
AI Capability
AI Capability
AINode is the third internal node after ConfigNode and DataNode in Apache IoTDB, which extends the capability of machine learning analysis of time series by interacting with DataNode and ConfigNode of IoTDB cluster, supports the introduction of pre-existing machine learning models from the outside to be registered, and uses the registered models in the It supports the process of introducing existing machine learning models from outside for registration, and using the registered models to complete the time series analysis tasks on the specified time series data through simple SQL statements, which integrates the model creation, management and inference in the database engine. At present, we have provided machine learning algorithms or self-developed models for common timing analysis scenarios (e.g. prediction and anomaly detection).
The system architecture is shown below:
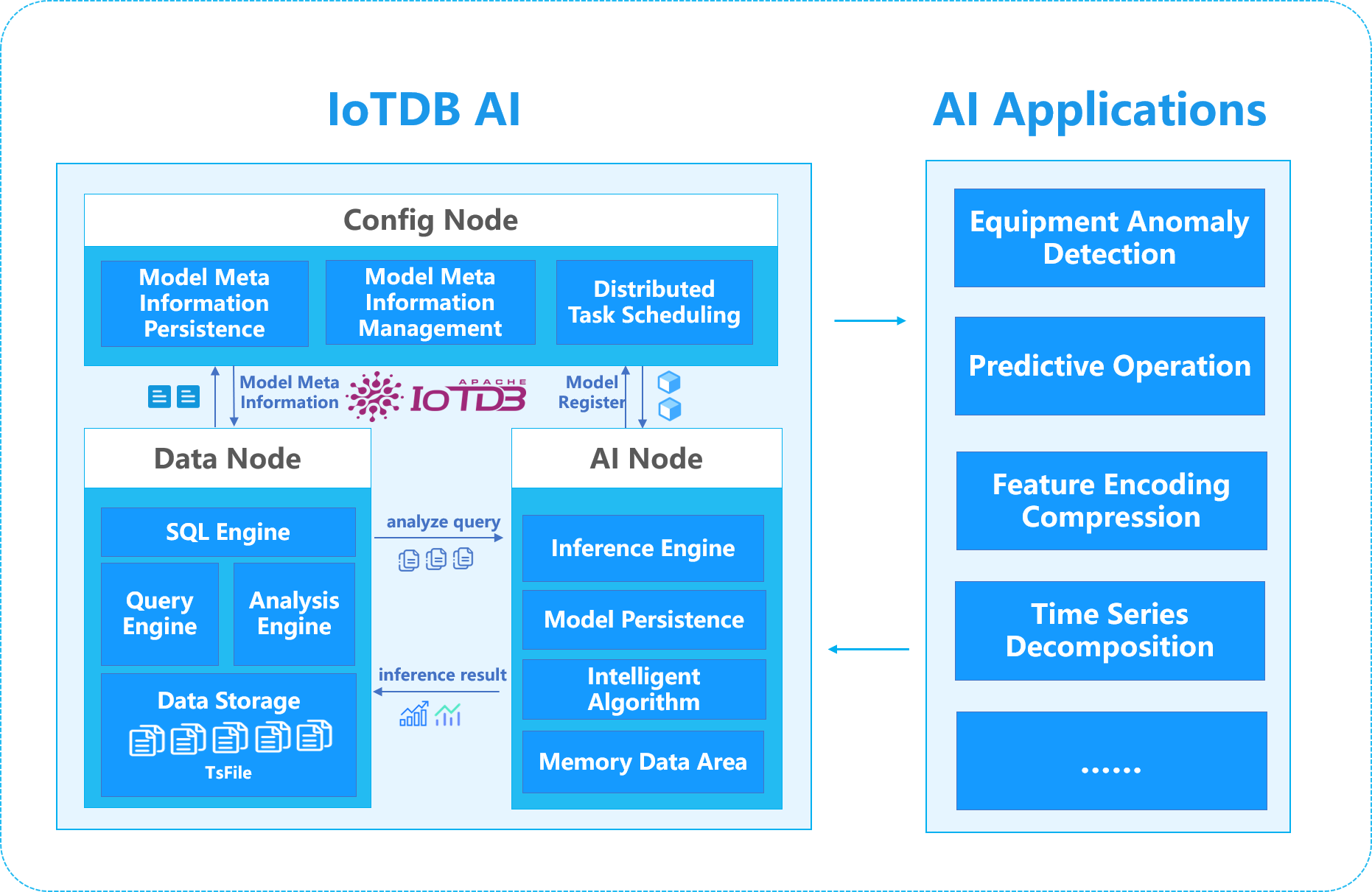
The responsibilities of the three nodes are as follows:
- ConfigNode: responsible for storing and managing the meta-information of the model; responsible for distributed node management.
- DataNode: responsible for receiving and parsing SQL requests from users; responsible for storing time-series data; responsible for preprocessing computation of data.
- AINode: responsible for model file import creation and model inference.
1. Advantageous features
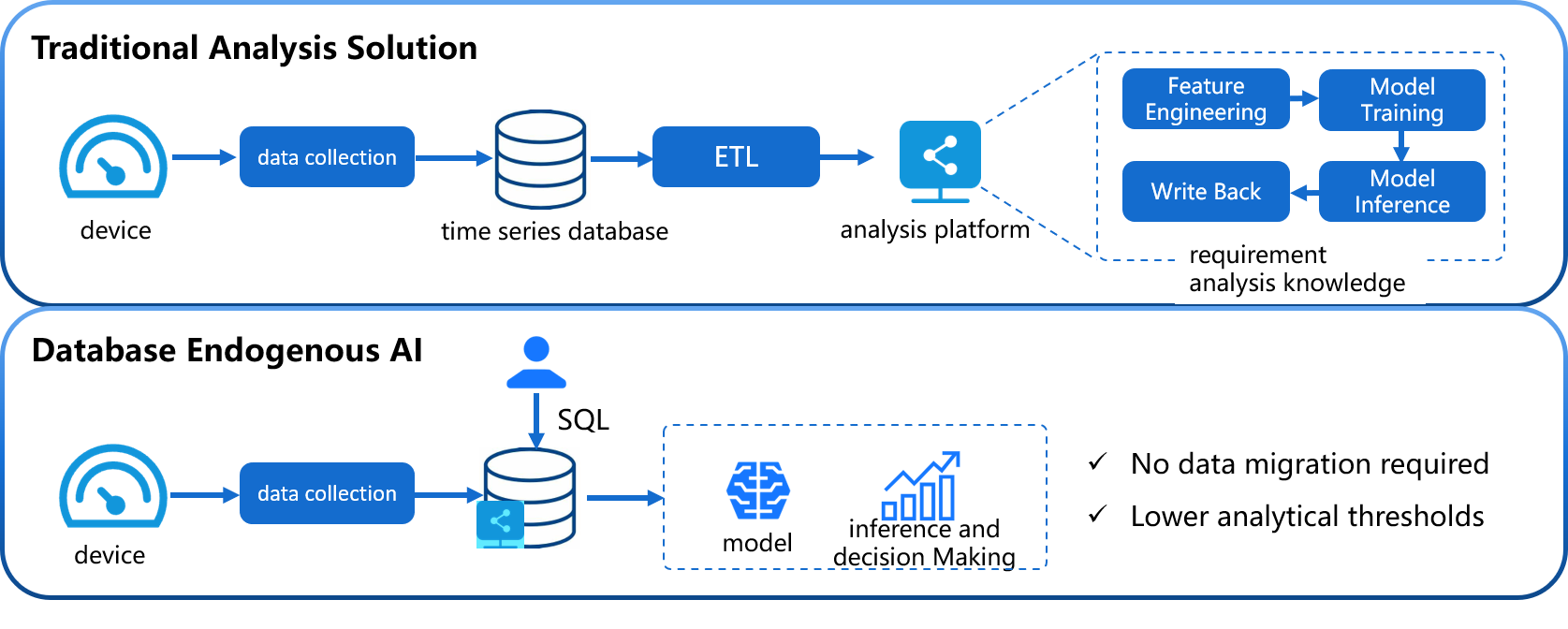
Compared with building a machine learning service alone, it has the following advantages:
Simple and easy to use: no need to use Python or Java programming, the complete process of machine learning model management and inference can be completed using SQL statements. Creating a model can be done using the CREATE MODEL statement, and using a model for inference can be done using the CALL INFERENCE (...) statement, making it simpler and more convenient to use.
