Series: Output a single series. The type is INT32.
Note: Returns NULL either series value is NULL.
Examples
Input series:
+-----------------------------+--------------+--------------+
| Time|root.sg1.d1.s1|root.sg1.d1.s2|
+-----------------------------+--------------+--------------+
|1970-01-01T08:00:00.001+08:00| 1test1| null|
|1970-01-01T08:00:00.002+08:00| 22test22| 2222test|
+-----------------------------+--------------+--------------+
SQL for query:
select s1, s2, strcmp(s1, s2) from root.sg1.d1
Output series:
+-----------------------------+--------------+--------------+--------------------------------------+
| Time|root.sg1.d1.s1|root.sg1.d1.s2|strcmp(root.sg1.d1.s1, root.sg1.d1.s2)|
+-----------------------------+--------------+--------------+--------------------------------------+
|1970-01-01T08:00:00.001+08:00| 1test1| null| null|
|1970-01-01T08:00:00.002+08:00| 22test22| 2222test| 66|
+-----------------------------+--------------+--------------+--------------------------------------+
StrReplace
Usage
This is not a built-in function and can only be used after registering the library-udf. The function is used to replace the specific substring with given string.
Name: STRREPLACE
Input Series: Only support a single input series. The data type is TEXT.
Parameter:
target: The target substring to be replaced.replace: The string to be put on.limit: The number of matches to be replaced which should be an integer no less than -1,
default to -1 which means all matches will be replaced.offset: The number of matches to be skipped, which means the firstoffsetmatches will not be replaced, default to 0.reverse: Whether to count all the matches reversely, default to 'false'.
Output Series: Output a single series. The type is TEXT.
Examples
Input series:
+-----------------------------+---------------+
| Time|root.test.d1.s1|
+-----------------------------+---------------+
|2021-01-01T00:00:01.000+08:00| A,B,A+,B-|
|2021-01-01T00:00:02.000+08:00| A,A+,A,B+|
|2021-01-01T00:00:03.000+08:00| B+,B,B|
|2021-01-01T00:00:04.000+08:00| A+,A,A+,A|
|2021-01-01T00:00:05.000+08:00| A,B-,B,B|
+-----------------------------+---------------+
SQL for query:
select strreplace(s1, "target"=",", "replace"="/", "limit"="2") from root.test.d1
Output series:
+-----------------------------+-----------------------------------------+
| Time|strreplace(root.test.d1.s1, "target"=",",|
| | "replace"="/", "limit"="2")|
+-----------------------------+-----------------------------------------+
|2021-01-01T00:00:01.000+08:00| A/B/A+,B-|
|2021-01-01T00:00:02.000+08:00| A/A+/A,B+|
|2021-01-01T00:00:03.000+08:00| B+/B/B|
|2021-01-01T00:00:04.000+08:00| A+/A/A+,A|
|2021-01-01T00:00:05.000+08:00| A/B-/B,B|
+-----------------------------+-----------------------------------------+
Another SQL for query:
select strreplace(s1, "target"=",", "replace"="/", "limit"="1", "offset"="1", "reverse"="true") from root.test.d1
Output series:
+-----------------------------+-----------------------------------------------------+
| Time|strreplace(root.test.d1.s1, "target"=",", "replace"= |
| | "|", "limit"="1", "offset"="1", "reverse"="true")|
+-----------------------------+-----------------------------------------------------+
|2021-01-01T00:00:01.000+08:00| A,B/A+,B-|
|2021-01-01T00:00:02.000+08:00| A,A+/A,B+|
|2021-01-01T00:00:03.000+08:00| B+/B,B|
|2021-01-01T00:00:04.000+08:00| A+,A/A+,A|
|2021-01-01T00:00:05.000+08:00| A,B-/B,B|
+-----------------------------+-----------------------------------------------------+
RegexMatch
Usage
This is not a built-in function and can only be used after registering the library-udf. The function is used to fetch matched contents from text with given regular expression.
Name: REGEXMATCH
Input Series: Only support a single input series. The data type is TEXT.
Parameter:
regex: The regular expression to match in the text. All grammars supported by Java are acceptable,
for example,\d+\.\d+\.\d+\.\d+is expected to match any IPv4 addresses.group: The wanted group index in the matched result.
Reference to java.util.regex, group 0 is the whole pattern and
the next ones are numbered with the appearance order of left parentheses.
For example, the groups inA(B(CD))are: 0-A(B(CD)), 1-B(CD), 2-CD.
Output Series: Output a single series. The type is TEXT.
Note: Those points with null values or not matched with the given pattern will not return any results.
Examples
Input series:
+-----------------------------+-------------------------------+
| Time| root.test.d1.s1|
+-----------------------------+-------------------------------+
|2021-01-01T00:00:01.000+08:00| [192.168.0.1] [SUCCESS]|
|2021-01-01T00:00:02.000+08:00| [192.168.0.24] [SUCCESS]|
|2021-01-01T00:00:03.000+08:00| [192.168.0.2] [FAIL]|
|2021-01-01T00:00:04.000+08:00| [192.168.0.5] [SUCCESS]|
|2021-01-01T00:00:05.000+08:00| [192.168.0.124] [SUCCESS]|
+-----------------------------+-------------------------------+
SQL for query:
select regexmatch(s1, "regex"="\d+\.\d+\.\d+\.\d+", "group"="0") from root.test.d1
Output series:
+-----------------------------+----------------------------------------------------------------------+
| Time|regexmatch(root.test.d1.s1, "regex"="\d+\.\d+\.\d+\.\d+", "group"="0")|
+-----------------------------+----------------------------------------------------------------------+
|2021-01-01T00:00:01.000+08:00| 192.168.0.1|
|2021-01-01T00:00:02.000+08:00| 192.168.0.24|
|2021-01-01T00:00:03.000+08:00| 192.168.0.2|
|2021-01-01T00:00:04.000+08:00| 192.168.0.5|
|2021-01-01T00:00:05.000+08:00| 192.168.0.124|
+-----------------------------+----------------------------------------------------------------------+
RegexReplace
Usage
This is not a built-in function and can only be used after registering the library-udf. The function is used to replace the specific regular expression matches with given string.
Name: REGEXREPLACE
Input Series: Only support a single input series. The data type is TEXT.
Parameter:
regex: The target regular expression to be replaced. All grammars supported by Java are acceptable.replace: The string to be put on and back reference notes in Java is also supported,
for example, '$1' refers to group 1 in theregexwhich will be filled with corresponding matched results.limit: The number of matches to be replaced which should be an integer no less than -1,
default to -1 which means all matches will be replaced.offset: The number of matches to be skipped, which means the firstoffsetmatches will not be replaced, default to 0.reverse: Whether to count all the matches reversely, default to 'false'.
Output Series: Output a single series. The type is TEXT.
Examples
Input series:
+-----------------------------+-------------------------------+
| Time| root.test.d1.s1|
+-----------------------------+-------------------------------+
|2021-01-01T00:00:01.000+08:00| [192.168.0.1] [SUCCESS]|
|2021-01-01T00:00:02.000+08:00| [192.168.0.24] [SUCCESS]|
|2021-01-01T00:00:03.000+08:00| [192.168.0.2] [FAIL]|
|2021-01-01T00:00:04.000+08:00| [192.168.0.5] [SUCCESS]|
|2021-01-01T00:00:05.000+08:00| [192.168.0.124] [SUCCESS]|
+-----------------------------+-------------------------------+
SQL for query:
select regexreplace(s1, "regex"="192\.168\.0\.(\d+)", "replace"="cluster-$1", "limit"="1") from root.test.d1
Output series:
+-----------------------------+-----------------------------------------------------------+
| Time|regexreplace(root.test.d1.s1, "regex"="192\.168\.0\.(\d+)",|
| | "replace"="cluster-$1", "limit"="1")|
+-----------------------------+-----------------------------------------------------------+
|2021-01-01T00:00:01.000+08:00| [cluster-1] [SUCCESS]|
|2021-01-01T00:00:02.000+08:00| [cluster-24] [SUCCESS]|
|2021-01-01T00:00:03.000+08:00| [cluster-2] [FAIL]|
|2021-01-01T00:00:04.000+08:00| [cluster-5] [SUCCESS]|
|2021-01-01T00:00:05.000+08:00| [cluster-124] [SUCCESS]|
+-----------------------------+-----------------------------------------------------------+
RegexSplit
Usage
This is not a built-in function and can only be used after registering the library-udf. The function is used to split text with given regular expression and return specific element.
Name: REGEXSPLIT
Input Series: Only support a single input series. The data type is TEXT.
Parameter:
regex: The regular expression used to split the text.
All grammars supported by Java are acceptable, for example,['"]is expected to match'and".index: The wanted index of elements in the split result.
It should be an integer no less than -1, default to -1 which means the length of the result array is returned
and any non-negative integer is used to fetch the text of the specific index starting from 0.
Output Series: Output a single series. The type is INT32 when index is -1 and TEXT when it's an valid index.
Note: When index is out of the range of the result array, for example 0,1,2 split with , and index is set to 3,
no result are returned for that record.
Examples
Input series:
+-----------------------------+---------------+
| Time|root.test.d1.s1|
+-----------------------------+---------------+
|2021-01-01T00:00:01.000+08:00| A,B,A+,B-|
|2021-01-01T00:00:02.000+08:00| A,A+,A,B+|
|2021-01-01T00:00:03.000+08:00| B+,B,B|
|2021-01-01T00:00:04.000+08:00| A+,A,A+,A|
|2021-01-01T00:00:05.000+08:00| A,B-,B,B|
+-----------------------------+---------------+
SQL for query:
select regexsplit(s1, "regex"=",", "index"="-1") from root.test.d1
Output series:
+-----------------------------+------------------------------------------------------+
| Time|regexsplit(root.test.d1.s1, "regex"=",", "index"="-1")|
+-----------------------------+------------------------------------------------------+
|2021-01-01T00:00:01.000+08:00| 4|
|2021-01-01T00:00:02.000+08:00| 4|
|2021-01-01T00:00:03.000+08:00| 3|
|2021-01-01T00:00:04.000+08:00| 4|
|2021-01-01T00:00:05.000+08:00| 4|
+-----------------------------+------------------------------------------------------+
Another SQL for query:
SQL for query:
select regexsplit(s1, "regex"=",", "index"="3") from root.test.d1
Output series:
+-----------------------------+-----------------------------------------------------+
| Time|regexsplit(root.test.d1.s1, "regex"=",", "index"="3")|
+-----------------------------+-----------------------------------------------------+
|2021-01-01T00:00:01.000+08:00| B-|
|2021-01-01T00:00:02.000+08:00| B+|
|2021-01-01T00:00:04.000+08:00| A|
|2021-01-01T00:00:05.000+08:00| B|
+-----------------------------+-----------------------------------------------------+
Data Type Conversion Function
The IoTDB currently supports 6 data types, including INT32, INT64 ,FLOAT, DOUBLE, BOOLEAN, TEXT. When we query or evaluate data, we may need to convert data types, such as TEXT to INT32, or FLOAT to DOUBLE. IoTDB supports cast function to convert data types.
