
Data Synchronisation
Data Synchronisation
Data synchronization is a typical requirement in industrial Internet of Things (IoT). Through data synchronization mechanisms, it is possible to achieve data sharing between IoTDB, and to establish a complete data link to meet the needs for internal and external network data interconnectivity, edge-cloud synchronization, data migration, and data backup.
Function Overview
Data Synchronization
A data synchronization task consists of three stages:
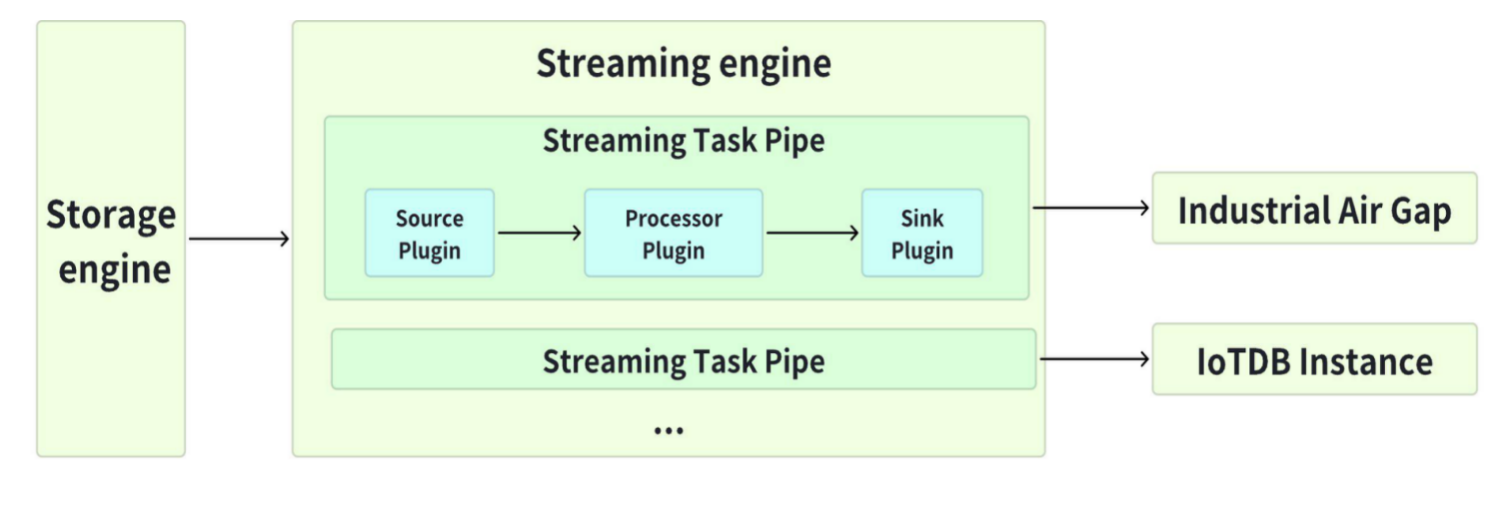
- Source Stage:This part is used to extract data from the source IoTDB, defined in the source section of the SQL statement.
- Process Stage:This part is used to process the data extracted from the source IoTDB, defined in the processor section of the SQL statement.
- Sink Stage:This part is used to send data to the target IoTDB, defined in the sink section of the SQL statement.
By declaratively configuring the specific content of the three parts through SQL statements, flexible data synchronization capabilities can be achieved. Currently, data synchronization supports the synchronization of the following information, and you can select the synchronization scope when creating a synchronization task (the default is data.insert, which means synchronizing newly written data):
| Synchronization Scope | Synchronization Content | Description |
|---|---|---|
| all | All scopes | |
| data(Data) | insert | Synchronize newly written data |
| delete | Synchronize deleted data | |
| schema | database | Synchronize database creation, modification or deletion operations |
| timeseries | Synchronize the definition and attributes of time series | |
| TTL | Synchronize the data retention time | |
| auth | - | Synchronize user permissions and access control |
Functional limitations and instructions
The schema and auth synchronization functions have the following limitations:
When using schema synchronization, it is required that the consensus protocol for
Schema regionandConfigNodemust be the default ratis protocol. This means that theiotdb-system.propertiesconfiguration file should contain the settingsconfig_node_consensus_protocol_class=org.apache.iotdb.consensus.ratis.RatisConsensusandschema_region_consensus_protocol_class=org.apache.iotdb.consensus.ratis.RatisConsensus. If these are not specified, the default ratis protocol is used.To prevent potential conflicts, please disable the automatic creation of schema on the receiving end when enabling schema synchronization. This can be done by setting the
enable_auto_create_schemaconfiguration in theiotdb-system.propertiesfile to false.When schema synchronization is enabled, the use of custom plugins is not supported.
