
负载均衡
负载均衡
本文档介绍 IoTDB 中的分区策略和负载均衡策略。根据时序数据的特性,IoTDB 按序列和时间维度对其进行分区。结合序列分区与时间分区创建一个分区,作为划分的基本单元。为了提高吞吐量并降低管理成本,这些分区被均匀分配到分片(Region)中,分片是复制的基本单元。分片的副本决定了数据的存储位置,主副本负责主要负载的管理。在此过程中,副本放置算法决定哪些节点将持有分片副本,而主副本选择算法则指定哪个副本将成为主副本。
分区策略和分区分配
IoTDB 为时间序列数据实现了量身定制的分区算法。在此基础上,缓存于配置节点和数据节点上的分区信息不仅易于管理,而且能够清晰区分冷热数据。随后,平衡的分区被均匀分配到集群的分片中,以实现存储均衡。
分区策略
IoTDB 将生产环境中的每个传感器映射为一个时间序列。然后,使用序列分区算法对时间序列进行分区以管理其元数据,再结合时间分区算法来管理其数据。下图展示了 IoTDB 如何对时序数据进行分区。
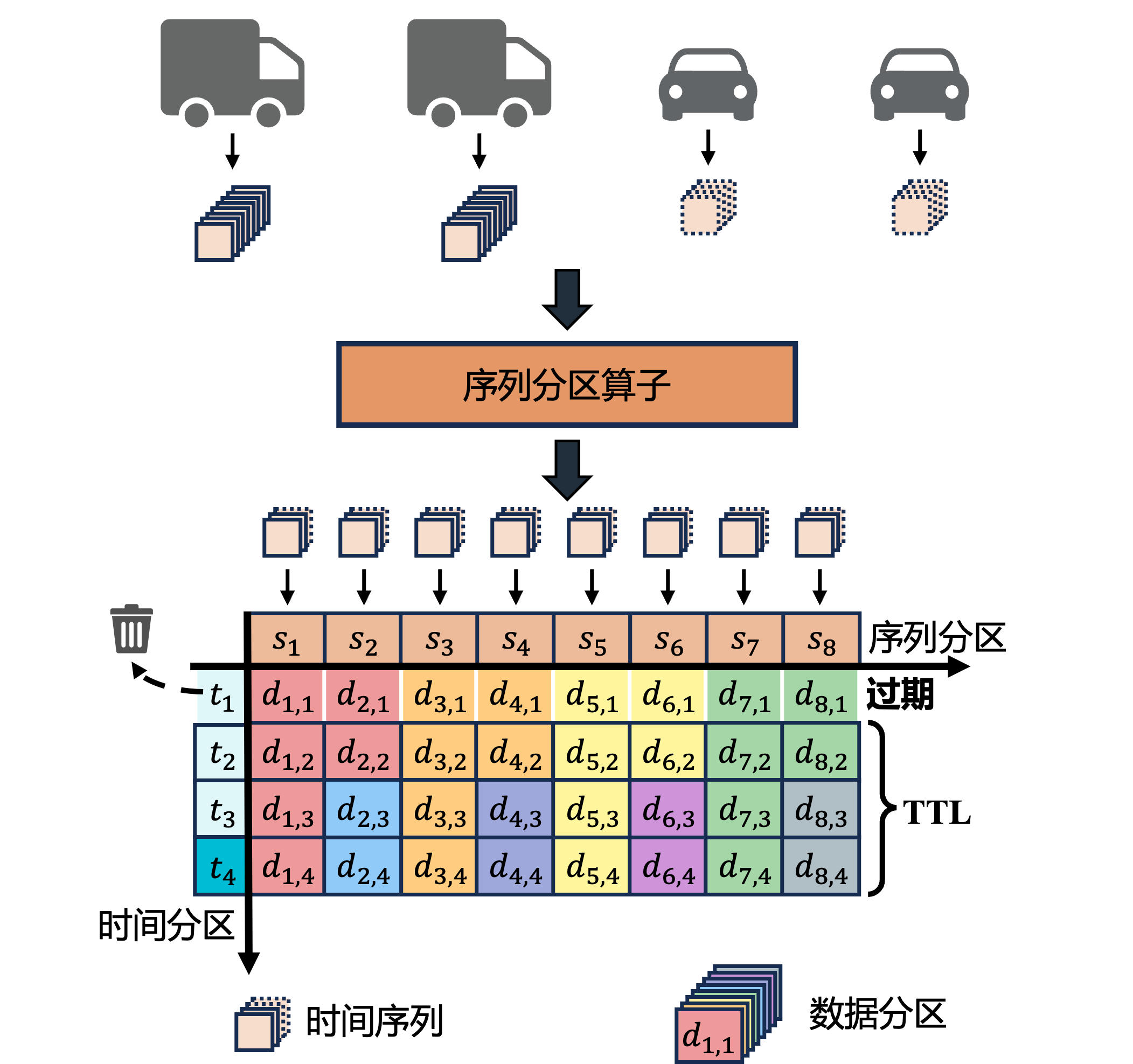
分区算法
由于生产环境中通常部署大量设备和传感器,IoTDB 使用序列分区算法以确保分区信息的大小可控。由于生成的时间序列与时间戳相关联,IoTDB 使用时间分区算法来清晰区分冷热分区。
序列分区算法
默认情况下,IoTDB 将序列分区的数量限制为 1000,并将序列分区算法配置为哈希分区算法。这带来以下收益:
- 由于序列分区的数量是固定常量,序列与序列分区之间的映射保持稳定。因此,IoTDB 不需要频繁进行数据迁移。
- 序列分区的负载相对均衡,因为序列分区的数量远小于生产环境中部署的传感器数量。
更进一步,如果能够更准确地估计生产环境中的实际负载情况,序列分区算法可以配置为自定义的哈希分区或列表分区,以在所有序列分区中实现更均匀的负载分布。
时间分区算法
时间分区算法通过下式将给定的时间戳转换为相应的时间分区
