Prometheus
大约 5 分钟
Prometheus
监控指标的 Prometheus 映射关系
对于 Metric Name 为 name, Tags 为 K1=V1, ..., Kn=Vn 的监控指标有如下映射,其中 value 为具体值
| 监控指标类型 | 映射关系 |
|---|---|
| Counter | name_total{cluster="clusterName", nodeType="nodeType", nodeId="nodeId",k1="V1" , ..., Kn="Vn"} value |
| AutoGauge、Gauge | name{cluster="clusterName", nodeType="nodeType", nodeId="nodeId",k1="V1" , ..., Kn="Vn"} value |
| Histogram | name_max{cluster="clusterName", nodeType="nodeType", nodeId="nodeId",k1="V1" , ..., Kn="Vn"} value name_sum{cluster="clusterName", nodeType="nodeType", nodeId="nodeId",k1="V1" , ..., Kn="Vn"} value name_count{cluster="clusterName", nodeType="nodeType", nodeId="nodeId",k1="V1" , ..., Kn="Vn"} value name{cluster="clusterName", nodeType="nodeType", nodeId="nodeId",k1="V1" , ..., Kn="Vn", quantile="0.5"} value name{cluster="clusterName", nodeType="nodeType", nodeId="nodeId",k1="V1" , ..., Kn="Vn", quantile="0.99"} value |
| Rate | name_total{cluster="clusterName", nodeType="nodeType", nodeId="nodeId",k1="V1" , ..., Kn="Vn"} value name_total{cluster="clusterName", nodeType="nodeType", nodeId="nodeId",k1="V1" , ..., Kn="Vn", rate="m1"} value name_total{cluster="clusterName", nodeType="nodeType", nodeId="nodeId",k1="V1" , ..., Kn="Vn", rate="m5"} value name_total{cluster="clusterName", nodeType="nodeType", nodeId="nodeId",k1="V1" , ..., Kn="Vn", rate="m15"} value name_total{cluster="clusterName", nodeType="nodeType", nodeId="nodeId",k1="V1" , ..., Kn="Vn", rate="mean"} value |