During data synchronization tasks, please avoid performing any deletion operations to prevent inconsistent states between the two ends.
Usage Instructions
Data synchronization tasks have three states: RUNNING, STOPPED, and DROPPED. The task state transitions are shown in the following diagram:
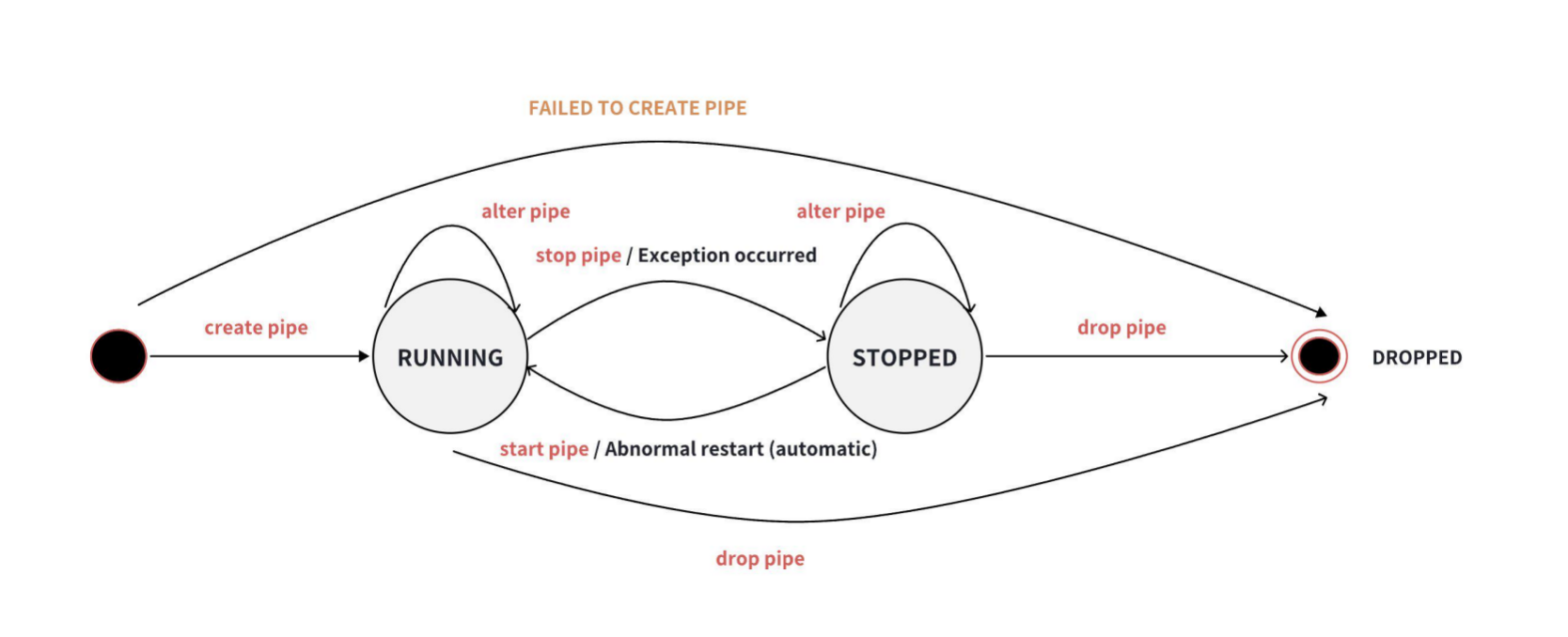
After creation, the task will start directly, and when the task stops abnormally, the system will automatically attempt to restart the task.