Avoid Data Migration: With IoTDB native machine learning, data stored in IoTDB can be directly applied to the inference of machine learning models without having to move the data to a separate machine learning service platform, which accelerates data processing, improves security, and reduces costs.
- Built-in Advanced Algorithms: supports industry-leading machine learning analytics algorithms covering typical timing analysis tasks, empowering the timing database with native data analysis capabilities. Such as:
- Time Series Forecasting: learns patterns of change from past time series; thus outputs the most likely prediction of future series based on observations at a given past time.
- Anomaly Detection for Time Series: detects and identifies outliers in a given time series data, helping to discover anomalous behaviour in the time series.
- Annotation for Time Series (Time Series Annotation): Adds additional information or markers, such as event occurrence, outliers, trend changes, etc., to each data point or specific time period to better understand and analyse the data.
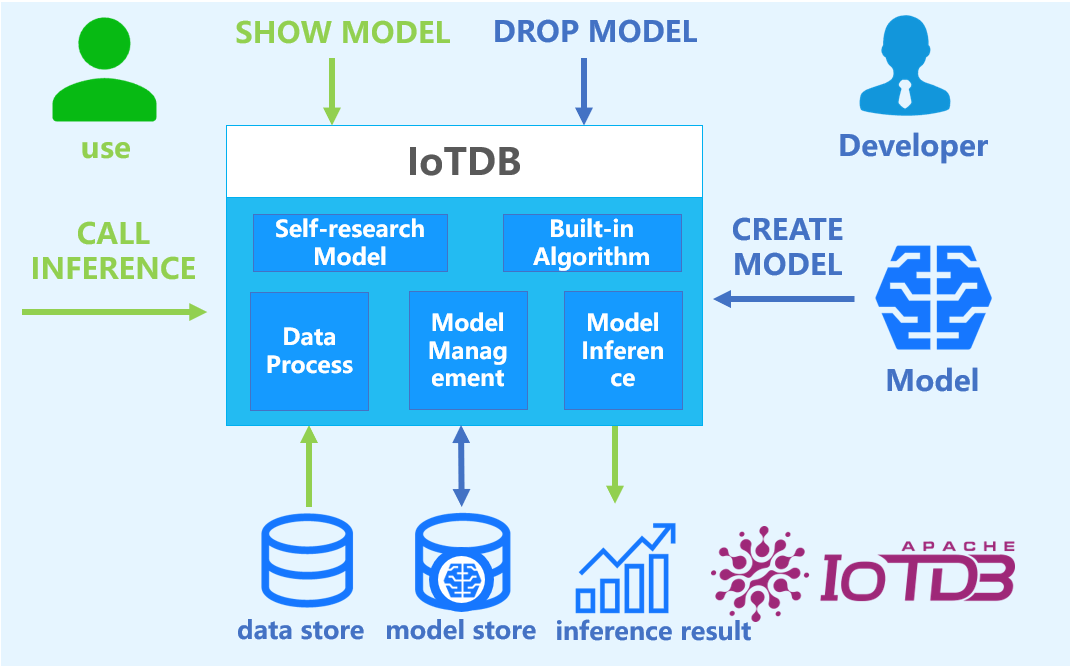
2. Basic Concepts
- Model: a machine learning model that takes time-series data as input and outputs the results or decisions of an analysis task. Model is the basic management unit of AINode, which supports adding (registration), deleting, checking, and using (inference) of models.
- Create: Load externally designed or trained model files or algorithms into MLNode for unified management and use by IoTDB.
- Inference: The process of using the created model to complete the timing analysis task applicable to the model on the specified timing data.
- Built-in capabilities: AINode comes with machine learning algorithms or home-grown models for common timing analysis scenarios (e.g., prediction and anomaly detection).
3. Installation and Deployment
The deployment of AINode can be found in the document Deployment Guidelines .
4. Usage Guidelines
AINode provides model creation and deletion process for deep learning models related to timing data. Built-in models do not need to be created and deleted, they can be used directly, and the built-in model instances created after inference is completed will be destroyed automatically.
4.1 Registering Models
A trained deep learning model can be registered by specifying the vector dimensions of the model's inputs and outputs, which can be used for model inference.
Models that meet the following criteria can be registered in AINode:
- Models trained on PyTorch 2.1.0 and 2.2.0 versions supported by AINode should avoid using features from versions 2.2.0 and above.
- AINode supports models stored using PyTorch JIT, and the model file needs to include the parameters and structure of the model.
- The input sequence of the model can contain one or more columns, and if there are multiple columns, they need to correspond to the model capability and model configuration file.
- The input and output dimensions of the model must be clearly defined in the
config.yamlconfiguration file. When using the model, it is necessary to strictly follow the input-output dimensions defined in theconfig.yamlconfiguration file. If the number of input and output columns does not match the configuration file, it will result in errors.
The following is the SQL syntax definition for model registration.
create model <model_name> using uri <uri>The specific meanings of the parameters in the SQL are as follows:
model_name: a globally unique identifier for the model, which cannot be repeated. The model name has the following constraints:
- Identifiers [ 0-9 a-z A-Z _ ] (letters, numbers, underscores) are allowed.
- Length is limited to 2-64 characters
- Case sensitive
uri: resource path to the model registration file, which should contain the model weights model.pt file and the model's metadata description file config.yaml.