Syntax example:
SELECT cast(s1 as INT32) from root.sg
The syntax of the cast function is consistent with that of PostgreSQL. The data type specified after AS indicates the target type to be converted. Currently, all six data types supported by IoTDB can be used in the cast function. The conversion rules to be followed are shown in the following table. The row represents the original data type, and the column represents the target data type to be converted into:
| INT32 | INT64 | FLOAT | DOUBLE | BOOLEAN | TEXT | |
|---|---|---|---|---|---|---|
| INT32 | No need to cast | Cast directly | Cast directly | Cast directly | !=0 : true ==0: false | String.valueOf() |
| INT64 | Out of the range of INT32: throw Exception Otherwise: Cast directly | No need to cast | Cast directly | Cast directly | !=0L : true ==0: false | String.valueOf() |
| FLOAT | Out of the range of INT32: throw Exception Otherwise: Math.round() | Out of the range of INT64: throw Exception Otherwise: Math.round() | No need to cast | Cast directly | !=0.0f : true ==0: false | String.valueOf() |
| DOUBLE | Out of the range of INT32: throw Exception Otherwise: Math.round() | Out of the range of INT64: throw Exception Otherwise: Math.round() | Out of the range of FLOAT:throw Exception Otherwise: Cast directly | No need to cast | !=0.0 : true ==0: false | String.valueOf() |
| BOOLEAN | true: 1 false: 0 | true: 1L false: 0 | true: 1.0f false: 0 | true: 1.0 false: 0 | No need to cast | true: "true" false: "false" |
| TEXT | Integer.parseInt() | Long.parseLong() | Float.parseFloat() | Double.parseDouble() | text.toLowerCase =="true" : true text.toLowerCase =="false" : false Otherwise: throw Exception | No need to cast |
Examples
// timeseries
IoTDB> show timeseries root.sg.d1.**
+-------------+-----+--------+--------+--------+-----------+----+----------+--------+------------------+
| Timeseries|Alias|Database|DataType|Encoding|Compression|Tags|Attributes|Deadband|DeadbandParameters|
+-------------+-----+--------+--------+--------+-----------+----+----------+--------+------------------+
|root.sg.d1.s3| null| root.sg| FLOAT| PLAIN| SNAPPY|null| null| null| null|
|root.sg.d1.s4| null| root.sg| DOUBLE| PLAIN| SNAPPY|null| null| null| null|
|root.sg.d1.s5| null| root.sg| BOOLEAN| PLAIN| SNAPPY|null| null| null| null|
|root.sg.d1.s6| null| root.sg| TEXT| PLAIN| SNAPPY|null| null| null| null|
|root.sg.d1.s1| null| root.sg| INT32| PLAIN| SNAPPY|null| null| null| null|
|root.sg.d1.s2| null| root.sg| INT64| PLAIN| SNAPPY|null| null| null| null|
+-------------+-----+--------+--------+--------+-----------+----+----------+--------+------------------+
// data of timeseries
IoTDB> select * from root.sg.d1;
+-----------------------------+-------------+-------------+-------------+-------------+-------------+-------------+
| Time|root.sg.d1.s3|root.sg.d1.s4|root.sg.d1.s5|root.sg.d1.s6|root.sg.d1.s1|root.sg.d1.s2|
+-----------------------------+-------------+-------------+-------------+-------------+-------------+-------------+
|1970-01-01T08:00:00.000+08:00| 0.0| 0.0| false| 10000| 0| 0|
|1970-01-01T08:00:00.001+08:00| 1.0| 1.0| false| 3| 1| 1|
|1970-01-01T08:00:00.002+08:00| 2.7| 2.7| true| TRue| 2| 2|
|1970-01-01T08:00:00.003+08:00| 3.33| 3.33| true| faLse| 3| 3|
+-----------------------------+-------------+-------------+-------------+-------------+-------------+-------------+
// cast BOOLEAN to other types
IoTDB> select cast(s5 as INT32), cast(s5 as INT64),cast(s5 as FLOAT),cast(s5 as DOUBLE), cast(s5 as TEXT) from root.sg.d1
+-----------------------------+----------------------------+----------------------------+----------------------------+-----------------------------+---------------------------+
| Time|CAST(root.sg.d1.s5 AS INT32)|CAST(root.sg.d1.s5 AS INT64)|CAST(root.sg.d1.s5 AS FLOAT)|CAST(root.sg.d1.s5 AS DOUBLE)|CAST(root.sg.d1.s5 AS TEXT)|
+-----------------------------+----------------------------+----------------------------+----------------------------+-----------------------------+---------------------------+
|1970-01-01T08:00:00.000+08:00| 0| 0| 0.0| 0.0| false|
|1970-01-01T08:00:00.001+08:00| 0| 0| 0.0| 0.0| false|
|1970-01-01T08:00:00.002+08:00| 1| 1| 1.0| 1.0| true|
|1970-01-01T08:00:00.003+08:00| 1| 1| 1.0| 1.0| true|
+-----------------------------+----------------------------+----------------------------+----------------------------+-----------------------------+---------------------------+
// cast TEXT to numeric types
IoTDB> select cast(s6 as INT32), cast(s6 as INT64), cast(s6 as FLOAT), cast(s6 as DOUBLE) from root.sg.d1 where time < 2
+-----------------------------+----------------------------+----------------------------+----------------------------+-----------------------------+
| Time|CAST(root.sg.d1.s6 AS INT32)|CAST(root.sg.d1.s6 AS INT64)|CAST(root.sg.d1.s6 AS FLOAT)|CAST(root.sg.d1.s6 AS DOUBLE)|
+-----------------------------+----------------------------+----------------------------+----------------------------+-----------------------------+
|1970-01-01T08:00:00.000+08:00| 10000| 10000| 10000.0| 10000.0|
|1970-01-01T08:00:00.001+08:00| 3| 3| 3.0| 3.0|
+-----------------------------+----------------------------+----------------------------+----------------------------+-----------------------------+
// cast TEXT to BOOLEAN
IoTDB> select cast(s6 as BOOLEAN) from root.sg.d1 where time >= 2
+-----------------------------+------------------------------+
| Time|CAST(root.sg.d1.s6 AS BOOLEAN)|
+-----------------------------+------------------------------+
|1970-01-01T08:00:00.002+08:00| true|
|1970-01-01T08:00:00.003+08:00| false|
+-----------------------------+------------------------------+
Constant Timeseries Generating Functions
The constant timeseries generating function is used to generate a timeseries in which the values of all data points are the same.
The constant timeseries generating function accepts one or more timeseries inputs, and the timestamp set of the output data points is the union of the timestamp sets of the input timeseries.
Currently, IoTDB supports the following constant timeseries generating functions:
| Function Name | Required Attributes | Output Series Data Type | Description |
|---|---|---|---|
| CONST | value: the value of the output data point type: the type of the output data point, it can only be INT32 / INT64 / FLOAT / DOUBLE / BOOLEAN / TEXT | Determined by the required attribute type | Output the user-specified constant timeseries according to the attributes value and type. |
| PI | None | DOUBLE | Data point value: a double value of π, the ratio of the circumference of a circle to its diameter, which is equals to Math.PI in the Java Standard Library. |
| E | None | DOUBLE | Data point value: a double value of e, the base of the natural logarithms, which is equals to Math.E in the Java Standard Library. |
Example:
select s1, s2, const(s1, 'value'='1024', 'type'='INT64'), pi(s2), e(s1, s2) from root.sg1.d1;
Result:
select s1, s2, const(s1, 'value'='1024', 'type'='INT64'), pi(s2), e(s1, s2) from root.sg1.d1;
+-----------------------------+--------------+--------------+-----------------------------------------------------+------------------+---------------------------------+
| Time|root.sg1.d1.s1|root.sg1.d1.s2|const(root.sg1.d1.s1, "value"="1024", "type"="INT64")|pi(root.sg1.d1.s2)|e(root.sg1.d1.s1, root.sg1.d1.s2)|
+-----------------------------+--------------+--------------+-----------------------------------------------------+------------------+---------------------------------+
|1970-01-01T08:00:00.000+08:00| 0.0| 0.0| 1024| 3.141592653589793| 2.718281828459045|
|1970-01-01T08:00:00.001+08:00| 1.0| null| 1024| null| 2.718281828459045|
|1970-01-01T08:00:00.002+08:00| 2.0| null| 1024| null| 2.718281828459045|
|1970-01-01T08:00:00.003+08:00| null| 3.0| null| 3.141592653589793| 2.718281828459045|
|1970-01-01T08:00:00.004+08:00| null| 4.0| null| 3.141592653589793| 2.718281828459045|
+-----------------------------+--------------+--------------+-----------------------------------------------------+------------------+---------------------------------+
Total line number = 5
It costs 0.005s
Selector Functions
Currently, IoTDB supports the following selector functions:
| Function Name | Allowed Input Series Data Types | Required Attributes | Output Series Data Type | Description |
|---|---|---|---|---|
| TOP_K | INT32 / INT64 / FLOAT / DOUBLE / TEXT | k: the maximum number of selected data points, must be greater than 0 and less than or equal to 1000 | Same type as the input series | Returns k data points with the largest values in a time series. |
| BOTTOM_K | INT32 / INT64 / FLOAT / DOUBLE / TEXT | k: the maximum number of selected data points, must be greater than 0 and less than or equal to 1000 | Same type as the input series | Returns k data points with the smallest values in a time series. |
Example:
select s1, top_k(s1, 'k'='2'), bottom_k(s1, 'k'='2') from root.sg1.d2 where time > 2020-12-10T20:36:15.530+08:00;
Result:
+-----------------------------+--------------------+------------------------------+---------------------------------+
| Time| root.sg1.d2.s1|top_k(root.sg1.d2.s1, "k"="2")|bottom_k(root.sg1.d2.s1, "k"="2")|
+-----------------------------+--------------------+------------------------------+---------------------------------+
|2020-12-10T20:36:15.531+08:00| 1531604122307244742| 1531604122307244742| null|
|2020-12-10T20:36:15.532+08:00|-7426070874923281101| null| null|
|2020-12-10T20:36:15.533+08:00|-7162825364312197604| -7162825364312197604| null|
|2020-12-10T20:36:15.534+08:00|-8581625725655917595| null| -8581625725655917595|
|2020-12-10T20:36:15.535+08:00|-7667364751255535391| null| -7667364751255535391|
+-----------------------------+--------------------+------------------------------+---------------------------------+
Total line number = 5
It costs 0.006s
Continuous Interval Functions
The continuous interval functions are used to query all continuous intervals that meet specified conditions.