Provide the following SQL statements for state management of synchronization tasks.
Create Task
Use the CREATE PIPE statement to create a data synchronization task. The PipeId and sink attributes are required, while source and processor are optional. When entering the SQL, note that the order of the SOURCE and SINK plugins cannot be swapped.
The SQL example is as follows:
CREATE PIPE [IF NOT EXISTS] <PipeId> -- PipeId is the name that uniquely identifies the task.
-- Data extraction plugin, optional plugin
WITH SOURCE (
[<parameter> = <value>,],
)
-- Data processing plugin, optional plugin
WITH PROCESSOR (
[<parameter> = <value>,],
)
-- Data connection plugin, required plugin
WITH SINK (
[<parameter> = <value>,],
)
IF NOT EXISTS semantics: Used in creation operations to ensure that the create command is executed when the specified Pipe does not exist, preventing errors caused by attempting to create an existing Pipe.
Start Task
Start processing data:
START PIPE<PipeId>
Stop Task
Stop processing data:
STOP PIPE <PipeId>
Delete Task
Deletes the specified task:
DROP PIPE [IF EXISTS] <PipeId>
IF EXISTS semantics: Used in deletion operations to ensure that when a specified Pipe exists, the delete command is executed to prevent errors caused by attempting to delete non-existent Pipes.
Deleting a task does not require stopping the synchronization task first.
View Task
View all tasks:
SHOW PIPES
To view a specified task:
SHOW PIPE <PipeId>
Example of the show pipes result for a pipe:
+--------------------------------+-----------------------+-------+----------+-------------+-----------------------------------------------------------+----------------+-------------------+-------------------------+
| ID| CreationTime| State|PipeSource|PipeProcessor| PipeSink|ExceptionMessage|RemainingEventCount|EstimatedRemainingSeconds|
+--------------------------------+-----------------------+-------+----------+-------------+-----------------------------------------------------------+----------------+-------------------+-------------------------+
|59abf95db892428b9d01c5fa318014ea|2024-06-17T14:03:44.189|RUNNING| {}| {}|{sink=iotdb-thrift-sink, sink.ip=127.0.0.1, sink.port=6668}| | 128| 1.03|
+--------------------------------+-----------------------+-------+----------+-------------+-----------------------------------------------------------+----------------+-------------------+-------------------------+
The meanings of each column are as follows:
- ID:The unique identifier for the synchronization task
- CreationTime:The time when the synchronization task was created
- State:The state of the synchronization task
- PipeSource:The source of the synchronized data stream
- PipeProcessor:The processing logic of the synchronized data stream during transmission
- PipeSink:The destination of the synchronized data stream
- ExceptionMessage:Displays the exception information of the synchronization task
- RemainingEventCount (Statistics with Delay): The number of remaining events, which is the total count of all events in the current data synchronization task, including data and schema synchronization events, as well as system and user-defined events.
- EstimatedRemainingSeconds (Statistics with Delay): The estimated remaining time, based on the current number of events and the rate at the pipe, to complete the transfer.