Model weight file: the weight file obtained after the training of the deep learning model is completed, currently supporting pytorch training of the .pt file
yaml metadata description file: parameters related to the model structure that need to be provided when the model is registered, which must contain the input and output dimensions of the model for model inference:
Parameter name Parameter description Example input_shape Rows and columns of model inputs for model inference [96,2] output_shape rows and columns of model outputs, for model inference [48,2] In addition to model inference, the data types of model input and output can be specified:
Parameter name Parameter description Example input_type model input data type ['float32','float32'] output_type data type of the model output ['float32','float32'] In addition to this, additional notes can be specified for display during model management
Parameter name Parameter description Examples attributes optional, user-defined model notes for model display 'model_type': 'dlinear','kernel_size': '25'
In addition to registration of local model files, registration can also be done by specifying remote resource paths via URIs, using open source model repositories (e.g. HuggingFace).
Example
In the current example folder, it contains model.pt and config.yaml files, model.pt is the training get, and the content of config.yaml is as follows:
configs.
# Required options
input_shape: [96, 2] # The model receives data in 96 rows x 2 columns.
output_shape: [48, 2] # Indicates that the model outputs 48 rows x 2 columns.
# Optional Default is all float32 and the number of columns is the number of columns in the shape.
input_type: ["int64", "int64"] # Input data type, need to match the number of columns.
output_type: ["text", "int64"] #Output data type, need to match the number of columns.
attributes: # Optional user-defined notes for the input.
'model_type': 'dlinear'
'kernel_size': '25'Specify this folder as the load path to register the model.
IoTDB> create model dlinear_example using uri "file://. /example"Alternatively, you can download the corresponding model file from huggingFace and register it.
IoTDB> create model dlinear_example using uri "https://huggingface.com/IoTDBML/dlinear/"After the SQL is executed, the registration process will be carried out asynchronously, and you can view the registration status of the model through the model showcase (see the Model Showcase section), and the time consumed for successful registration is mainly affected by the size of the model file.
Once the model registration is complete, you can call specific functions and perform model inference by using normal queries.
4.2 Viewing Models
Successfully registered models can be queried for model-specific information through the show models command. The SQL definition is as follows:
show models
show models <model_name>In addition to displaying information about all models directly, you can specify a model id to view information about a specific model. The results of the model show contain the following information:
| ModelId | State | Configs | Attributes |
|---|---|---|---|
| Model Unique Identifier | Model Registration Status (LOADING, ACTIVE, DROPPING) | InputShape, outputShapeInputTypes, outputTypes | Model Notes |
State is used to show the current state of model registration, which consists of the following three stages
- LOADING: The corresponding model meta information has been added to the configNode, and the model file is being transferred to the AINode node.
- ACTIVE: The model has been set up and the model is in the available state
- DROPPING: Model deletion is in progress, model related information is being deleted from configNode and AINode.
- UNAVAILABLE: Model creation failed, you can delete the failed model_name by drop model.
Example
IoTDB> show models
+---------------------+--------------------------+-----------+----------------------------+-----------------------+
| ModelId| ModelType| State| Configs| Notes|
+---------------------+--------------------------+-----------+----------------------------+-----------------------+
| dlinear_example| USER_DEFINED| ACTIVE| inputShape:[96,2]| |
| | | | outputShape:[48,2]| |
| | | | inputDataType:[float,float]| |
| | | |outputDataType:[float,float]| |
| _STLForecaster| BUILT_IN_FORECAST| ACTIVE| |Built-in model in IoTDB|
| _NaiveForecaster| BUILT_IN_FORECAST| ACTIVE| |Built-in model in IoTDB|
| _ARIMA| BUILT_IN_FORECAST| ACTIVE| |Built-in model in IoTDB|
|_ExponentialSmoothing| BUILT_IN_FORECAST| ACTIVE| |Built-in model in IoTDB|
| _GaussianHMM|BUILT_IN_ANOMALY_DETECTION| ACTIVE| |Built-in model in IoTDB|
| _GMMHMM|BUILT_IN_ANOMALY_DETECTION| ACTIVE| |Built-in model in IoTDB|
| _Stray|BUILT_IN_ANOMALY_DETECTION| ACTIVE| |Built-in model in IoTDB|
+---------------------+--------------------------+-----------+------------------------------------------------------------+-----------------------+We have registered the corresponding model earlier, you can view the model status through the corresponding designation, active indicates that the model is successfully registered and can be used for inference.
4.3 Delete Model
For a successfully registered model, the user can delete it via SQL. In addition to deleting the meta information on the configNode, this operation also deletes all the related model files under the AINode. The SQL is as follows:
drop model <model_name>You need to specify the model model_name that has been successfully registered to delete the corresponding model. Since model deletion involves the deletion of data on multiple nodes, the operation will not be completed immediately, and the state of the model at this time is DROPPING, and the model in this state cannot be used for model inference.
4.4 Using Built-in Model Reasoning
The SQL syntax is as follows:
call inference(<built_in_model_name>,sql[,<parameterName>=<parameterValue>])Built-in model inference does not require a registration process, the inference function can be used by calling the inference function through the call keyword, and its corresponding parameters are described as follows:
- built_in_model_name: built-in model name
- parameterName: parameter name
- parameterValue: parameter value
Built-in Models and Parameter Descriptions
The following machine learning models are currently built-in, please refer to the following links for detailed parameter descriptions.
| Model | built_in_model_name | Task type | Parameter description |
|---|---|---|---|
| Arima | _Arima | Forecast | Arima Parameter description |
| STLForecaster | _STLForecaster | Forecast | STLForecaster Parameter description |
| NaiveForecaster | _NaiveForecaster | Forecast | NaiveForecaster Parameter description |
| ExponentialSmoothing | _ExponentialSmoothing | Forecast | ExponentialSmoothing 参Parameter description |
| GaussianHMM | _GaussianHMM | Annotation | GaussianHMMParameter description |
| GMMHMM | _GMMHMM | Annotation | GMMHMM参数说明 |
| Stray | _Stray | Anomaly detection | Stray Parameter description |
Example
The following is an example of an operation using built-in model inference. The built-in Stray model is used for anomaly detection algorithm. The input is [144,1] and the output is [144,1]. We use it for reasoning through SQL.