They can be divided into two categories according to return value:
- Returns the start timestamp and time span of the continuous interval that meets the conditions (a time span of 0 means that only the start time point meets the conditions)
- Returns the start timestamp of the continuous interval that meets the condition and the number of points in the interval (a number of 1 means that only the start time point meets the conditions)
| Function Name | Allowed Input Series Data Types | Required Attributes | Output Series Data Type | Description |
|---|---|---|---|---|
| ZERO_DURATION | INT32/ INT64/ FLOAT/ DOUBLE/ BOOLEAN | min:Optional with default value 0Lmax:Optional with default value Long.MAX_VALUE | Long | Return intervals' start times and duration times in which the value is always 0(false), and the duration time t satisfy t >= min && t <= max. The unit of t is ms |
| NON_ZERO_DURATION | INT32/ INT64/ FLOAT/ DOUBLE/ BOOLEAN | min:Optional with default value 0Lmax:Optional with default value Long.MAX_VALUE | Long | Return intervals' start times and duration times in which the value is always not 0, and the duration time t satisfy t >= min && t <= max. The unit of t is ms |
| ZERO_COUNT | INT32/ INT64/ FLOAT/ DOUBLE/ BOOLEAN | min:Optional with default value 1Lmax:Optional with default value Long.MAX_VALUE | Long | Return intervals' start times and the number of data points in the interval in which the value is always 0(false). Data points number n satisfy n >= min && n <= max |
| NON_ZERO_COUNT | INT32/ INT64/ FLOAT/ DOUBLE/ BOOLEAN | min:Optional with default value 1Lmax:Optional with default value Long.MAX_VALUE | Long | Return intervals' start times and the number of data points in the interval in which the value is always not 0(false). Data points number n satisfy n >= min && n <= max |
Demonstrate
Example data:
IoTDB> select s1,s2,s3,s4,s5 from root.sg.d2;
+-----------------------------+-------------+-------------+-------------+-------------+-------------+
| Time|root.sg.d2.s1|root.sg.d2.s2|root.sg.d2.s3|root.sg.d2.s4|root.sg.d2.s5|
+-----------------------------+-------------+-------------+-------------+-------------+-------------+
|1970-01-01T08:00:00.000+08:00| 0| 0| 0.0| 0.0| false|
|1970-01-01T08:00:00.001+08:00| 1| 1| 1.0| 1.0| true|
|1970-01-01T08:00:00.002+08:00| 1| 1| 1.0| 1.0| true|
|1970-01-01T08:00:00.003+08:00| 0| 0| 0.0| 0.0| false|
|1970-01-01T08:00:00.004+08:00| 1| 1| 1.0| 1.0| true|
|1970-01-01T08:00:00.005+08:00| 0| 0| 0.0| 0.0| false|
|1970-01-01T08:00:00.006+08:00| 0| 0| 0.0| 0.0| false|
|1970-01-01T08:00:00.007+08:00| 1| 1| 1.0| 1.0| true|
+-----------------------------+-------------+-------------+-------------+-------------+-------------+
Sql:
select s1, zero_count(s1), non_zero_count(s2), zero_duration(s3), non_zero_duration(s4) from root.sg.d2;
Result:
+-----------------------------+-------------+-------------------------+-----------------------------+----------------------------+--------------------------------+
| Time|root.sg.d2.s1|zero_count(root.sg.d2.s1)|non_zero_count(root.sg.d2.s2)|zero_duration(root.sg.d2.s3)|non_zero_duration(root.sg.d2.s4)|
+-----------------------------+-------------+-------------------------+-----------------------------+----------------------------+--------------------------------+
|1970-01-01T08:00:00.000+08:00| 0| 1| null| 0| null|
|1970-01-01T08:00:00.001+08:00| 1| null| 2| null| 1|
|1970-01-01T08:00:00.002+08:00| 1| null| null| null| null|
|1970-01-01T08:00:00.003+08:00| 0| 1| null| 0| null|
|1970-01-01T08:00:00.004+08:00| 1| null| 1| null| 0|
|1970-01-01T08:00:00.005+08:00| 0| 2| null| 1| null|
|1970-01-01T08:00:00.006+08:00| 0| null| null| null| null|
|1970-01-01T08:00:00.007+08:00| 1| null| 1| null| 0|
+-----------------------------+-------------+-------------------------+-----------------------------+----------------------------+--------------------------------+
Variation Trend Calculation Functions
Currently, IoTDB supports the following variation trend calculation functions:
| Function Name | Allowed Input Series Data Types | Required Attributes | Output Series Data Type | Description |
|---|---|---|---|---|
| TIME_DIFFERENCE | INT32 / INT64 / FLOAT / DOUBLE / BOOLEAN / TEXT | / | INT64 | Calculates the difference between the time stamp of a data point and the time stamp of the previous data point. There is no corresponding output for the first data point. |
| DIFFERENCE | INT32 / INT64 / FLOAT / DOUBLE | / | Same type as the input series | Calculates the difference between the value of a data point and the value of the previous data point. There is no corresponding output for the first data point. |
| NON_NEGATIVE_DIFFERENCE | INT32 / INT64 / FLOAT / DOUBLE | / | Same type as the input series | Calculates the absolute value of the difference between the value of a data point and the value of the previous data point. There is no corresponding output for the first data point. |
| DERIVATIVE | INT32 / INT64 / FLOAT / DOUBLE | / | DOUBLE | Calculates the rate of change of a data point compared to the previous data point, the result is equals to DIFFERENCE / TIME_DIFFERENCE. There is no corresponding output for the first data point. |
| NON_NEGATIVE_DERIVATIVE | INT32 / INT64 / FLOAT / DOUBLE | / | DOUBLE | Calculates the absolute value of the rate of change of a data point compared to the previous data point, the result is equals to NON_NEGATIVE_DIFFERENCE / TIME_DIFFERENCE. There is no corresponding output for the first data point. |
| DIFF | INT32 / INT64 / FLOAT / DOUBLE | ignoreNull:optional,default is true. If is true, the previous data point is ignored when it is null and continues to find the first non-null value forwardly. If the value is false, previous data point is not ignored when it is null, the result is also null because null is used for subtraction | DOUBLE | Calculates the difference between the value of a data point and the value of the previous data point. There is no corresponding output for the first data point, so output is null |
Example:
select s1, time_difference(s1), difference(s1), non_negative_difference(s1), derivative(s1), non_negative_derivative(s1) from root.sg1.d1 limit 5 offset 1000;
Result:
+-----------------------------+-------------------+-------------------------------+--------------------------+---------------------------------------+--------------------------+---------------------------------------+
| Time| root.sg1.d1.s1|time_difference(root.sg1.d1.s1)|difference(root.sg1.d1.s1)|non_negative_difference(root.sg1.d1.s1)|derivative(root.sg1.d1.s1)|non_negative_derivative(root.sg1.d1.s1)|
+-----------------------------+-------------------+-------------------------------+--------------------------+---------------------------------------+--------------------------+---------------------------------------+
|2020-12-10T17:11:49.037+08:00|7360723084922759782| 1| -8431715764844238876| 8431715764844238876| -8.4317157648442388E18| 8.4317157648442388E18|
|2020-12-10T17:11:49.038+08:00|4377791063319964531| 1| -2982932021602795251| 2982932021602795251| -2.982932021602795E18| 2.982932021602795E18|
|2020-12-10T17:11:49.039+08:00|7972485567734642915| 1| 3594694504414678384| 3594694504414678384| 3.5946945044146785E18| 3.5946945044146785E18|
|2020-12-10T17:11:49.040+08:00|2508858212791964081| 1| -5463627354942678834| 5463627354942678834| -5.463627354942679E18| 5.463627354942679E18|
|2020-12-10T17:11:49.041+08:00|2817297431185141819| 1| 308439218393177738| 308439218393177738| 3.0843921839317773E17| 3.0843921839317773E17|
+-----------------------------+-------------------+-------------------------------+--------------------------+---------------------------------------+--------------------------+---------------------------------------+
Total line number = 5
It costs 0.014s
Example
RawData
+-----------------------------+------------+------------+
| Time|root.test.s1|root.test.s2|
+-----------------------------+------------+------------+
|1970-01-01T08:00:00.001+08:00| 1| 1.0|
|1970-01-01T08:00:00.002+08:00| 2| null|
|1970-01-01T08:00:00.003+08:00| null| 3.0|
|1970-01-01T08:00:00.004+08:00| 4| null|
|1970-01-01T08:00:00.005+08:00| 5| 5.0|
|1970-01-01T08:00:00.006+08:00| null| 6.0|
+-----------------------------+------------+------------+
Not use ignoreNull attribute (Ignore Null)
SQL:
SELECT DIFF(s1), DIFF(s2) from root.test;
Result:
+-----------------------------+------------------+------------------+
| Time|DIFF(root.test.s1)|DIFF(root.test.s2)|
+-----------------------------+------------------+------------------+
|1970-01-01T08:00:00.001+08:00| null| null|
|1970-01-01T08:00:00.002+08:00| 1.0| null|
|1970-01-01T08:00:00.003+08:00| null| 2.0|
|1970-01-01T08:00:00.004+08:00| 2.0| null|
|1970-01-01T08:00:00.005+08:00| 1.0| 2.0|
|1970-01-01T08:00:00.006+08:00| null| 1.0|
+-----------------------------+------------------+------------------+
Use ignoreNull attribute
SQL:
SELECT DIFF(s1, 'ignoreNull'='false'), DIFF(s2, 'ignoreNull'='false') from root.test;
Result:
+-----------------------------+----------------------------------------+----------------------------------------+
| Time|DIFF(root.test.s1, "ignoreNull"="false")|DIFF(root.test.s2, "ignoreNull"="false")|
+-----------------------------+----------------------------------------+----------------------------------------+
|1970-01-01T08:00:00.001+08:00| null| null|
|1970-01-01T08:00:00.002+08:00| 1.0| null|
|1970-01-01T08:00:00.003+08:00| null| null|
|1970-01-01T08:00:00.004+08:00| null| null|
|1970-01-01T08:00:00.005+08:00| 1.0| null|
|1970-01-01T08:00:00.006+08:00| null| 1.0|
+-----------------------------+----------------------------------------+----------------------------------------+
Sample Functions
Equal Size Bucket Sample Function
This function samples the input sequence in equal size buckets, that is, according to the downsampling ratio and downsampling method given by the user, the input sequence is equally divided into several buckets according to a fixed number of points. Sampling by the given sampling method within each bucket.