Synchronization Plugins
To make the overall architecture more flexible to match different synchronization scenario requirements, we support plugin assembly within the synchronization task framework. The system comes with some pre-installed common plugins that you can use directly. At the same time, you can also customize processor plugins and Sink plugins, and load them into the IoTDB system for use. You can view the plugins in the system (including custom and built-in plugins) with the following statement:
SHOW PIPEPLUGINS
The return result is as follows (version 1.3.2):
IoTDB> SHOW PIPEPLUGINS
+------------------------------+----------+--------------------------------------------------------------------------------------------------+----------------------------------------------------+
| PluginName|PluginType| ClassName| PluginJar|
+------------------------------+----------+--------------------------------------------------------------------------------------------------+----------------------------------------------------+
| DO-NOTHING-PROCESSOR| Builtin| org.apache.iotdb.commons.pipe.plugin.builtin.processor.donothing.DoNothingProcessor| |
| DO-NOTHING-SINK| Builtin| org.apache.iotdb.commons.pipe.plugin.builtin.connector.donothing.DoNothingConnector| |
| IOTDB-SOURCE| Builtin| org.apache.iotdb.commons.pipe.plugin.builtin.extractor.iotdb.IoTDBExtractor| |
| IOTDB-THRIFT-SINK| Builtin| org.apache.iotdb.commons.pipe.plugin.builtin.connector.iotdb.thrift.IoTDBThriftConnector| |
| IOTDB-THRIFT-SSL-SINK| Builtin| org.apache.iotdb.commons.pipe.plugin.builtin.connector.iotdb.thrift.IoTDBThriftSslConnector| |
+------------------------------+----------+--------------------------------------------------------------------------------------------------+----------------------------------------------------+
Detailed introduction of pre-installed plugins is as follows (for detailed parameters of each plugin, please refer to the Parameter Description section):
| Type | Custom Plugin | Plugin Name | Description | Applicable Version |
|---|---|---|---|---|
| source plugin | Not Supported | iotdb-source | The default extractor plugin, used to extract historical or real-time data from IoTDB | 1.2.x |
| processor plugin | Supported | do-nothing-processor | The default processor plugin, which does not process the incoming data | 1.2.x |
| sink plugin | Supported | do-nothing-sink | Does not process the data that is sent out | 1.2.x |
| iotdb-thrift-sink | The default sink plugin ( V1.3.1+ ), used for data transfer between IoTDB ( V1.2.0+ ) and IoTDB( V1.2.0+ ) . It uses the Thrift RPC framework to transfer data, with a multi-threaded async non-blocking IO model, high transfer performance, especially suitable for scenarios where the target end is distributed | 1.2.x | ||
| iotdb-thrift-ssl-sink | Used for data transfer between IoTDB ( V1.3.1+ ) and IoTDB ( V1.2.0+ ). It uses the Thrift RPC framework to transfer data, with a single-threaded sync blocking IO model, suitable for scenarios with higher security requirements | 1.3.1+ |
For importing custom plugins, please refer to the Stream Processing section.
Use examples
Full data synchronisation
This example is used to demonstrate the synchronisation of all data from one IoTDB to another IoTDB with the data link as shown below:

In this example, we can create a synchronization task named A2B to synchronize the full data from A IoTDB to B IoTDB. The iotdb-thrift-sink plugin (built-in plugin) for the sink is required. The URL of the data service port of the DataNode node on the target IoTDB needs to be configured through node-urls, as shown in the following example statement:
create pipe A2B
with sink (
'sink'='iotdb-thrift-sink',
'node-urls' = '127.0.0.1:6668', -- The URL of the data service port of the DataNode node on the target IoTDB
Partial data synchronization
This example is used to demonstrate the synchronisation of data from a certain historical time range (8:00pm 23 August 2023 to 8:00pm 23 October 2023) to another IoTDB, the data link is shown below:

In this example, we can create a synchronization task named A2B. First, we need to define the range of data to be transferred in the source. Since the data being transferred is historical data (historical data refers to data that existed before the creation of the synchronization task), we need to configure the start-time and end-time of the data and the transfer mode mode. The URL of the data service port of the DataNode node on the target IoTDB needs to be configured through node-urls.