IoTDB> select * from root.eg.airline
+-----------------------------+------------------+
| Time|root.eg.airline.s0|
+-----------------------------+------------------+
|1949-01-31T00:00:00.000+08:00| 224.0|
|1949-02-28T00:00:00.000+08:00| 118.0|
|1949-03-31T00:00:00.000+08:00| 132.0|
|1949-04-30T00:00:00.000+08:00| 129.0|
......
|1960-09-30T00:00:00.000+08:00| 508.0|
|1960-10-31T00:00:00.000+08:00| 461.0|
|1960-11-30T00:00:00.000+08:00| 390.0|
|1960-12-31T00:00:00.000+08:00| 432.0|
+-----------------------------+------------------+
Total line number = 144
IoTDB> call inference(_Stray, "select s0 from root.eg.airline", k=2)
+-------+
|output0|
+-------+
| 0|
| 0|
| 0|
| 0|
......
| 1|
| 1|
| 0|
| 0|
| 0|
| 0|
+-------+
Total line number = 1444.5 Reasoning with Deep Learning Models
The SQL syntax is as follows:
call inference(<model_name>,sql[,window=<window_function>])
window_function:
head(window_size)
tail(window_size)
count(window_size,sliding_step)After completing the registration of the model, the inference function can be used by calling the inference function through the call keyword, and its corresponding parameters are described as follows:
- model_name: corresponds to a registered model
- sql: sql query statement, the result of the query is used as input to the model for model inference. The dimensions of the rows and columns in the result of the query need to match the size specified in the specific model config. (It is not recommended to use the
SELECT *clause for the sql here because in IoTDB,*does not sort the columns, so the order of the columns is undefined, you can useSELECT s0,s1to ensure that the columns order matches the expectations of the model input) - window_function: Window functions that can be used in the inference process, there are currently three types of window functions provided to assist in model inference:
head(window_size): Get the top window_size points in the data for model inference, this window can be used for data cropping.
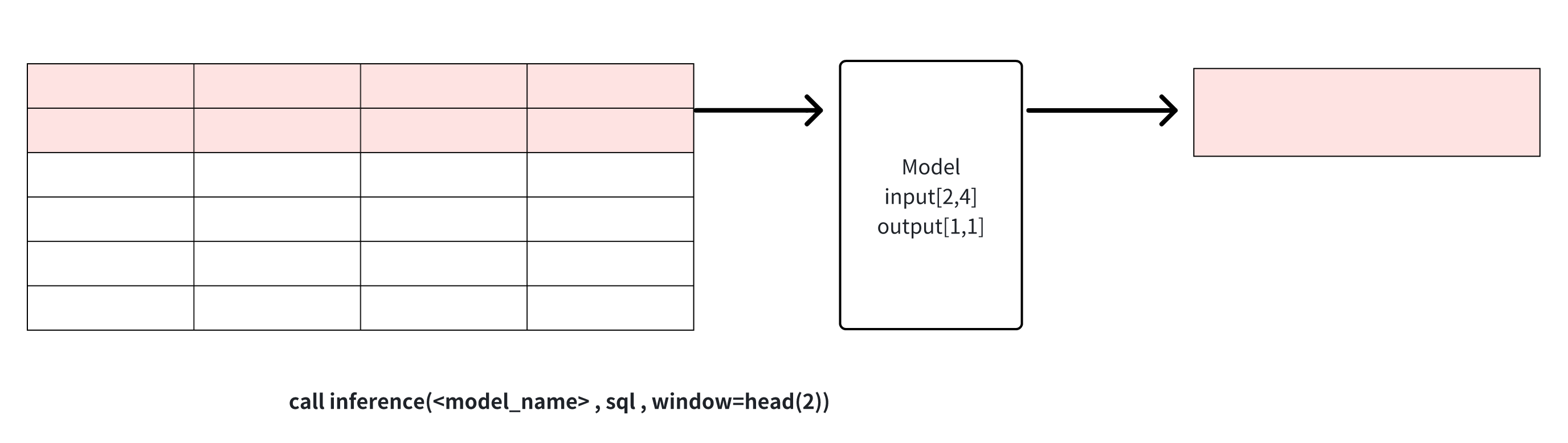
tail(window_size): get the last window_size point in the data for model inference, this window can be used for data cropping.
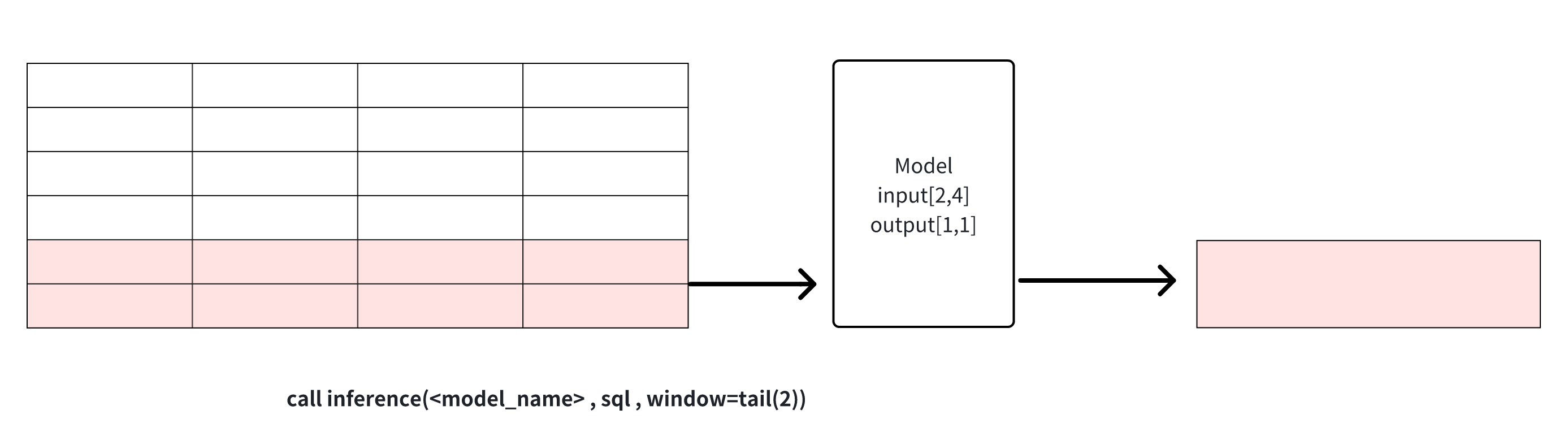
count(window_size, sliding_step): sliding window based on the number of points, the data in each window will be reasoned through the model respectively, as shown in the example below, window_size for 2 window function will be divided into three windows of the input dataset, and each window will perform reasoning operations to generate results respectively. The window can be used for continuous inference
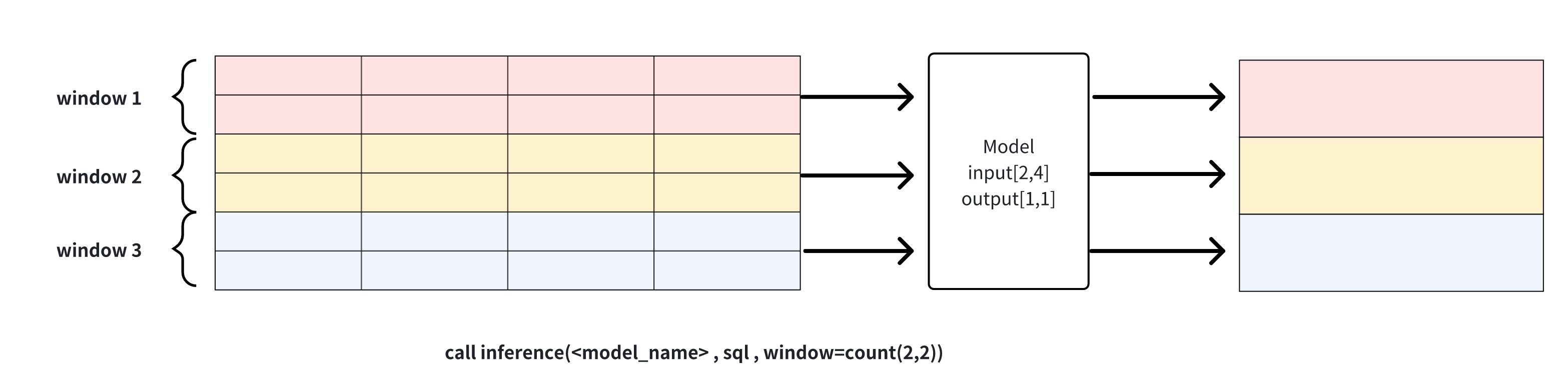
Explanation 1: window can be used to solve the problem of cropping rows when the results of the sql query and the input row requirements of the model do not match. Note that when the number of columns does not match or the number of rows is directly less than the model requirement, the inference cannot proceed and an error message will be returned.