proportion: sample ratio, the value range is(0, 1].
Equal Size Bucket Random Sample
Random sampling is performed on the equally divided buckets.
| Function Name | Allowed Input Series Data Types | Required Attributes | Output Series Data Type | Description |
|---|---|---|---|---|
| EQUAL_SIZE_BUCKET_RANDOM_SAMPLE | INT32 / INT64 / FLOAT / DOUBLE | proportion The value range is (0, 1], the default is 0.1 | INT32 / INT64 / FLOAT / DOUBLE | Returns a random sample of equal buckets that matches the sampling ratio |
Example
Example data: root.ln.wf01.wt01.temperature has a total of 100 ordered data from 0.0-99.0.
IoTDB> select temperature from root.ln.wf01.wt01;
+-----------------------------+-----------------------------+
| Time|root.ln.wf01.wt01.temperature|
+-----------------------------+-----------------------------+
|1970-01-01T08:00:00.000+08:00| 0.0|
|1970-01-01T08:00:00.001+08:00| 1.0|
|1970-01-01T08:00:00.002+08:00| 2.0|
|1970-01-01T08:00:00.003+08:00| 3.0|
|1970-01-01T08:00:00.004+08:00| 4.0|
|1970-01-01T08:00:00.005+08:00| 5.0|
|1970-01-01T08:00:00.006+08:00| 6.0|
|1970-01-01T08:00:00.007+08:00| 7.0|
|1970-01-01T08:00:00.008+08:00| 8.0|
|1970-01-01T08:00:00.009+08:00| 9.0|
|1970-01-01T08:00:00.010+08:00| 10.0|
|1970-01-01T08:00:00.011+08:00| 11.0|
|1970-01-01T08:00:00.012+08:00| 12.0|
|.............................|.............................|
|1970-01-01T08:00:00.089+08:00| 89.0|
|1970-01-01T08:00:00.090+08:00| 90.0|
|1970-01-01T08:00:00.091+08:00| 91.0|
|1970-01-01T08:00:00.092+08:00| 92.0|
|1970-01-01T08:00:00.093+08:00| 93.0|
|1970-01-01T08:00:00.094+08:00| 94.0|
|1970-01-01T08:00:00.095+08:00| 95.0|
|1970-01-01T08:00:00.096+08:00| 96.0|
|1970-01-01T08:00:00.097+08:00| 97.0|
|1970-01-01T08:00:00.098+08:00| 98.0|
|1970-01-01T08:00:00.099+08:00| 99.0|
+-----------------------------+-----------------------------+
Sql:
select equal_size_bucket_random_sample(temperature,'proportion'='0.1') as random_sample from root.ln.wf01.wt01;
Result:
+-----------------------------+-------------+
| Time|random_sample|
+-----------------------------+-------------+
|1970-01-01T08:00:00.007+08:00| 7.0|
|1970-01-01T08:00:00.014+08:00| 14.0|
|1970-01-01T08:00:00.020+08:00| 20.0|
|1970-01-01T08:00:00.035+08:00| 35.0|
|1970-01-01T08:00:00.047+08:00| 47.0|
|1970-01-01T08:00:00.059+08:00| 59.0|
|1970-01-01T08:00:00.063+08:00| 63.0|
|1970-01-01T08:00:00.079+08:00| 79.0|
|1970-01-01T08:00:00.086+08:00| 86.0|
|1970-01-01T08:00:00.096+08:00| 96.0|
+-----------------------------+-------------+
Total line number = 10
It costs 0.024s
Equal Size Bucket Aggregation Sample
The input sequence is sampled by the aggregation sampling method, and the user needs to provide an additional aggregation function parameter, namely
type: Aggregate type, which can beavgormaxorminorsumorextremeorvariance. By default,avgis used.extremerepresents the value with the largest absolute value in the equal bucket.variancerepresents the variance in the sampling equal buckets.
The timestamp of the sampling output of each bucket is the timestamp of the first point of the bucket.
| Function Name | Allowed Input Series Data Types | Required Attributes | Output Series Data Type | Description |
|---|---|---|---|---|
| EQUAL_SIZE_BUCKET_AGG_SAMPLE | INT32 / INT64 / FLOAT / DOUBLE | proportion The value range is (0, 1], the default is 0.1type: The value types are avg, max, min, sum, extreme, variance, the default is avg | INT32 / INT64 / FLOAT / DOUBLE | Returns equal bucket aggregation samples that match the sampling ratio |
Example
Example data: root.ln.wf01.wt01.temperature has a total of 100 ordered data from 0.0-99.0, and the test data is randomly sampled in equal buckets.
Sql:
select equal_size_bucket_agg_sample(temperature, 'type'='avg','proportion'='0.1') as agg_avg, equal_size_bucket_agg_sample(temperature, 'type'='max','proportion'='0.1') as agg_max, equal_size_bucket_agg_sample(temperature,'type'='min','proportion'='0.1') as agg_min, equal_size_bucket_agg_sample(temperature, 'type'='sum','proportion'='0.1') as agg_sum, equal_size_bucket_agg_sample(temperature, 'type'='extreme','proportion'='0.1') as agg_extreme, equal_size_bucket_agg_sample(temperature, 'type'='variance','proportion'='0.1') as agg_variance from root.ln.wf01.wt01;
Result:
+-----------------------------+-----------------+-------+-------+-------+-----------+------------+
| Time| agg_avg|agg_max|agg_min|agg_sum|agg_extreme|agg_variance|
+-----------------------------+-----------------+-------+-------+-------+-----------+------------+
|1970-01-01T08:00:00.000+08:00| 4.5| 9.0| 0.0| 45.0| 9.0| 8.25|
|1970-01-01T08:00:00.010+08:00| 14.5| 19.0| 10.0| 145.0| 19.0| 8.25|
|1970-01-01T08:00:00.020+08:00| 24.5| 29.0| 20.0| 245.0| 29.0| 8.25|
|1970-01-01T08:00:00.030+08:00| 34.5| 39.0| 30.0| 345.0| 39.0| 8.25|
|1970-01-01T08:00:00.040+08:00| 44.5| 49.0| 40.0| 445.0| 49.0| 8.25|
|1970-01-01T08:00:00.050+08:00| 54.5| 59.0| 50.0| 545.0| 59.0| 8.25|
|1970-01-01T08:00:00.060+08:00| 64.5| 69.0| 60.0| 645.0| 69.0| 8.25|
|1970-01-01T08:00:00.070+08:00|74.50000000000001| 79.0| 70.0| 745.0| 79.0| 8.25|
|1970-01-01T08:00:00.080+08:00| 84.5| 89.0| 80.0| 845.0| 89.0| 8.25|
|1970-01-01T08:00:00.090+08:00| 94.5| 99.0| 90.0| 945.0| 99.0| 8.25|
+-----------------------------+-----------------+-------+-------+-------+-----------+------------+
Total line number = 10
It costs 0.044s
Equal Size Bucket M4 Sample
The input sequence is sampled using the M4 sampling method. That is to sample the head, tail, min and max values for each bucket.
| Function Name | Allowed Input Series Data Types | Required Attributes | Output Series Data Type | Description |
|---|---|---|---|---|
| EQUAL_SIZE_BUCKET_M4_SAMPLE | INT32 / INT64 / FLOAT / DOUBLE | proportion The value range is (0, 1], the default is 0.1 | INT32 / INT64 / FLOAT / DOUBLE | Returns equal bucket M4 samples that match the sampling ratio |
Example
Example data: root.ln.wf01.wt01.temperature has a total of 100 ordered data from 0.0-99.0, and the test data is randomly sampled in equal buckets.