The detailed statements are as follows:
create pipe A2B
WITH SOURCE (
'source'= 'iotdb-source',
'realtime.mode' = 'stream' -- The extraction mode for newly inserted data (after pipe creation)
'start-time' = '2023.08.23T08:00:00+00:00', -- The start event time for synchronizing all data, including start-time
'end-time' = '2023.10.23T08:00:00+00:00' -- The end event time for synchronizing all data, including end-time
)
with SINK (
'sink'='iotdb-thrift-async-sink',
'node-urls' = '127.0.0.1:6668', -- The URL of the data service port of the DataNode node on the target IoTDB
)
Edge-cloud data transfer
This example is used to demonstrate the scenario where data from multiple IoTDB is transferred to the cloud, with data from clusters B, C, and D all synchronized to cluster A, as shown in the figure below:
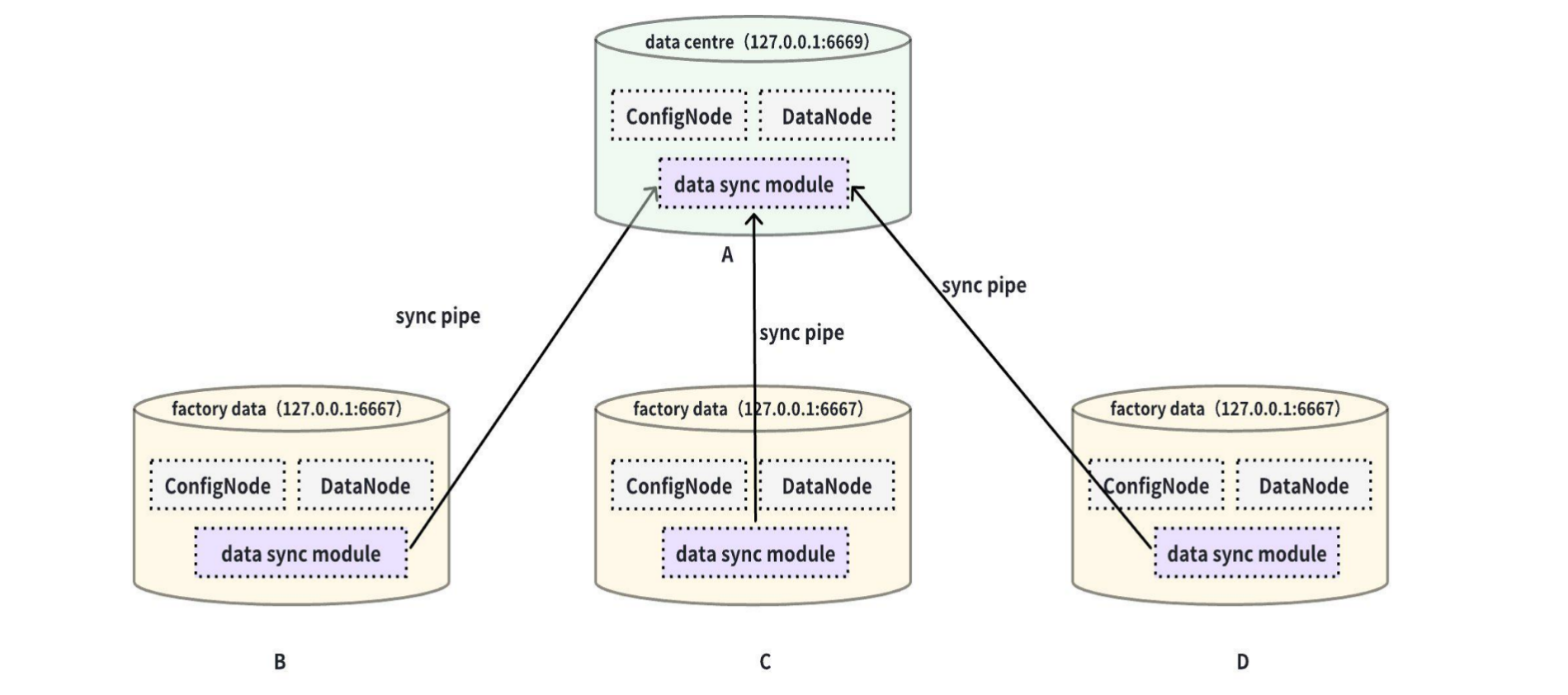
In this example, to synchronize the data from clusters B, C, and D to A, the pipe between BA, CA, and DA needs to configure the path to limit the range, and to keep the edge and cloud data consistent, the pipe needs to be configured with inclusion=all to synchronize full data and metadata. The detailed statement is as follows:
On B IoTDB, execute the following statement to synchronize data from B to A:
create pipe BA
with source (
'inclusion'='all', -- Indicates synchronization of full data, schema , and auth
'path'='root.db.**', -- Limit the range
)
with sink (
'sink'='iotdb-thrift-sink',
'node-urls' = '127.0.0.1:6668', -- The URL of the data service port of the DataNode node on the target IoTDB
)
)
On C IoTDB, execute the following statement to synchronize data from C to A:
create pipe CA
with source (
'inclusion'='all', -- Indicates synchronization of full data, schema , and auth
'path'='root.db.**', -- Limit the range
with sink (
'sink'='iotdb-thrift-sink',
'node-urls' = '127.0.0.1:6668', -- The URL of the data service port of the DataNode node on the target IoTDB
)
)
On D IoTDB, execute the following statement to synchronize data from D to A:
create pipe DA
with source (
'inclusion'='all', -- Indicates synchronization of full data, schema , and auth
'path'='root.db.**', -- Limit the range
)
with sink (
'sink'='iotdb-thrift-sink',