Explanation 2: In deep learning applications, timestamp-derived features (time columns in the data) are often used as covariates in generative tasks, and are input into the model together to enhance the model, but the time columns are generally not included in the model's output. In order to ensure the generality of the implementation, the model inference results only correspond to the real output of the model, if the model does not output the time column, it will not be included in the results.
Example
The following is an example of inference in action using a deep learning model, for the dlinear prediction model with input [96,2] and output [48,2] mentioned above, which we use via SQL.
IoTDB> select s1,s2 from root.**
+-----------------------------+-------------------+-------------------+
| Time| root.eg.etth.s0| root.eg.etth.s1|
+-----------------------------+-------------------+-------------------+
|1990-01-01T00:00:00.000+08:00| 0.7855| 1.611|
|1990-01-02T00:00:00.000+08:00| 0.7818| 1.61|
|1990-01-03T00:00:00.000+08:00| 0.7867| 1.6293|
|1990-01-04T00:00:00.000+08:00| 0.786| 1.637|
|1990-01-05T00:00:00.000+08:00| 0.7849| 1.653|
|1990-01-06T00:00:00.000+08:00| 0.7866| 1.6537|
|1990-01-07T00:00:00.000+08:00| 0.7886| 1.662|
......
|1990-03-31T00:00:00.000+08:00| 0.7585| 1.678|
|1990-04-01T00:00:00.000+08:00| 0.7587| 1.6763|
|1990-04-02T00:00:00.000+08:00| 0.76| 1.6813|
|1990-04-03T00:00:00.000+08:00| 0.7669| 1.684|
|1990-04-04T00:00:00.000+08:00| 0.7645| 1.677|
|1990-04-05T00:00:00.000+08:00| 0.7625| 1.68|
|1990-04-06T00:00:00.000+08:00| 0.7617| 1.6917|
+-----------------------------+-------------------+-------------------+
Total line number = 96
IoTDB> call inference(dlinear_example,"select s0,s1 from root.**")
+--------------------------------------------+-----------------------------+
| _result_0| _result_1|
+--------------------------------------------+-----------------------------+
| 0.726302981376648| 1.6549958229064941|
| 0.7354921698570251| 1.6482787370681763|
| 0.7238251566886902| 1.6278168201446533|
......
| 0.7692174911499023| 1.654654049873352|
| 0.7685555815696716| 1.6625318765640259|
| 0.7856493592262268| 1.6508299350738525|
+--------------------------------------------+-----------------------------+
Total line number = 48Example of using the tail/head window function
When the amount of data is variable and you want to take the latest 96 rows of data for inference, you can use the corresponding window function tail. head function is used in a similar way, except that it takes the earliest 96 points.
IoTDB> select s1,s2 from root.**
+-----------------------------+-------------------+-------------------+
| Time| root.eg.etth.s0| root.eg.etth.s1|
+-----------------------------+-------------------+-------------------+
|1988-01-01T00:00:00.000+08:00| 0.7355| 1.211|
......
|1990-01-01T00:00:00.000+08:00| 0.7855| 1.611|
|1990-01-02T00:00:00.000+08:00| 0.7818| 1.61|
|1990-01-03T00:00:00.000+08:00| 0.7867| 1.6293|
|1990-01-04T00:00:00.000+08:00| 0.786| 1.637|
|1990-01-05T00:00:00.000+08:00| 0.7849| 1.653|
|1990-01-06T00:00:00.000+08:00| 0.7866| 1.6537|
|1990-01-07T00:00:00.000+08:00| 0.7886| 1.662|
......
|1990-03-31T00:00:00.000+08:00| 0.7585| 1.678|
|1990-04-01T00:00:00.000+08:00| 0.7587| 1.6763|
|1990-04-02T00:00:00.000+08:00| 0.76| 1.6813|
|1990-04-03T00:00:00.000+08:00| 0.7669| 1.684|
|1990-04-04T00:00:00.000+08:00| 0.7645| 1.677|
|1990-04-05T00:00:00.000+08:00| 0.7625| 1.68|
|1990-04-06T00:00:00.000+08:00| 0.7617| 1.6917|
+-----------------------------+-------------------+-------------------+
Total line number = 996
IoTDB> call inference(dlinear_example,"select s0,s1 from root.**",window=tail(96))
+--------------------------------------------+-----------------------------+
| _result_0| _result_1|
+--------------------------------------------+-----------------------------+
| 0.726302981376648| 1.6549958229064941|
| 0.7354921698570251| 1.6482787370681763|
| 0.7238251566886902| 1.6278168201446533|
......
| 0.7692174911499023| 1.654654049873352|
| 0.7685555815696716| 1.6625318765640259|
| 0.7856493592262268| 1.6508299350738525|
+--------------------------------------------+-----------------------------+
Total line number = 48Example of using the count window function
This window is mainly used for computational tasks. When the task's corresponding model can only handle a fixed number of rows of data at a time, but the final desired outcome is multiple sets of prediction results, this window function can be used to perform continuous inference using a sliding window of points. Suppose we now have an anomaly detection model anomaly_example(input: [24,2], output[1,1]), which generates a 0/1 label for every 24 rows of data. An example of its use is as follows:
IoTDB> select s1,s2 from root.**
+-----------------------------+-------------------+-------------------+
| Time| root.eg.etth.s0| root.eg.etth.s1|
+-----------------------------+-------------------+-------------------+
|1990-01-01T00:00:00.000+08:00| 0.7855| 1.611|
|1990-01-02T00:00:00.000+08:00| 0.7818| 1.61|
|1990-01-03T00:00:00.000+08:00| 0.7867| 1.6293|
|1990-01-04T00:00:00.000+08:00| 0.786| 1.637|
|1990-01-05T00:00:00.000+08:00| 0.7849| 1.653|
|1990-01-06T00:00:00.000+08:00| 0.7866| 1.6537|
|1990-01-07T00:00:00.000+08:00| 0.7886| 1.662|
......