Sql:
select equal_size_bucket_m4_sample(temperature, 'proportion'='0.1') as M4_sample from root.ln.wf01.wt01;
Result:
+-----------------------------+---------+
| Time|M4_sample|
+-----------------------------+---------+
|1970-01-01T08:00:00.000+08:00| 0.0|
|1970-01-01T08:00:00.001+08:00| 1.0|
|1970-01-01T08:00:00.038+08:00| 38.0|
|1970-01-01T08:00:00.039+08:00| 39.0|
|1970-01-01T08:00:00.040+08:00| 40.0|
|1970-01-01T08:00:00.041+08:00| 41.0|
|1970-01-01T08:00:00.078+08:00| 78.0|
|1970-01-01T08:00:00.079+08:00| 79.0|
|1970-01-01T08:00:00.080+08:00| 80.0|
|1970-01-01T08:00:00.081+08:00| 81.0|
|1970-01-01T08:00:00.098+08:00| 98.0|
|1970-01-01T08:00:00.099+08:00| 99.0|
+-----------------------------+---------+
Total line number = 12
It costs 0.065s
Equal Size Bucket Outlier Sample
This function samples the input sequence with equal number of bucket outliers, that is, according to the downsampling ratio given by the user and the number of samples in the bucket, the input sequence is divided into several buckets according to a fixed number of points. Sampling by the given outlier sampling method within each bucket.
| Function Name | Allowed Input Series Data Types | Required Attributes | Output Series Data Type | Description |
|---|---|---|---|---|
| EQUAL_SIZE_BUCKET_OUTLIER_SAMPLE | INT32 / INT64 / FLOAT / DOUBLE | The value range of proportion is (0, 1], the default is 0.1The value of type is avg or stendis or cos or prenextdis, the default is avg The value of number should be greater than 0, the default is 3 | INT32 / INT64 / FLOAT / DOUBLE | Returns outlier samples in equal buckets that match the sampling ratio and the number of samples in the bucket |
Parameter Description
proportion: sampling rationumber: the number of samples in each bucket, default3type: outlier sampling method, the value isavg: Take the average of the data points in the bucket, and find thetop numberfarthest from the average according to the sampling ratiostendis: Take the vertical distance between each data point in the bucket and the first and last data points of the bucket to form a straight line, and according to the sampling ratio, find thetop numberwith the largest distancecos: Set a data point in the bucket as b, the data point on the left of b as a, and the data point on the right of b as c, then take the cosine value of the angle between the ab and bc vectors. The larger the angle, the more likely it is an outlier. Find thetop numberwith the smallest cos valueprenextdis: Let a data point in the bucket be b, the data point to the left of b is a, and the data point to the right of b is c, then take the sum of the lengths of ab and bc as the yardstick, the larger the sum, the more likely it is to be an outlier, and find thetop numberwith the largest sum value
Example
Example data: root.ln.wf01.wt01.temperature has a total of 100 ordered data from 0.0-99.0. Among them, in order to add outliers, we make the number modulo 5 equal to 0 increment by 100.
IoTDB> select temperature from root.ln.wf01.wt01;
+-----------------------------+-----------------------------+
| Time|root.ln.wf01.wt01.temperature|
+-----------------------------+-----------------------------+
|1970-01-01T08:00:00.000+08:00| 0.0|
|1970-01-01T08:00:00.001+08:00| 1.0|
|1970-01-01T08:00:00.002+08:00| 2.0|
|1970-01-01T08:00:00.003+08:00| 3.0|
|1970-01-01T08:00:00.004+08:00| 4.0|
|1970-01-01T08:00:00.005+08:00| 105.0|
|1970-01-01T08:00:00.006+08:00| 6.0|
|1970-01-01T08:00:00.007+08:00| 7.0|
|1970-01-01T08:00:00.008+08:00| 8.0|
|1970-01-01T08:00:00.009+08:00| 9.0|
|1970-01-01T08:00:00.010+08:00| 10.0|
|1970-01-01T08:00:00.011+08:00| 11.0|
|1970-01-01T08:00:00.012+08:00| 12.0|
|1970-01-01T08:00:00.013+08:00| 13.0|
|1970-01-01T08:00:00.014+08:00| 14.0|
|1970-01-01T08:00:00.015+08:00| 115.0|
|1970-01-01T08:00:00.016+08:00| 16.0|
|.............................|.............................|
|1970-01-01T08:00:00.092+08:00| 92.0|
|1970-01-01T08:00:00.093+08:00| 93.0|
|1970-01-01T08:00:00.094+08:00| 94.0|
|1970-01-01T08:00:00.095+08:00| 195.0|
|1970-01-01T08:00:00.096+08:00| 96.0|
|1970-01-01T08:00:00.097+08:00| 97.0|
|1970-01-01T08:00:00.098+08:00| 98.0|
|1970-01-01T08:00:00.099+08:00| 99.0|
+-----------------------------+-----------------------------+
Sql:
select equal_size_bucket_outlier_sample(temperature, 'proportion'='0.1', 'type'='avg', 'number'='2') as outlier_avg_sample, equal_size_bucket_outlier_sample(temperature, 'proportion'='0.1', 'type'='stendis', 'number'='2') as outlier_stendis_sample, equal_size_bucket_outlier_sample(temperature, 'proportion'='0.1', 'type'='cos', 'number'='2') as outlier_cos_sample, equal_size_bucket_outlier_sample(temperature, 'proportion'='0.1', 'type'='prenextdis', 'number'='2') as outlier_prenextdis_sample from root.ln.wf01.wt01;
Result:
+-----------------------------+------------------+----------------------+------------------+-------------------------+
| Time|outlier_avg_sample|outlier_stendis_sample|outlier_cos_sample|outlier_prenextdis_sample|
+-----------------------------+------------------+----------------------+------------------+-------------------------+
|1970-01-01T08:00:00.005+08:00| 105.0| 105.0| 105.0| 105.0|
|1970-01-01T08:00:00.015+08:00| 115.0| 115.0| 115.0| 115.0|
|1970-01-01T08:00:00.025+08:00| 125.0| 125.0| 125.0| 125.0|
|1970-01-01T08:00:00.035+08:00| 135.0| 135.0| 135.0| 135.0|
|1970-01-01T08:00:00.045+08:00| 145.0| 145.0| 145.0| 145.0|
|1970-01-01T08:00:00.055+08:00| 155.0| 155.0| 155.0| 155.0|
|1970-01-01T08:00:00.065+08:00| 165.0| 165.0| 165.0| 165.0|
|1970-01-01T08:00:00.075+08:00| 175.0| 175.0| 175.0| 175.0|
|1970-01-01T08:00:00.085+08:00| 185.0| 185.0| 185.0| 185.0|
|1970-01-01T08:00:00.095+08:00| 195.0| 195.0| 195.0| 195.0|
+-----------------------------+------------------+----------------------+------------------+-------------------------+
Total line number = 10
It costs 0.041s
M4 Function
M4 is used to sample the first, last, bottom, top points for each sliding window:
- the first point is the point with the minimal time;
- the last point is the point with the maximal time;
- the bottom point is the point with the minimal value (if there are multiple such points, M4 returns one of them);
- the top point is the point with the maximal value (if there are multiple such points, M4 returns one of them).
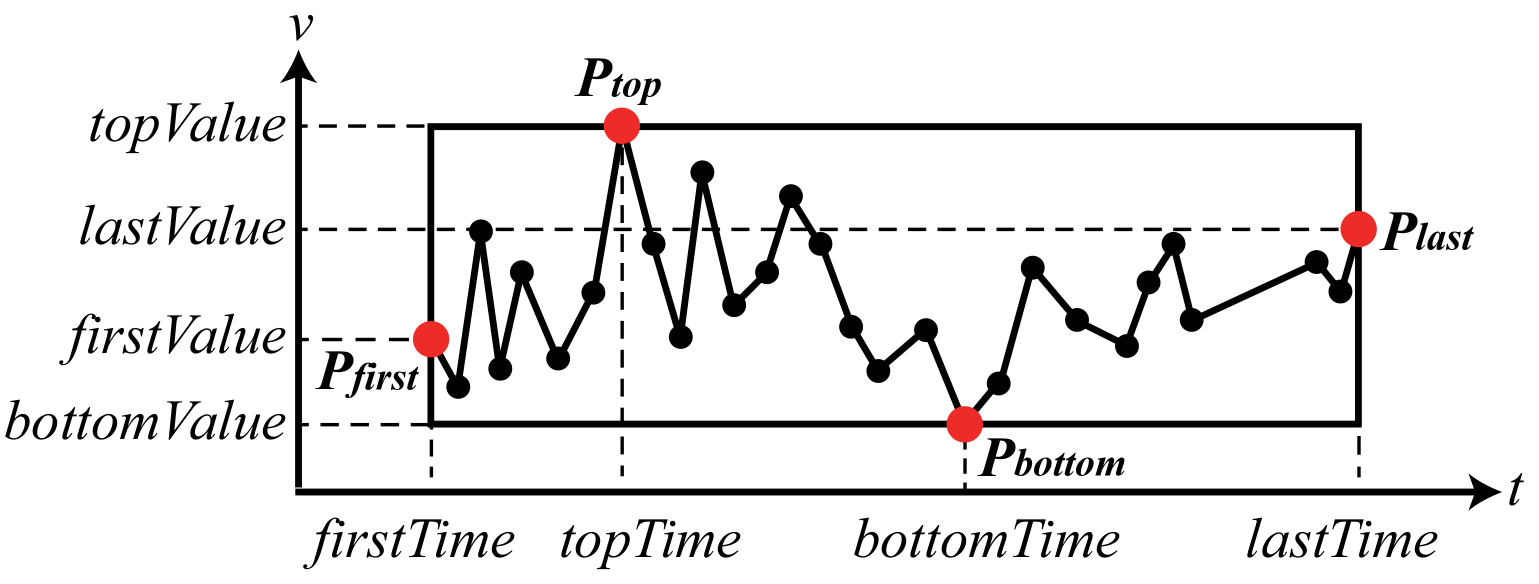
| Function Name | Allowed Input Series Data Types | Required Attributes | Output Series Data Type | Description |
|---|---|---|---|---|
| M4 | INT32 / INT64 / FLOAT / DOUBLE | Different attributes used by the size window and the time window. The size window uses attributes windowSize and slidingStep. The time window uses attributes timeInterval, slidingStep, displayWindowBegin, and displayWindowEnd. More details see below. | INT32 / INT64 / FLOAT / DOUBLE | Returns the first, last, bottom, top points in each sliding window. M4 sorts and deduplicates the aggregated points within the window before outputting them. |
Attributes
(1) Attributes for the size window:
windowSize: The number of points in a window. Int data type. Required.slidingStep: Slide a window by the number of points. Int data type. Optional. If not set, default to the same aswindowSize.