在此式中, 和 都是可配置参数,以适应不同的生产环境。 表示第一个时间分区的起始时间,而 定义了每个时间分区的持续时间。默认情况下, 设置为一天。
元数据分区
由于序列分区算法对时间序列进行了均匀分区,每个序列分区对应一个元数据分区。这些元数据分区随后被均匀分配到 元数据分片 中,以实现元数据的均衡分布。
数据分区
结合序列分区与时间分区创建数据分区。由于序列分区算法对时间序列进行了均匀分区,特定时间分区内的数据分区负载保持均衡。这些数据分区随后被均匀分配到数据分片中,以实现数据的均衡分布。
分区分配
IoTDB 使用分片来实现时间序列的弹性存储,集群中分片的数量由所有数据节点的总资源决定。由于分片的数量是动态的,IoTDB 可以轻松扩展。元数据分片和数据分片都遵循相同的分区分配算法,即均匀划分所有序列分区。下图展示了分区分配过程,其中动态扩展的分片匹配不断扩展的时间序列和集群。
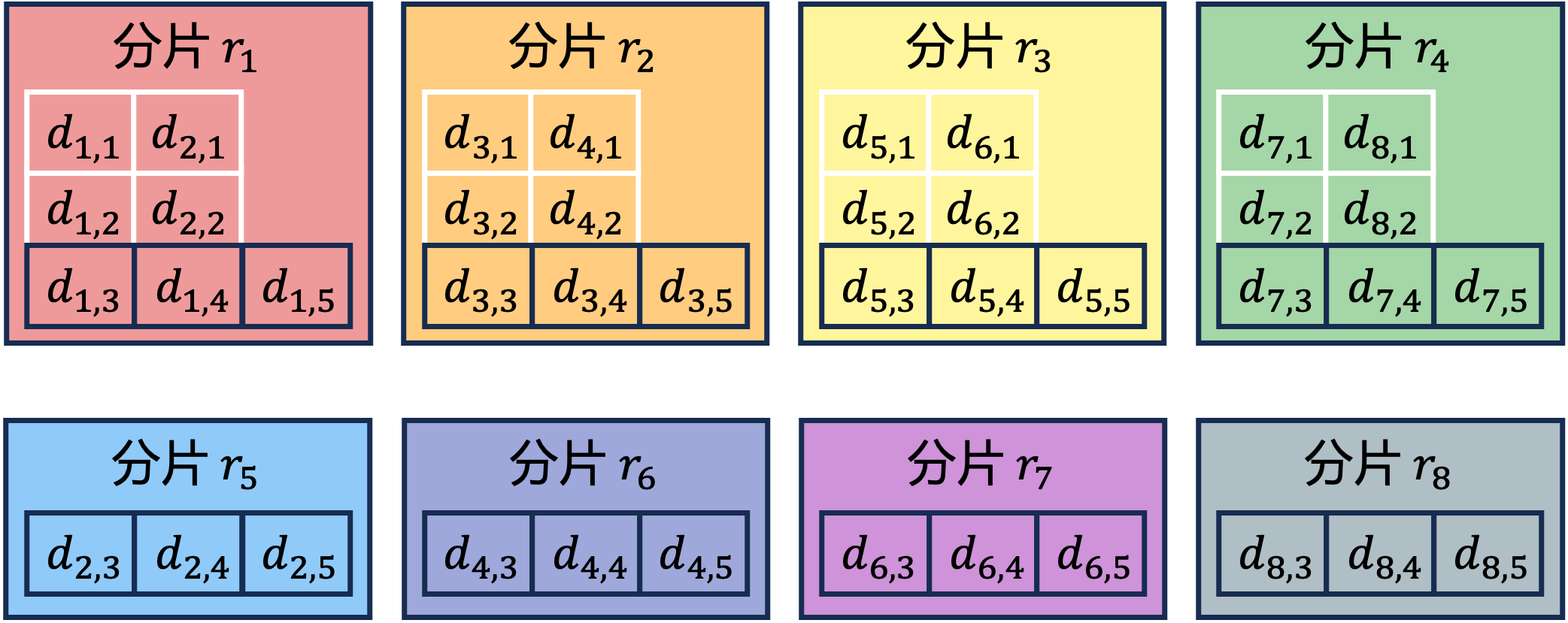
分片扩容
分片的数量由下式给出
在此式中, 表示期望在第 个数据节点上放置的副本数量,而 表示每个分片中的副本数量。 和 都是可配置的参数。 可以根据第 个数据节点上的可用硬件资源(如 CPU 核心数量、内存大小等)确定,以适应不同的物理服务器。 可以调整以确保不同级别的容错能力。
分配策略
元数据分片和数据分片都遵循相同的分配策略,即均匀划分所有序列分区。因此,每个元数据分片持有相同数量的元数据分区,以确保元数据存储均衡。同样,对于每个时间分区,每个数据分片 获取与其持有的序列分区对应的数据分区。因此,时间分区内的数据分区均匀分布在所有数据分片中,确保每个时间分区内的数据存储均衡。
值得注意的是,IoTDB 有效利用了时序数据的特性。当配置了 TTL(生存时间)时,IoTDB 可实现无需迁移的时序数据弹性存储,该功能在集群扩展时最小化了对在线操作的影响。上图展示了该功能的一个实例:新生成的数据分区被均匀分配到每个数据分片,过期数据会自动归档。因此,集群的存储最终将保持平衡。
均衡策略
为了提高集群的可用性和性能,IoTDB 采用了精心设计的存储均衡和计算均衡算法。