|1990-03-31T00:00:00.000+08:00| 0.7585| 1.678|
|1990-04-01T00:00:00.000+08:00| 0.7587| 1.6763|
|1990-04-02T00:00:00.000+08:00| 0.76| 1.6813|
|1990-04-03T00:00:00.000+08:00| 0.7669| 1.684|
|1990-04-04T00:00:00.000+08:00| 0.7645| 1.677|
|1990-04-05T00:00:00.000+08:00| 0.7625| 1.68|
|1990-04-06T00:00:00.000+08:00| 0.7617| 1.6917|
+-----------------------------+-------------------+-------------------+
Total line number = 96
IoTDB> call inference(anomaly_example,"select s0,s1 from root.**",window=count(24,24))
+-------------------------+
| _result_0|
+-------------------------+
| 0|
| 1|
| 1|
| 0|
+-------------------------+
Total line number = 4In the result set, each row's label corresponds to the output of the anomaly detection model after inputting each group of 24 rows of data.
5. Privilege Management
When using AINode related functions, the authentication of IoTDB itself can be used to do a permission management, users can only use the model management related functions when they have the USE_MODEL permission. When using the inference function, the user needs to have the permission to access the source sequence corresponding to the SQL of the input model.
| Privilege Name | Privilege Scope | Administrator User (default ROOT) | Normal User | Path Related |
|---|---|---|---|---|
| USE_MODEL | create model/show models/drop model | √ | √ | x |
| READ_DATA | call inference | √ | √ | √ |
6. Practical Examples
6.1 Power Load Prediction
In some industrial scenarios, there is a need to predict power loads, which can be used to optimise power supply, conserve energy and resources, support planning and expansion, and enhance power system reliability.
The data for the test set of ETTh1 that we use is ETTh1.
It contains power data collected at 1h intervals, and each data consists of load and oil temperature as High UseFul Load, High UseLess Load, Middle UseLess Load, Low UseFul Load, Low UseLess Load, Oil Temperature.
On this dataset, the model inference function of IoTDB-ML can predict the oil temperature in the future period of time through the relationship between the past values of high, middle and low use loads and the corresponding time stamp oil temperature, which empowers the automatic regulation and monitoring of grid transformers.
Step 1: Data Import
Users can import the ETT dataset into IoTDB using import-csv.sh in the tools folder
Bash bash . /import-csv.sh -h 127.0.0.1 -p 6667 -u root -pw root -f ... /... /ETTh1.csv
Step 2: Model Import
We can enter the following SQL in iotdb-cli to pull a trained model from huggingface for registration for subsequent inference.
create model dlinear using uri 'https://huggingface.co/hvlgo/dlinear/tree/main'This model is trained on the lighter weight deep model DLinear, which is able to capture as many trends within a sequence and relationships between variables as possible with relatively fast inference, making it more suitable for fast real-time prediction than other deeper models.
Step 3: Model inference
IoTDB> select s0,s1,s2,s3,s4,s5,s6 from root.eg.etth LIMIT 96
+-----------------------------+---------------+---------------+---------------+---------------+---------------+---------------+---------------+
| Time|root.eg.etth.s0|root.eg.etth.s1|root.eg.etth.s2|root.eg.etth.s3|root.eg.etth.s4|root.eg.etth.s5|root.eg.etth.s6|
+-----------------------------+---------------+---------------+---------------+---------------+---------------+---------------+---------------+
|2017-10-20T00:00:00.000+08:00| 10.449| 3.885| 8.706| 2.025| 2.041| 0.944| 8.864|
|2017-10-20T01:00:00.000+08:00| 11.119| 3.952| 8.813| 2.31| 2.071| 1.005| 8.442|
|2017-10-20T02:00:00.000+08:00| 9.511| 2.88| 7.533| 1.564| 1.949| 0.883| 8.16|
|2017-10-20T03:00:00.000+08:00| 9.645| 2.21| 7.249| 1.066| 1.828| 0.914| 7.949|
......
|2017-10-23T20:00:00.000+08:00| 8.105| 0.938| 4.371| -0.569| 3.533| 1.279| 9.708|
|2017-10-23T21:00:00.000+08:00| 7.167| 1.206| 4.087| -0.462| 3.107| 1.432| 8.723|
|2017-10-23T22:00:00.000+08:00| 7.1| 1.34| 4.015| -0.32| 2.772| 1.31| 8.864|
|2017-10-23T23:00:00.000+08:00| 9.176| 2.746| 7.107| 1.635| 2.65| 1.097| 9.004|
+-----------------------------+---------------+---------------+---------------+---------------+---------------+---------------+---------------+
Total line number = 96
IoTDB> call inference(dlinear_example, "select s0,s1,s2,s3,s4,s5,s6 from root.eg.etth", window=head(96))
+-----------+----------+----------+------------+---------+----------+----------+
| output0| output1| output2| output3| output4| output5| output6|
+-----------+----------+----------+------------+---------+----------+----------+
| 10.319546| 3.1450553| 7.877341| 1.5723765|2.7303758| 1.1362307| 8.867775|
| 10.443649| 3.3286757| 7.8593454| 1.7675098| 2.560634| 1.1177158| 8.920919|
| 10.883752| 3.2341104| 8.47036| 1.6116762|2.4874182| 1.1760603| 8.798939|
......
| 8.0115595| 1.2995274| 6.9900327|-0.098746896| 3.04923| 1.176214| 9.548782|
| 8.612427| 2.5036244| 5.6790237| 0.66474205|2.8870275| 1.2051733| 9.330128|
| 10.096699| 3.399722| 6.9909| 1.7478468|2.7642853| 1.1119363| 9.541455|
+-----------+----------+----------+------------+---------+----------+----------+
Total line number = 48We compare the results of the prediction of the oil temperature with the real results, and we can get the following image.
The data before 10/24 00:00 represents the past data input to the model, the blue line after 10/24 00:00 is the oil temperature forecast result given by the model, and the red line is the actual oil temperature data from the dataset (used for comparison).