'node-urls' = '127.0.0.1:6668', -- The URL of the data service port of the DataNode node on the target IoTDB
)
)
Cascading data transfer
This example is used to demonstrate the scenario where data is transferred in a cascading manner between multiple IoTDB, with data from cluster A synchronized to cluster B, and then to cluster C, as shown in the figure below:
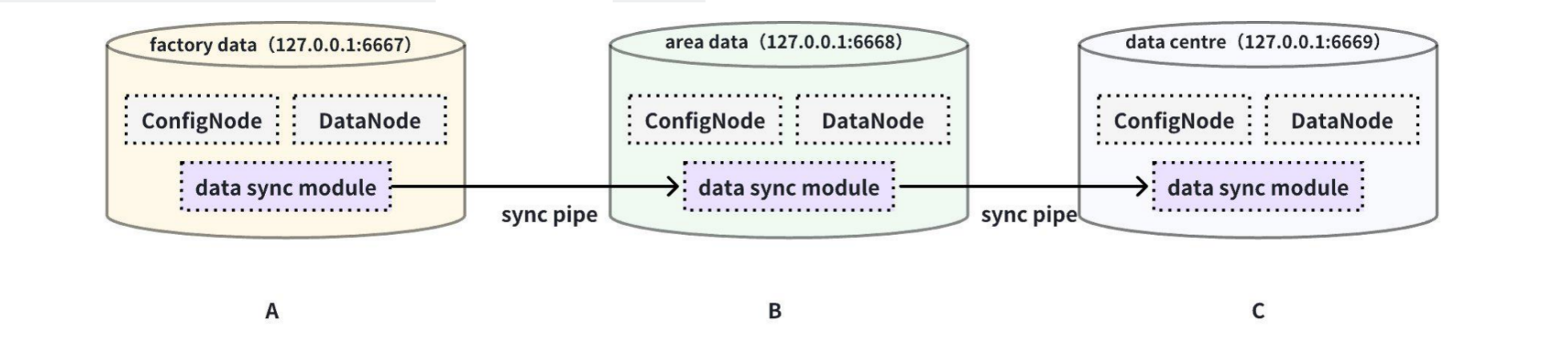
In this example, to synchronize the data from cluster A to C, the forwarding-pipe-requests needs to be set to true between BC. The detailed statement is as follows:
On A IoTDB, execute the following statement to synchronize data from A to B:
create pipe AB
with sink (
'sink'='iotdb-thrift-sink',
'node-urls' = '127.0.0.1:6668', -- The URL of the data service port of the DataNode node on the target IoTDB
)
)
On B IoTDB, execute the following statement to synchronize data from B to C:
create pipe BC
with source (
'forwarding-pipe-requests' = 'true' -- Whether to forward data written by other Pipes
)
with sink (
'sink'='iotdb-thrift-sink',
'node-urls' = '127.0.0.1:6669', -- The URL of the data service port of the DataNode node on the target IoTDB
)
)
Compression Synchronization (V1.3.3+)
IoTDB supports specifying data compression methods during the synchronization process. By configuring the compressor parameter, real-time data compression and transmission can be achieved. The compressor currently supports five optional algorithms: snappy, gzip, lz4, zstd, and lzma2, and multiple compression algorithms can be combined, compressed in the order of configuration.
For example, to create a synchronization task named A2B:
create pipe A2B
with sink (
'node-urls' = '127.0.0.1:6668', -- The URL of the data service port of the DataNode node on the target IoTDB
'compressor' = 'snappy,lz4' -- Compression algorithms
)
Encrypted Synchronization (V1.3.1+)
IoTDB supports the use of SSL encryption during the synchronization process, ensuring the secure transfer of data between different IoTDB instances. By configuring SSL-related parameters, such as the certificate address and password (ssl.trust-store-path)、(ssl.trust-store-pwd), data can be protected by SSL encryption during the synchronization process.