存储均衡
数据节点持有的副本数量反映了它的存储负载。如果数据节点之间的副本数量差异较大,拥有更多副本的数据节点可能成为存储瓶颈。尽管简单的轮询(Round Robin)放置算法可以通过确保每个数据节点持有等量副本来实现存储均衡,但它会降低集群的容错能力,如下所示:

- 假设集群有 4 个数据节点,4 个分片,并且副本因子为 2。
- 将分片 的 2 个副本放置在数据节点 和 上。
- 将分片 的 2 个副本放置在数据节点 和 上。
- 将分片 的 2 个副本放置在数据节点 和 上。
- 将分片 的 2 个副本放置在数据节点 和 上。
在这种情况下,如果数据节点 发生故障,由它先前负责的负载将只能全部转移到数据节点 ,可能导致其过载。
为了解决这个问题,IoTDB 采用了一种副本放置算法,该算法不仅将副本均匀放置到所有数据节点上,还确保每个 数据节点在发生故障时,能够将其负载转移到足够多的其他数据节点。因此,集群实现了存储分布的均衡,并具备较高的容错能力,从而确保其可用性。
计算均衡
数据节点持有的主副本数量反映了它的计算负载。如果数据节点之间持有主副本数量差异较大,拥有更多主副本的数据节点可能成为计算瓶颈。如果主副本选择过程使用直观的贪心算法,当副本以容错算法放置时,可能会导致主副本分布不均,如下所示:

- 假设集群有 4 个数据节点,4 个分片,并且副本因子为 2。
- 选择分片 在数据节点 上的副本作为主副本。
- 选择分片 在数据节点 上的副本作为主副本。
- 选择分片 在数据节点 上的副本作为主副本。
- 选择分片 在数据节点 上的副本作为主副本。
请注意,以上步骤严格遵循贪心算法。然而,到第 3 步时,无论在数据节点 或 上选择分片 的主副本,都会导致主副本分布不均衡。根本原因在于每一步贪心选择都缺乏全局视角,最终导致局部最优解。
为了解决这个问题,IoTDB 采用了一种主副本选择算法,能够持续平衡集群中的主副本分布。因此,集群实现了计算负载的均衡分布,确保了其性能。