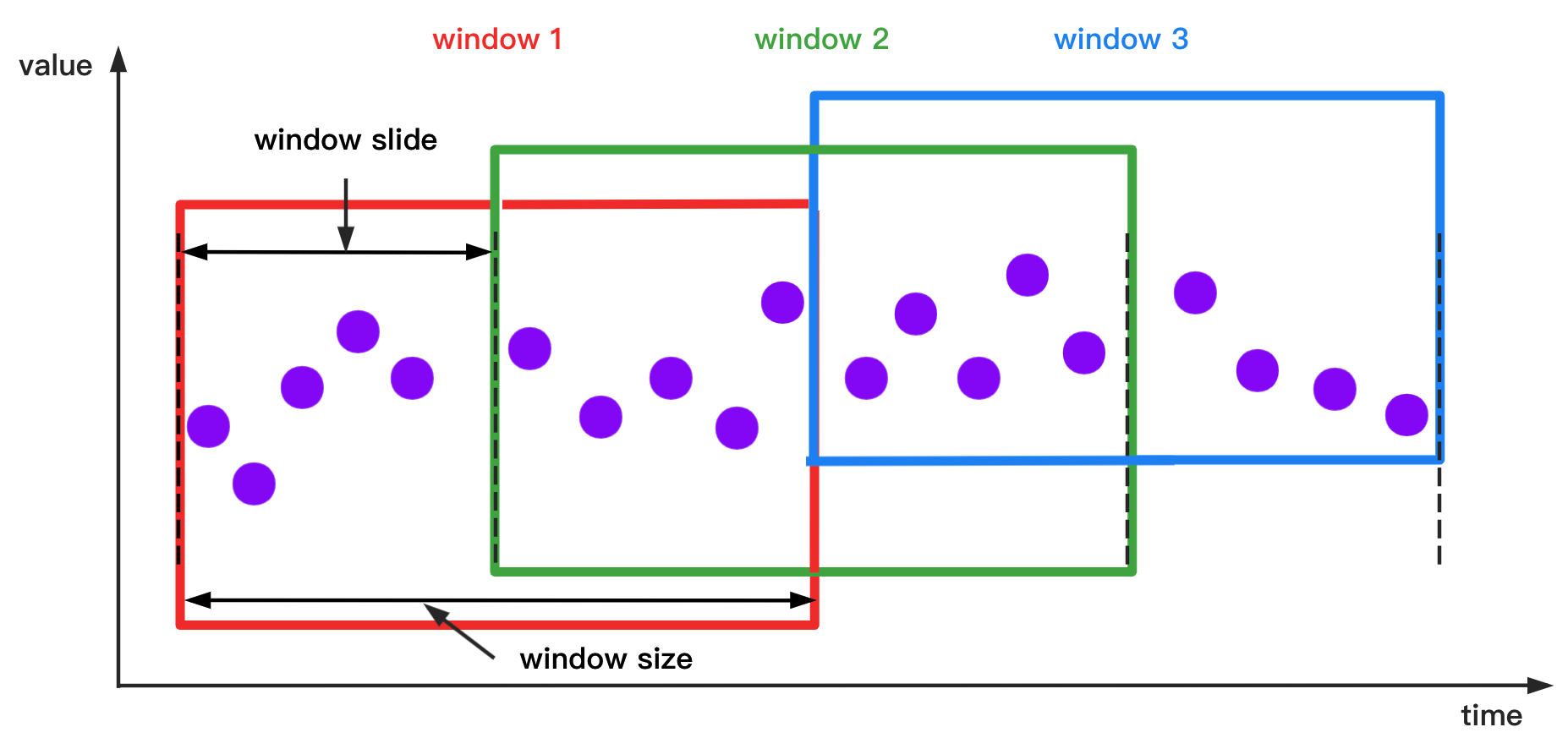
(2) Attributes for the time window:
timeInterval: The time interval length of a window. Long data type. Required.slidingStep: Slide a window by the time length. Long data type. Optional. If not set, default to the same astimeInterval.displayWindowBegin: The starting position of the window (included). Long data type. Optional. If not set, default to Long.MIN_VALUE, meaning using the time of the first data point of the input time series as the starting position of the window.displayWindowEnd: End time limit (excluded, essentially playing the same role asWHERE time < displayWindowEnd). Long data type. Optional. If not set, default to Long.MAX_VALUE, meaning there is no additional end time limit other than the end of the input time series itself.
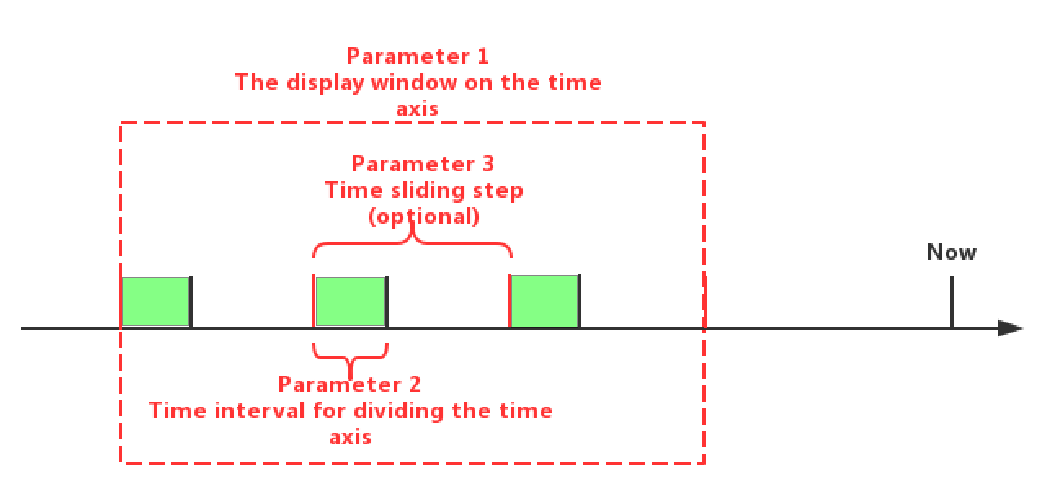
Examples
Input series:
+-----------------------------+------------------+
| Time|root.vehicle.d1.s1|
+-----------------------------+------------------+
|1970-01-01T08:00:00.001+08:00| 5.0|
|1970-01-01T08:00:00.002+08:00| 15.0|
|1970-01-01T08:00:00.005+08:00| 10.0|
|1970-01-01T08:00:00.008+08:00| 8.0|
|1970-01-01T08:00:00.010+08:00| 30.0|
|1970-01-01T08:00:00.020+08:00| 20.0|
|1970-01-01T08:00:00.025+08:00| 8.0|
|1970-01-01T08:00:00.027+08:00| 20.0|
|1970-01-01T08:00:00.030+08:00| 40.0|
|1970-01-01T08:00:00.033+08:00| 9.0|
|1970-01-01T08:00:00.035+08:00| 10.0|
|1970-01-01T08:00:00.040+08:00| 20.0|
|1970-01-01T08:00:00.045+08:00| 30.0|
|1970-01-01T08:00:00.052+08:00| 8.0|
|1970-01-01T08:00:00.054+08:00| 18.0|
+-----------------------------+------------------+
SQL for query1:
select M4(s1,'timeInterval'='25','displayWindowBegin'='0','displayWindowEnd'='100') from root.vehicle.d1
Output1:
+-----------------------------+-----------------------------------------------------------------------------------------------+
| Time|M4(root.vehicle.d1.s1, "timeInterval"="25", "displayWindowBegin"="0", "displayWindowEnd"="100")|
+-----------------------------+-----------------------------------------------------------------------------------------------+
|1970-01-01T08:00:00.001+08:00| 5.0|
|1970-01-01T08:00:00.010+08:00| 30.0|
|1970-01-01T08:00:00.020+08:00| 20.0|
|1970-01-01T08:00:00.025+08:00| 8.0|
|1970-01-01T08:00:00.030+08:00| 40.0|
|1970-01-01T08:00:00.045+08:00| 30.0|
|1970-01-01T08:00:00.052+08:00| 8.0|
|1970-01-01T08:00:00.054+08:00| 18.0|
+-----------------------------+-----------------------------------------------------------------------------------------------+
Total line number = 8
SQL for query2:
select M4(s1,'windowSize'='10') from root.vehicle.d1
Output2:
+-----------------------------+-----------------------------------------+
| Time|M4(root.vehicle.d1.s1, "windowSize"="10")|
+-----------------------------+-----------------------------------------+
|1970-01-01T08:00:00.001+08:00| 5.0|
|1970-01-01T08:00:00.030+08:00| 40.0|
|1970-01-01T08:00:00.033+08:00| 9.0|
|1970-01-01T08:00:00.035+08:00| 10.0|
|1970-01-01T08:00:00.045+08:00| 30.0|
|1970-01-01T08:00:00.052+08:00| 8.0|
|1970-01-01T08:00:00.054+08:00| 18.0|
+-----------------------------+-----------------------------------------+
Total line number = 7
Suggested Use Cases
(1) Use Case: Extreme-point-preserving downsampling
As M4 aggregation selects the first, last, bottom, top points for each window, M4 usually preserves extreme points and thus patterns better than other downsampling methods such as Piecewise Aggregate Approximation (PAA). Therefore, if you want to downsample the time series while preserving extreme points, you may give M4 a try.
(2) Use case: Error-free two-color line chart visualization of large-scale time series through M4 downsampling
Referring to paper "M4: A Visualization-Oriented Time Series Data Aggregation", M4 is a downsampling method to facilitate large-scale time series visualization without deforming the shape in terms of a two-color line chart.
Given a chart of w*h pixels, suppose that the visualization time range of the time series is [tqs,tqe) and (tqe-tqs) is divisible by w, the points that fall within the i-th time span Ii=[tqs+(tqe-tqs)/w*(i-1),tqs+(tqe-tqs)/w*i) will be drawn on the i-th pixel column, i=1,2,...,w. Therefore, from a visualization-driven perspective, use the sql: "select M4(s1,'timeInterval'='(tqe-tqs)/w','displayWindowBegin'='tqs','displayWindowEnd'='tqe') from root.vehicle.d1" to sample the first, last, bottom, top points for each time span. The resulting downsampled time series has no more than 4*w points, a big reduction compared to the original large-scale time series. Meanwhile, the two-color line chart drawn from the reduced data is identical that to that drawn from the original data (pixel-level consistency).
To eliminate the hassle of hardcoding parameters, we recommend the following usage of Grafana's template variable $__interval_ms when Grafana is used for visualization:
select M4(s1,'timeInterval'='$__interval_ms') from root.sg1.d1
where timeInterval is set as (tqe-tqs)/w automatically. Note that the time precision here is assumed to be milliseconds.