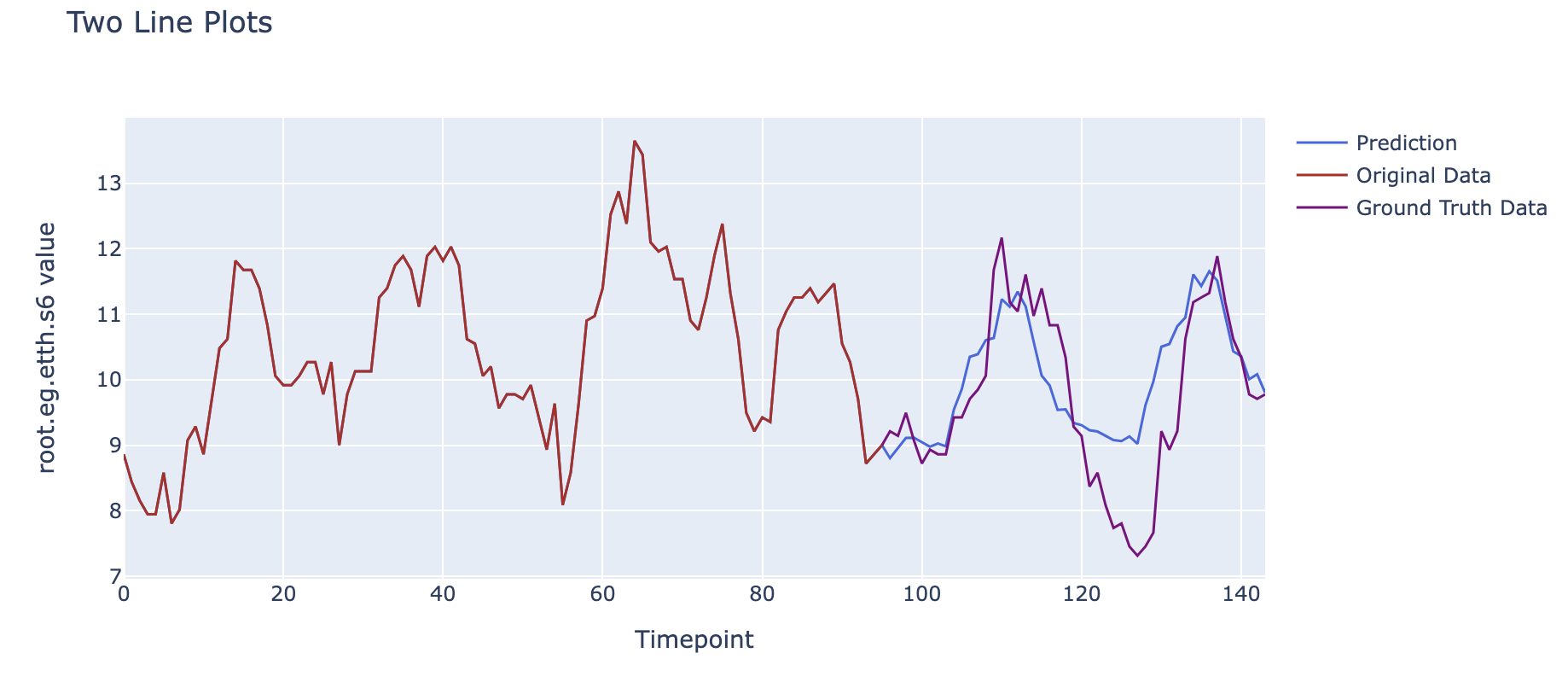
As can be seen, we have used the relationship between the six load information and the corresponding time oil temperatures for the past 96 hours (4 days) to model the possible changes in this data for the oil temperature for the next 48 hours (2 days) based on the inter-relationships between the sequences learned previously, and it can be seen that the predicted curves maintain a high degree of consistency in trend with the actual results after visualisation.
6.2 Power Prediction
Power monitoring of current, voltage and power data is required in substations for detecting potential grid problems, identifying faults in the power system, effectively managing grid loads and analysing power system performance and trends.
We have used the current, voltage and power data in a substation to form a dataset in a real scenario. The dataset consists of data such as A-phase voltage, B-phase voltage, and C-phase voltage collected every 5 - 6s for a time span of nearly four months in the substation.
The test set data content is data.
On this dataset, the model inference function of IoTDB-ML can predict the C-phase voltage in the future period through the previous values and corresponding timestamps of A-phase voltage, B-phase voltage and C-phase voltage, empowering the monitoring management of the substation.
Step 1: Data Import
Users can import the dataset using import-csv.sh in the tools folder
bash ./import-csv.sh -h 127.0.0.1 -p 6667 -u root -pw root -f ... /... /data.csvStep 2: Model Import
We can select built-in models or registered models in IoTDB CLI for subsequent inference.
We use the built-in model STLForecaster for prediction. STLForecaster is a time series forecasting method based on the STL implementation in the statsmodels library.
Step 3: Model Inference
IoTDB> select * from root.eg.voltage limit 96
+-----------------------------+------------------+------------------+------------------+
| Time|root.eg.voltage.s0|root.eg.voltage.s1|root.eg.voltage.s2|
+-----------------------------+------------------+------------------+------------------+
|2023-02-14T20:38:32.000+08:00| 2038.0| 2028.0| 2041.0|
|2023-02-14T20:38:38.000+08:00| 2014.0| 2005.0| 2018.0|
|2023-02-14T20:38:44.000+08:00| 2014.0| 2005.0| 2018.0|
......
|2023-02-14T20:47:52.000+08:00| 2024.0| 2016.0| 2027.0|
|2023-02-14T20:47:57.000+08:00| 2024.0| 2016.0| 2027.0|
|2023-02-14T20:48:03.000+08:00| 2024.0| 2016.0| 2027.0|
+-----------------------------+------------------+------------------+------------------+
Total line number = 96
IoTDB> call inference(_STLForecaster, "select s0,s1,s2 from root.eg.voltage", window=head(96),predict_length=48)
+---------+---------+---------+
| output0| output1| output2|
+---------+---------+---------+
|2026.3601|2018.2953|2029.4257|
|2019.1538|2011.4361|2022.0888|
|2025.5074|2017.4522|2028.5199|
......
|2022.2336|2015.0290|2025.1023|
|2015.7241|2008.8975|2018.5085|
|2022.0777|2014.9136|2024.9396|
|2015.5682|2008.7821|2018.3458|
+---------+---------+---------+
Total line number = 48Comparing the predicted results of the C-phase voltage with the real results, we can get the following image.
The data before 02/14 20:48 represents the past data input to the model, the blue line after 02/14 20:48 is the predicted result of phase C voltage given by the model, while the red line is the actual phase C voltage data from the dataset (used for comparison).