For example, to create a synchronization task named A2B:
create pipe A2B
with sink (
'sink'='iotdb-thrift-ssl-sink',
'node-urls'='127.0.0.1:6667', -- The URL of the data service port of the DataNode node on the target IoTDB
'ssl.trust-store-path'='pki/trusted', -- The trust store certificate path required to connect to the target DataNode
'ssl.trust-store-pwd'='root' -- The trust store certificate password required to connect to the target DataNode
)
Reference: Notes
You can adjust the parameters for data synchronization by modifying the IoTDB configuration file (iotdb-system.properties), such as the directory for storing synchronized data. The complete configuration is as follows:
V1.3.3+:
# pipe_receiver_file_dir
# If this property is unset, system will save the data in the default relative path directory under the IoTDB folder(i.e., %IOTDB_HOME%/${cn_system_dir}/pipe/receiver).
# If it is absolute, system will save the data in the exact location it points to.
# If it is relative, system will save the data in the relative path directory it indicates under the IoTDB folder.
# Note: If pipe_receiver_file_dir is assigned an empty string(i.e.,zero-size), it will be handled as a relative path.
# effectiveMode: restart
# For windows platform
# If its prefix is a drive specifier followed by "\\", or if its prefix is "\\\\", then the path is absolute. Otherwise, it is relative.