Comparison with Other Functions
| SQL | Whether support M4 aggregation | Sliding window type | Example | Docs |
|---|---|---|---|---|
| 1. native built-in aggregate functions with Group By clause | No. Lack BOTTOM_TIME and TOP_TIME, which are respectively the time of the points that have the mininum and maximum value. | Time Window | select count(status), max_value(temperature) from root.ln.wf01.wt01 group by ([2017-11-01 00:00:00, 2017-11-07 23:00:00), 3h, 1d) | https://iotdb.apache.org/UserGuide/Master/Query-Data/Aggregate-Query.html#built-in-aggregate-functions https://iotdb.apache.org/UserGuide/Master/Query-Data/Aggregate-Query.html#downsampling-aggregate-query |
| 2. EQUAL_SIZE_BUCKET_M4_SAMPLE (built-in UDF) | Yes* | Size Window. windowSize = 4*(int)(1/proportion) | select equal_size_bucket_m4_sample(temperature, 'proportion'='0.1') as M4_sample from root.ln.wf01.wt01 | https://iotdb.apache.org/UserGuide/Master/Query-Data/Select-Expression.html#time-series-generating-functions |
| 3. M4 (built-in UDF) | Yes* | Size Window, Time Window | (1) Size Window: select M4(s1,'windowSize'='10') from root.vehicle.d1 (2) Time Window: select M4(s1,'timeInterval'='25','displayWindowBegin'='0','displayWindowEnd'='100') from root.vehicle.d1 | refer to this doc |
| 4. extend native built-in aggregate functions with Group By clause to support M4 aggregation | not implemented | not implemented | not implemented | not implemented |
Further compare EQUAL_SIZE_BUCKET_M4_SAMPLE and M4:
(1) Different M4 aggregation definition:
For each window, EQUAL_SIZE_BUCKET_M4_SAMPLE extracts the top and bottom points from points EXCLUDING the first and last points.
In contrast, M4 extracts the top and bottom points from points INCLUDING the first and last points, which is more consistent with the semantics of max_value and min_value stored in metadata.
It is worth noting that both functions sort and deduplicate the aggregated points in a window before outputting them to the collectors.
(2) Different sliding windows:
EQUAL_SIZE_BUCKET_M4_SAMPLE uses SlidingSizeWindowAccessStrategy and indirectly controls sliding window size by sampling proportion. The conversion formula is windowSize = 4*(int)(1/proportion).
M4 supports two types of sliding window: SlidingSizeWindowAccessStrategy and SlidingTimeWindowAccessStrategy. M4 directly controls the window point size or time length using corresponding parameters.
Time Series Processing
CHANGE_POINTS
Usage
This function is used to remove consecutive identical values from an input sequence.
For example, input:1,1,2,2,3 output:1,2,3.
Name: CHANGE_POINTS
Input Series: Support only one input series.
Parameters: No parameters.
Example
Raw data:
+-----------------------------+---------------------------+---------------------------+---------------------------+---------------------------+---------------------------+---------------------------+
| Time|root.testChangePoints.d1.s1|root.testChangePoints.d1.s2|root.testChangePoints.d1.s3|root.testChangePoints.d1.s4|root.testChangePoints.d1.s5|root.testChangePoints.d1.s6|
+-----------------------------+---------------------------+---------------------------+---------------------------+---------------------------+---------------------------+---------------------------+
|1970-01-01T08:00:00.001+08:00| true| 1| 1| 1.0| 1.0| 1test1|
|1970-01-01T08:00:00.002+08:00| true| 2| 2| 2.0| 1.0| 2test2|
|1970-01-01T08:00:00.003+08:00| false| 1| 2| 1.0| 1.0| 2test2|
|1970-01-01T08:00:00.004+08:00| true| 1| 3| 1.0| 1.0| 1test1|
|1970-01-01T08:00:00.005+08:00| true| 1| 3| 1.0| 1.0| 1test1|
+-----------------------------+---------------------------+---------------------------+---------------------------+---------------------------+---------------------------+---------------------------+
SQL for query:
select change_points(s1), change_points(s2), change_points(s3), change_points(s4), change_points(s5), change_points(s6) from root.testChangePoints.d1
Output series:
+-----------------------------+------------------------------------------+------------------------------------------+------------------------------------------+------------------------------------------+------------------------------------------+------------------------------------------+
| Time|change_points(root.testChangePoints.d1.s1)|change_points(root.testChangePoints.d1.s2)|change_points(root.testChangePoints.d1.s3)|change_points(root.testChangePoints.d1.s4)|change_points(root.testChangePoints.d1.s5)|change_points(root.testChangePoints.d1.s6)|
+-----------------------------+------------------------------------------+------------------------------------------+------------------------------------------+------------------------------------------+------------------------------------------+------------------------------------------+
|1970-01-01T08:00:00.001+08:00| true| 1| 1| 1.0| 1.0| 1test1|
|1970-01-01T08:00:00.002+08:00| null| 2| 2| 2.0| null| 2test2|
|1970-01-01T08:00:00.003+08:00| false| 1| null| 1.0| null| null|
|1970-01-01T08:00:00.004+08:00| true| null| 3| null| null| 1test1|
+-----------------------------+------------------------------------------+------------------------------------------+------------------------------------------+------------------------------------------+------------------------------------------+------------------------------------------+
Lambda Expression
JEXL Function
Java Expression Language (JEXL) is an expression language engine. We use JEXL to extend UDFs, which are implemented on the command line with simple lambda expressions. See the link for operators supported in jexl lambda expressions.
| Function Name | Allowed Input Series Data Types | Required Attributes | Output Series Data Type | Series Data Type Description |
|---|---|---|---|---|
| JEXL | INT32 / INT64 / FLOAT / DOUBLE / TEXT / BOOLEAN | expr is a lambda expression that supports standard one or multi arguments in the form x -> {...} or (x, y, z) -> {...}, e.g. x -> {x * 2}, (x, y, z) -> {x + y * z} | INT32 / INT64 / FLOAT / DOUBLE / TEXT / BOOLEAN | Returns the input time series transformed by a lambda expression |
Demonstrate
Example data: root.ln.wf01.wt01.temperature, root.ln.wf01.wt01.st, root.ln.wf01.wt01.str a total of 11 data.
IoTDB> select * from root.ln.wf01.wt01;
+-----------------------------+---------------------+--------------------+-----------------------------+
| Time|root.ln.wf01.wt01.str|root.ln.wf01.wt01.st|root.ln.wf01.wt01.temperature|
+-----------------------------+---------------------+--------------------+-----------------------------+
|1970-01-01T08:00:00.000+08:00| str| 10.0| 0.0|
|1970-01-01T08:00:00.001+08:00| str| 20.0| 1.0|
|1970-01-01T08:00:00.002+08:00| str| 30.0| 2.0|
|1970-01-01T08:00:00.003+08:00| str| 40.0| 3.0|
|1970-01-01T08:00:00.004+08:00| str| 50.0| 4.0|
|1970-01-01T08:00:00.005+08:00| str| 60.0| 5.0|
|1970-01-01T08:00:00.006+08:00| str| 70.0| 6.0|
|1970-01-01T08:00:00.007+08:00| str| 80.0| 7.0|
|1970-01-01T08:00:00.008+08:00| str| 90.0| 8.0|
|1970-01-01T08:00:00.009+08:00| str| 100.0| 9.0|
|1970-01-01T08:00:00.010+08:00| str| 110.0| 10.0|
+-----------------------------+---------------------+--------------------+-----------------------------+
Sql:
select jexl(temperature, 'expr'='x -> {x + x}') as jexl1, jexl(temperature, 'expr'='x -> {x * 3}') as jexl2, jexl(temperature, 'expr'='x -> {x * x}') as jexl3, jexl(temperature, 'expr'='x -> {multiply(x, 100)}') as jexl4, jexl(temperature, st, 'expr'='(x, y) -> {x + y}') as jexl5, jexl(temperature, st, str, 'expr'='(x, y, z) -> {x + y + z}') as jexl6 from root.ln.wf01.wt01;```
Result:
+-----------------------------+-----+-----+-----+------+-----+--------+
| Time|jexl1|jexl2|jexl3| jexl4|jexl5| jexl6|
+-----------------------------+-----+-----+-----+------+-----+--------+
|1970-01-01T08:00:00.000+08:00| 0.0| 0.0| 0.0| 0.0| 10.0| 10.0str|
|1970-01-01T08:00:00.001+08:00| 2.0| 3.0| 1.0| 100.0| 21.0| 21.0str|
|1970-01-01T08:00:00.002+08:00| 4.0| 6.0| 4.0| 200.0| 32.0| 32.0str|
|1970-01-01T08:00:00.003+08:00| 6.0| 9.0| 9.0| 300.0| 43.0| 43.0str|
|1970-01-01T08:00:00.004+08:00| 8.0| 12.0| 16.0| 400.0| 54.0| 54.0str|
|1970-01-01T08:00:00.005+08:00| 10.0| 15.0| 25.0| 500.0| 65.0| 65.0str|
|1970-01-01T08:00:00.006+08:00| 12.0| 18.0| 36.0| 600.0| 76.0| 76.0str|
|1970-01-01T08:00:00.007+08:00| 14.0| 21.0| 49.0| 700.0| 87.0| 87.0str|
|1970-01-01T08:00:00.008+08:00| 16.0| 24.0| 64.0| 800.0| 98.0| 98.0str|
|1970-01-01T08:00:00.009+08:00| 18.0| 27.0| 81.0| 900.0|109.0|109.0str|
|1970-01-01T08:00:00.010+08:00| 20.0| 30.0|100.0|1000.0|120.0|120.0str|
+-----------------------------+-----+-----+-----+------+-----+--------+
Total line number = 11
It costs 0.118s
Conditional Expressions
CASE
The CASE expression is a kind of conditional expression that can be used to return different values based on specific conditions, similar to the if-else statements in other languages.
The CASE expression consists of the following parts:
- CASE keyword: Indicates the start of the CASE expression.
- WHEN-THEN clauses: There may be multiple clauses used to define conditions and give results. This clause is divided into two parts, WHEN and THEN. The WHEN part defines the condition, and the THEN part defines the result expression. If the WHEN condition is true, the corresponding THEN result is returned.