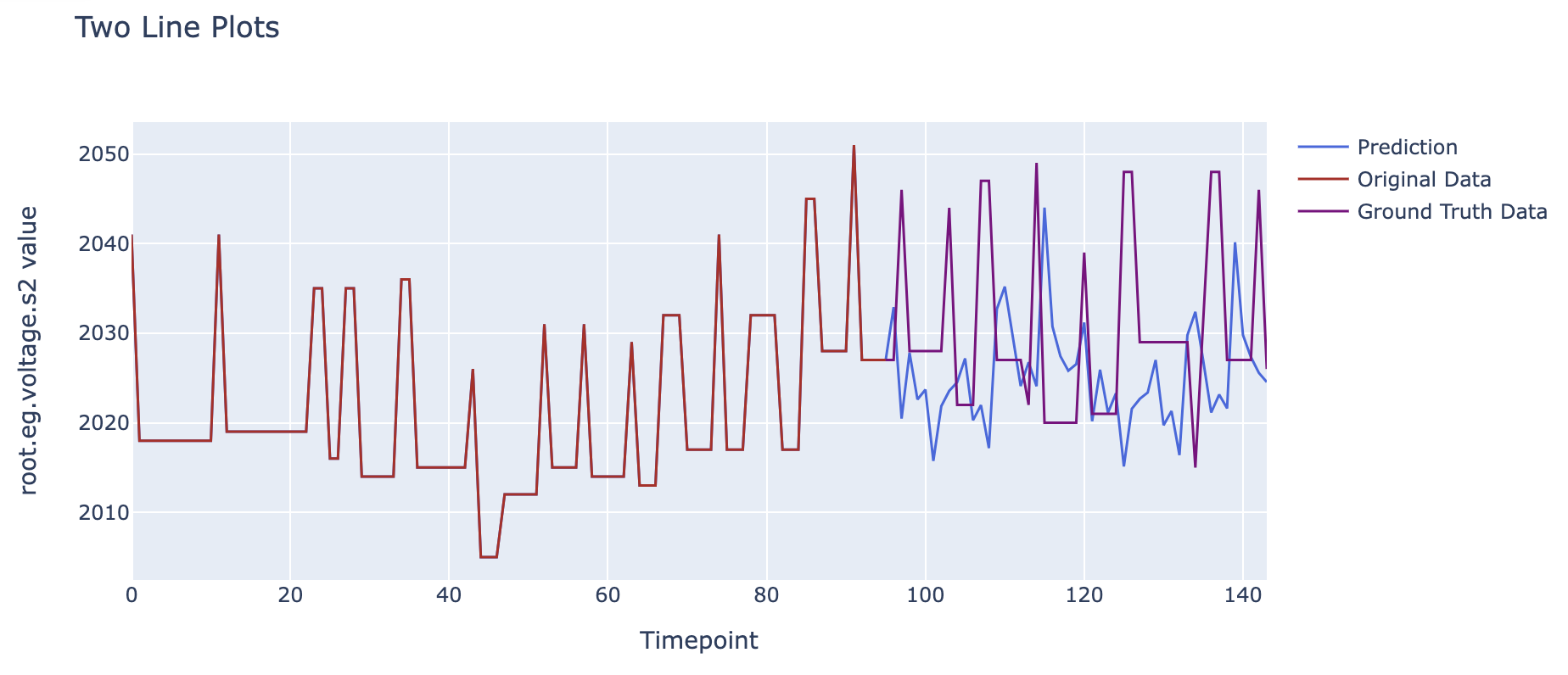
It can be seen that we used the voltage data from the past 10 minutes and, based on the previously learned inter-sequence relationships, modeled the possible changes in the phase C voltage data for the next 5 minutes. The visualized forecast curve shows a certain degree of synchronicity with the actual results in terms of trend.
6.3 Anomaly Detection
In the civil aviation and transport industry, there exists a need for anomaly detection of the number of passengers travelling on an aircraft. The results of anomaly detection can be used to guide the adjustment of flight scheduling to make the organisation more efficient.
Airline Passengers is a time-series dataset that records the number of international air passengers between 1949 and 1960, sampled at one-month intervals. The dataset contains a total of one time series. The dataset is airline.
On this dataset, the model inference function of IoTDB-ML can empower the transport industry by capturing the changing patterns of the sequence in order to detect anomalies at the sequence time points.
Step 1: Data Import
Users can import the dataset using import-csv.sh in the tools folder
Bash bash . /import-csv.sh -h 127.0.0.1 -p 6667 -u root -pw root -f ... /... /data.csv
Step 2: Model Inference
IoTDB has some built-in machine learning algorithms that can be used directly, a sample prediction using one of the anomaly detection algorithms is shown below:
IoTDB> select * from root.eg.airline
+-----------------------------+------------------+
| Time|root.eg.airline.s0|
+-----------------------------+------------------+
|1949-01-31T00:00:00.000+08:00| 224.0|
|1949-02-28T00:00:00.000+08:00| 118.0|
|1949-03-31T00:00:00.000+08:00| 132.0|
|1949-04-30T00:00:00.000+08:00| 129.0|
......
|1960-09-30T00:00:00.000+08:00| 508.0|
|1960-10-31T00:00:00.000+08:00| 461.0|
|1960-11-30T00:00:00.000+08:00| 390.0|
|1960-12-31T00:00:00.000+08:00| 432.0|
+-----------------------------+------------------+
Total line number = 144
IoTDB> call inference(_Stray, "select s0 from root.eg.airline", k=2)
+-------+
|output0|
+-------+
| 0|
| 0|
| 0|
| 0|
......
| 1|
| 1|
| 0|
| 0|
| 0|
| 0|
+-------+
Total line number = 144We plot the results detected as anomalies to get the following image. Where the blue curve is the original time series and the time points specially marked with red dots are the time points that the algorithm detects as anomalies.
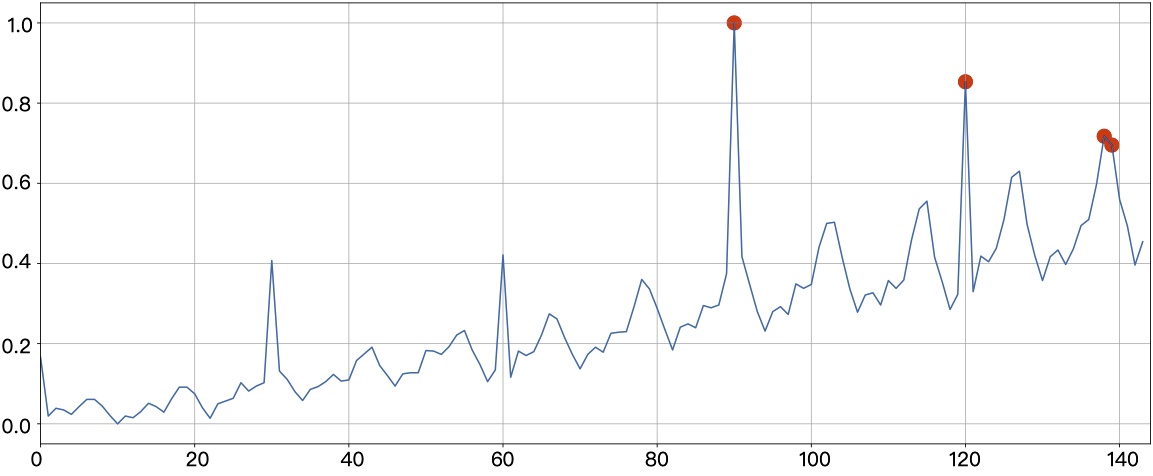
It can be seen that the Stray model has modelled the input sequence changes and successfully detected the time points where anomalies occur.