# pipe_receiver_file_dir=data\\confignode\\system\\pipe\\receiver
# For Linux platform
# If its prefix is "/", then the path is absolute. Otherwise, it is relative.
pipe_receiver_file_dir=data/confignode/system/pipe/receiver
####################
### Pipe Configuration
####################
# Uncomment the following field to configure the pipe lib directory.
# effectiveMode: first_start
# For Windows platform
# If its prefix is a drive specifier followed by "\\", or if its prefix is "\\\\", then the path is
# absolute. Otherwise, it is relative.
# pipe_lib_dir=ext\\pipe
# For Linux platform
# If its prefix is "/", then the path is absolute. Otherwise, it is relative.
pipe_lib_dir=ext/pipe
# The maximum number of threads that can be used to execute the pipe subtasks in PipeSubtaskExecutor.
# The actual value will be min(pipe_subtask_executor_max_thread_num, max(1, CPU core number / 2)).
# effectiveMode: restart
# Datatype: int
pipe_subtask_executor_max_thread_num=5
# The connection timeout (in milliseconds) for the thrift client.
# effectiveMode: restart
# Datatype: int
pipe_sink_timeout_ms=900000
# The maximum number of selectors that can be used in the sink.
# Recommend to set this value to less than or equal to pipe_sink_max_client_number.
# effectiveMode: restart
# Datatype: int
pipe_sink_selector_number=4
# The maximum number of clients that can be used in the sink.
# effectiveMode: restart
# Datatype: int
pipe_sink_max_client_number=16
# The total bytes that all pipe sinks can transfer per second.
# When given a value less than or equal to 0, it means no limit.
# default value is -1, which means no limit.
# effectiveMode: hot_reload
# Datatype: double
pipe_all_sinks_rate_limit_bytes_per_second=-1
Reference: parameter description
source parameter(V1.3.3)
| key | value | value range | required or not | default value |
|---|---|---|---|---|
| source | iotdb-source | String: iotdb-source | Required | - |
| inclusion | Used to specify the range of data to be synchronized in the data synchronization task, including data, schema, and auth | String:all, data(insert,delete), schema(database,timeseries,ttl), auth | Optional | data.insert |
| inclusion.exclusion | Used to exclude specific operations from the range specified by inclusion, reducing the amount of data synchronized | String:all, data(insert,delete), schema(database,timeseries,ttl), auth | Optional | - |
| path | Used to filter the path pattern schema of time series and data to be synchronized / schema synchronization can only use pathpath is exact matching, parameters must be prefix paths or complete paths, i.e., cannot contain "*", at most one "**" at the end of the path parameter | String:IoTDB pattern | Optional | root.** |
| pattern | Used to filter the path prefix of time series | String: Optional | Optional | root |
| start-time | The start event time for synchronizing all data, including start-time | Long: [Long.MIN_VALUE, Long.MAX_VALUE] | Optional | Long.MIN_VALUE |
| end-time | The end event time for synchronizing all data, including end-time | Long: [Long.MIN_VALUE, Long.MAX_VALUE] | Optional | Long.MAX_VALUE |
| realtime.mode | The extraction mode for newly inserted data (after pipe creation) | String: batch | Optional | batch |
| forwarding-pipe-requests | Whether to forward data written by other Pipes (usually data synchronization) | Boolean: true | Optional | true |
| loose-range | When transferring TsFile, whether to relax the range of historical data (before the creation of the pipe). "": Do not relax the range, select data strictly according to the set conditions. "time": Relax the time range to avoid splitting TsFile, which can improve synchronization efficiency. "path": Relax the path range to avoid splitting TsFile, which can improve synchronization efficiency. "time, path", "path, time", "all": Relax all ranges to avoid splitting TsFile, which can improve synchronization efficiency. | String: "" 、 "time" 、 "path" 、 "time, path" 、 "path, time" 、 "all" | Optional | |
| mods.enable | Whether to send the mods file of tsfile | Boolean: true / false | Optional | false |
💎 Explanation:To maintain compatibility with lower versions, history.enable, history.start-time, history.end-time, realtime.enable can still be used, but they are not recommended in the new version.
💎 Explanation: Differences between Stream and Batch Data Extraction Modes
- stream (recommended): In this mode, tasks process and send data in real-time. It is characterized by high timeliness and low throughput.
- batch: In this mode, tasks process and send data in batches (according to the underlying data files). It is characterized by low timeliness and high throughput.
sink parameter
In versions 1.3.3 and above, when only the sink is included, the additional "with sink" prefix is no longer required.
iotdb-thrift-sink
| key | value | value Range | required or not | Default Value |
|---|---|---|---|---|
| sink | iotdb-thrift-sink or iotdb-thrift-async-sink | String: iotdb-thrift-sink or iotdb-thrift-async-sink | Required | |
| node-urls | The URL of the data service port of any DataNode nodes on the target IoTDB (please note that synchronization tasks do not support forwarding to its own service) | String. Example: '127.0.0.1:6667,127.0.0.1:6668,127.0.0.1:6669', '127.0.0.1:6667' | Required | - |
| batch.enable | Whether to enable batched log transmission mode to improve transmission throughput and reduce IOPS | Boolean: true, false | Optional | true |
| batch.max-delay-seconds | Effective when batched log transmission mode is enabled, it represents the maximum waiting time for a batch of data before sending (unit: s) | Integer | Optional | 1 |
| batch.size-bytes | Effective when batched log transmission mode is enabled, it represents the maximum batch size for a batch of data (unit: byte) | Long | Optional | 1610241024 |
iotdb-thrift-ssl-sink
| key | value | value Range | required or not | Default Value |
|---|---|---|---|---|
| sink | iotdb-thrift-ssl-sink | String: iotdb-thrift-ssl-sink | Required | - |
| node-urls | The URL of the data service port of any DataNode nodes on the target IoTDB (please note that synchronization tasks do not support forwarding to its own service) | String. Example: '127.0.0.1:6667,127.0.0.1:6668,127.0.0.1:6669', '127.0.0.1:6667' | Required | - |
| batch.enable | Whether to enable batched log transmission mode to improve transmission throughput and reduce IOPS | Boolean: true, false | Optional | true |
| batch.max-delay-seconds | Effective when batched log transmission mode is enabled, it represents the maximum waiting time for a batch of data before sending (unit: s) | Integer | Optional | 1 |
| batch.size-bytes | Effective when batched log transmission mode is enabled, it represents the maximum batch size for a batch of data (unit: byte) | Long | Optional | 1610241024 |
| ssl.trust-store-path | The trust store certificate path required to connect to the target DataNode | String: certificate directory name, when configured as a relative directory, it is relative to the IoTDB root directory. Example: '127.0.0.1:6667,127.0.0.1:6668,127.0.0.1:6669', '127.0.0.1:6667' | Required | - |
| ssl.trust-store-pwd | The trust store certificate password required to connect to the target DataNode | Integer | Required | - |