- ELSE clause: If none of the WHEN conditions is true, the result in the ELSE clause will be returned. The ELSE clause can be omitted.
- END keyword: Indicates the end of the CASE expression.
The CASE expression is a scalar operation that can be used in combination with any other scalar operation or aggregate function.
In the following text, all THEN parts and ELSE clauses will be collectively referred to as result clauses.
Syntax
The CASE expression supports two formats.
Format 1:
CASE WHEN condition1 THEN expression1 [WHEN condition2 THEN expression2] ... [ELSE expression_end] ENDThe
conditions will be evaluated one by one.The first
conditionthat is true will return the corresponding expression.Format 2:
CASE caseValue WHEN whenValue1 THEN expression1 [WHEN whenValue2 THEN expression2] ... [ELSE expression_end] ENDThe
caseValuewill be evaluated first, and then thewhenValues will be evaluated one by one. The firstwhenValuethat is equal to thecaseValuewill return the correspondingexpression.Format 2 will be transformed into an equivalent Format 1 by iotdb.
For example, the above SQL statement will be transformed into:
CASE WHEN caseValue=whenValue1 THEN expression1 [WHEN caseValue=whenValue1 THEN expression1] ... [ELSE expression_end] END
If none of the conditions are true, or if none of the whenValues match the caseValue, the expression_end will be returned.
If there is no ELSE clause, null will be returned.
Notes
- In format 1, all WHEN clauses must return a BOOLEAN type.
- In format 2, all WHEN clauses must be able to be compared to the CASE clause.
- All result clauses in a CASE expression must satisfy certain conditions for their return value types:
- BOOLEAN types cannot coexist with other types and will cause an error if present.
- TEXT types cannot coexist with other types and will cause an error if present.
- The other four numeric types can coexist, and the final result will be of DOUBLE type, with possible precision loss during conversion.
- If necessary, you can use the CAST function to convert the result to a type that can coexist with others.
- The CASE expression does not implement lazy evaluation, meaning that all clauses will be evaluated.
- The CASE expression does not support mixing with UDFs.
- Aggregate functions cannot be used within a CASE expression, but the result of a CASE expression can be used as input for an aggregate function.
- When using the CLI, because the CASE expression string can be lengthy, it is recommended to provide an alias for the expression using AS.
Using Examples
Example 1
The CASE expression can be used to analyze data in a visual way. For example:
- The preparation of a certain chemical product requires that the temperature and pressure be within specific ranges.
- During the preparation process, sensors will detect the temperature and pressure, forming two time-series T (temperature) and P (pressure) in IoTDB.
In this application scenario, the CASE expression can indicate which time parameters are appropriate, which are not, and why they are not.
data:
IoTDB> select * from root.test1
+-----------------------------+------------+------------+
| Time|root.test1.P|root.test1.T|
+-----------------------------+------------+------------+
|2023-03-29T11:25:54.724+08:00| 1000000.0| 1025.0|
|2023-03-29T11:26:13.445+08:00| 1000094.0| 1040.0|
|2023-03-29T11:27:36.988+08:00| 1000095.0| 1041.0|
|2023-03-29T11:27:56.446+08:00| 1000095.0| 1059.0|
|2023-03-29T11:28:20.838+08:00| 1200000.0| 1040.0|
+-----------------------------+------------+------------+
SQL statements:
select T, P, case
when 1000<T and T<1050 and 1000000<P and P<1100000 then "good!"
when T<=1000 or T>=1050 then "bad temperature"
when P<=1000000 or P>=1100000 then "bad pressure"
end as `result`
from root.test1
output:
+-----------------------------+------------+------------+---------------+
| Time|root.test1.T|root.test1.P| result|
+-----------------------------+------------+------------+---------------+
|2023-03-29T11:25:54.724+08:00| 1025.0| 1000000.0| bad pressure|
|2023-03-29T11:26:13.445+08:00| 1040.0| 1000094.0| good!|
|2023-03-29T11:27:36.988+08:00| 1041.0| 1000095.0| good!|
|2023-03-29T11:27:56.446+08:00| 1059.0| 1000095.0|bad temperature|
|2023-03-29T11:28:20.838+08:00| 1040.0| 1200000.0| bad pressure|
+-----------------------------+------------+------------+---------------+
Example 2
The CASE expression can achieve flexible result transformation, such as converting strings with a certain pattern to other strings.
data:
IoTDB> select * from root.test2
+-----------------------------+--------------+
| Time|root.test2.str|
+-----------------------------+--------------+
|2023-03-27T18:23:33.427+08:00| abccd|
|2023-03-27T18:23:39.389+08:00| abcdd|
|2023-03-27T18:23:43.463+08:00| abcdefg|
+-----------------------------+--------------+
SQL statements:
select str, case
when str like "%cc%" then "has cc"
when str like "%dd%" then "has dd"
else "no cc and dd" end as `result`
from root.test2
output:
+-----------------------------+--------------+------------+
| Time|root.test2.str| result|
+-----------------------------+--------------+------------+
|2023-03-27T18:23:33.427+08:00| abccd| has cc|
|2023-03-27T18:23:39.389+08:00| abcdd| has dd|
|2023-03-27T18:23:43.463+08:00| abcdefg|no cc and dd|
+-----------------------------+--------------+------------+
Example 3: work with aggregation functions
Valid: aggregation function ← CASE expression
The CASE expression can be used as a parameter for aggregate functions. For example, used in conjunction with the COUNT function, it can implement statistics based on multiple conditions simultaneously.
data:
IoTDB> select * from root.test3
+-----------------------------+------------+
| Time|root.test3.x|
+-----------------------------+------------+
|2023-03-27T18:11:11.300+08:00| 0.0|
|2023-03-27T18:11:14.658+08:00| 1.0|
|2023-03-27T18:11:15.981+08:00| 2.0|
|2023-03-27T18:11:17.668+08:00| 3.0|
|2023-03-27T18:11:19.112+08:00| 4.0|
|2023-03-27T18:11:20.822+08:00| 5.0|
|2023-03-27T18:11:22.462+08:00| 6.0|
|2023-03-27T18:11:24.174+08:00| 7.0|
|2023-03-27T18:11:25.858+08:00| 8.0|
|2023-03-27T18:11:27.979+08:00| 9.0|
+-----------------------------+------------+
SQL statements:
select
count(case when x<=1 then 1 end) as `(-∞,1]`,
count(case when 1<x and x<=3 then 1 end) as `(1,3]`,
count(case when 3<x and x<=7 then 1 end) as `(3,7]`,
count(case when 7<x then 1 end) as `(7,+∞)`
from root.test3
output:
+------+-----+-----+------+
|(-∞,1]|(1,3]|(3,7]|(7,+∞)|
+------+-----+-----+------+
| 2| 2| 4| 2|
+------+-----+-----+------+
Invalid: CASE expression ← aggregation function
Using aggregation function in CASE expression is not supported
SQL statements:
select case when x<=1 then avg(x) else sum(x) end from root.test3
output:
Msg: 701: Raw data and aggregation result hybrid calculation is not supported.
Example 4: kind 2
Here is a simple example that uses the format 2 syntax.
If all conditions are equality tests, it is recommended to use format 2 to simplify SQL statements.
data:
IoTDB> select * from root.test4
+-----------------------------+------------+
| Time|root.test4.x|
+-----------------------------+------------+
|1970-01-01T08:00:00.001+08:00| 1.0|
|1970-01-01T08:00:00.002+08:00| 2.0|
|1970-01-01T08:00:00.003+08:00| 3.0|
|1970-01-01T08:00:00.004+08:00| 4.0|
+-----------------------------+------------+
SQL statements:
select x, case x when 1 then "one" when 2 then "two" else "other" end from root.test4
output:
+-----------------------------+------------+-----------------------------------------------------------------------------------+
| Time|root.test4.x|CASE WHEN root.test4.x = 1 THEN "one" WHEN root.test4.x = 2 THEN "two" ELSE "other"|
+-----------------------------+------------+-----------------------------------------------------------------------------------+
|1970-01-01T08:00:00.001+08:00| 1.0| one|
|1970-01-01T08:00:00.002+08:00| 2.0| two|
|1970-01-01T08:00:00.003+08:00| 3.0| other|
|1970-01-01T08:00:00.004+08:00| 4.0| other|
+-----------------------------+------------+-----------------------------------------------------------------------------------+
Example 5: type of return clauses
The result clause of a CASE expression needs to satisfy certain type restrictions.
In this example, we continue to use the data from Example 4.
Invalid: BOOLEAN cannot coexist with other types
SQL statements:
select x, case x when 1 then true when 2 then 2 end from root.test4
output:
Msg: 701: CASE expression: BOOLEAN and other types cannot exist at same time
Valid: Only BOOLEAN type exists
SQL statements:
select x, case x when 1 then true when 2 then false end as `result` from root.test4
output:
+-----------------------------+------------+------+
| Time|root.test4.x|result|
+-----------------------------+------------+------+
|1970-01-01T08:00:00.001+08:00| 1.0| true|
|1970-01-01T08:00:00.002+08:00| 2.0| false|
|1970-01-01T08:00:00.003+08:00| 3.0| null|
|1970-01-01T08:00:00.004+08:00| 4.0| null|
+-----------------------------+------------+------+
Invalid:TEXT cannot coexist with other types
SQL statements:
select x, case x when 1 then 1 when 2 then "str" end from root.test4
output:
Msg: 701: CASE expression: TEXT and other types cannot exist at same time
Valid: Only TEXT type exists
See in Example 1.
Valid: Numerical types coexist
SQL statements:
select x, case x
when 1 then 1
when 2 then 222222222222222
when 3 then 3.3
when 4 then 4.4444444444444
end as `result`
from root.test4
output:
+-----------------------------+------------+-------------------+
| Time|root.test4.x| result|
+-----------------------------+------------+-------------------+
|1970-01-01T08:00:00.001+08:00| 1.0| 1.0|
|1970-01-01T08:00:00.002+08:00| 2.0|2.22222222222222E14|
|1970-01-01T08:00:00.003+08:00| 3.0| 3.299999952316284|
|1970-01-01T08:00:00.004+08:00| 4.0| 4.44444465637207|
+-----------------------------+------------+-------------------+