| Timer | name_seconds_max{cluster="clusterName", nodeType="nodeType", nodeId="nodeId",k1="V1" , ..., Kn="Vn"} value name_seconds_sum{cluster="clusterName", nodeType="nodeType", nodeId="nodeId",k1="V1" , ..., Kn="Vn"} value name_seconds_count{cluster="clusterName", nodeType="nodeType", nodeId="nodeId",k1="V1" , ..., Kn="Vn"} value name_seconds{cluster="clusterName", nodeType="nodeType", nodeId="nodeId",k1="V1" , ..., Kn="Vn", quantile="0.5"} value value name_seconds{cluster="clusterName", nodeType="nodeType", nodeId="nodeId",k1="V1" , ..., Kn="Vn", quantile="0.99"} value |
修改配置文件
- 以 DataNode 为例,修改 iotdb-system.properties 配置文件如下:
dn_metric_reporter_list=PROMETHEUS
dn_metric_level=CORE
dn_metric_prometheus_reporter_port=9091
启动 IoTDB DataNode
打开浏览器或者用
curl访问http://servier_ip:9091/metrics, 就能得到如下 metric 数据:
...
# HELP file_count
# TYPE file_count gauge
file_count{name="wal",} 0.0
file_count{name="unseq",} 0.0
file_count{name="seq",} 2.0
...
Prometheus + Grafana
如上所示,IoTDB 对外暴露出标准的 Prometheus 格式的监控指标数据,可以使用 Prometheus 采集并存储监控指标,使用 Grafana
可视化监控指标。
IoTDB、Prometheus、Grafana三者的关系如下图所示:
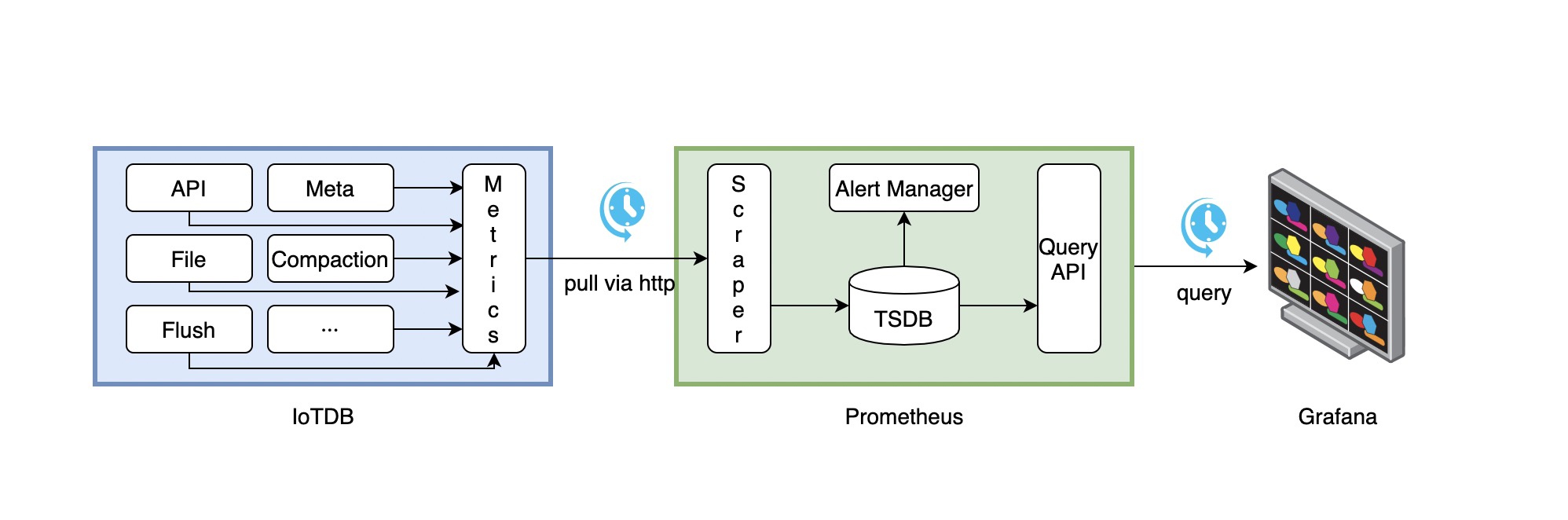
- IoTDB在运行过程中持续收集监控指标数据。
- Prometheus以固定的间隔(可配置)从IoTDB的HTTP接口拉取监控指标数据。
- Prometheus将拉取到的监控指标数据存储到自己的TSDB中。
- Grafana以固定的间隔(可配置)从Prometheus查询监控指标数据并绘图展示。
从交互流程可以看出,我们需要做一些额外的工作来部署和配置Prometheus和Grafana。
比如,你可以对Prometheus进行如下的配置(部分参数可以自行调整)来从IoTDB获取监控数据
job_name: pull-metrics
honor_labels: true
honor_timestamps: true
scrape_interval: 15s
scrape_timeout: 10s
metrics_path: /metrics
scheme: http
follow_redirects: true
static_configs:
- targets:
- localhost:9091
更多细节可以参考下面的文档:
Prometheus从HTTP接口拉取metrics数据的配置说明
Apache IoTDB Dashboard
Apache IoTDB Dashboard是 IoTDB 企业版的配套产品,支持统一集中式运维管理,可通过一个监控面板监控多个集群。你可以联系商务获取到 Dashboard 的 Json文件。
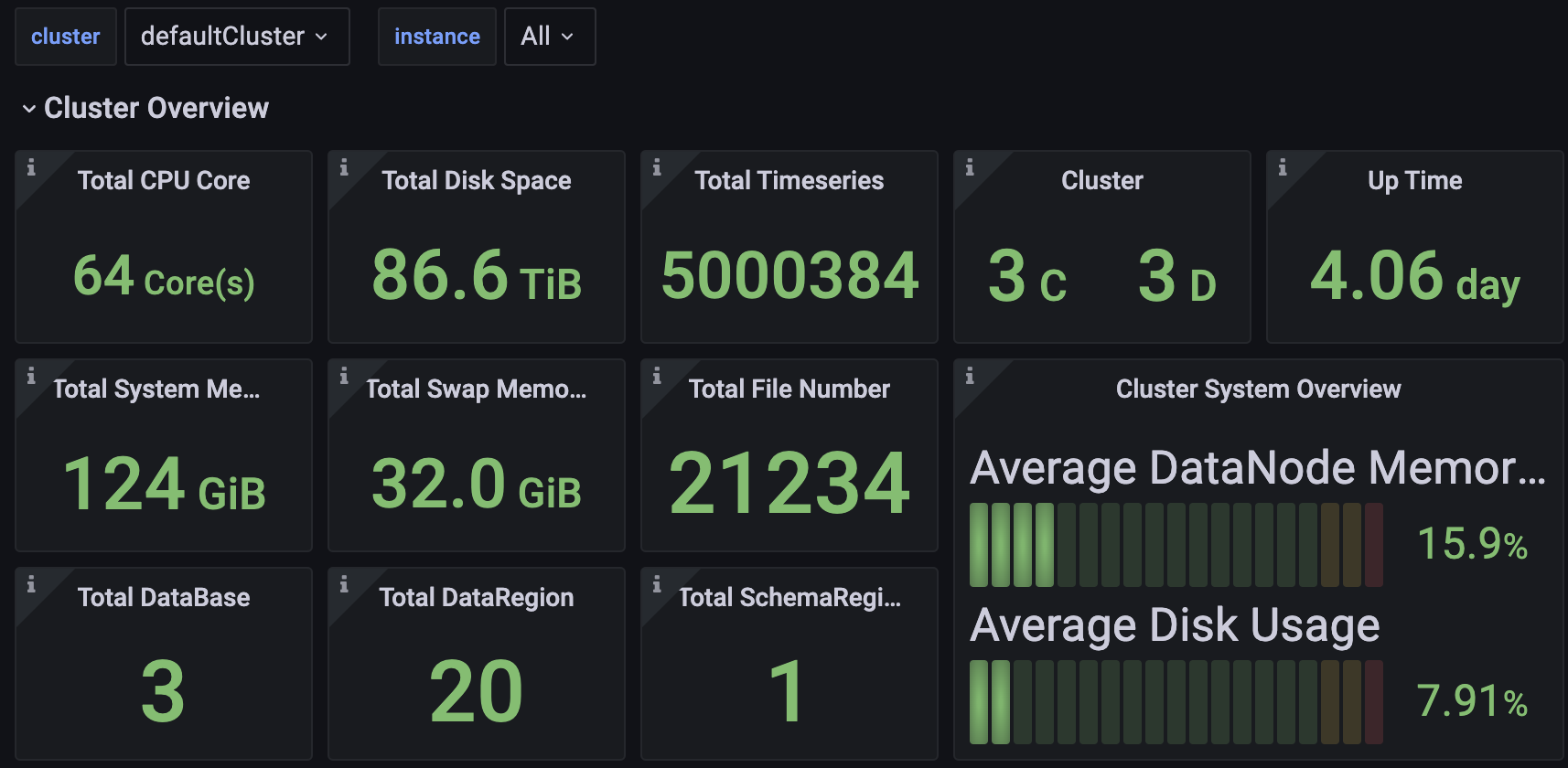
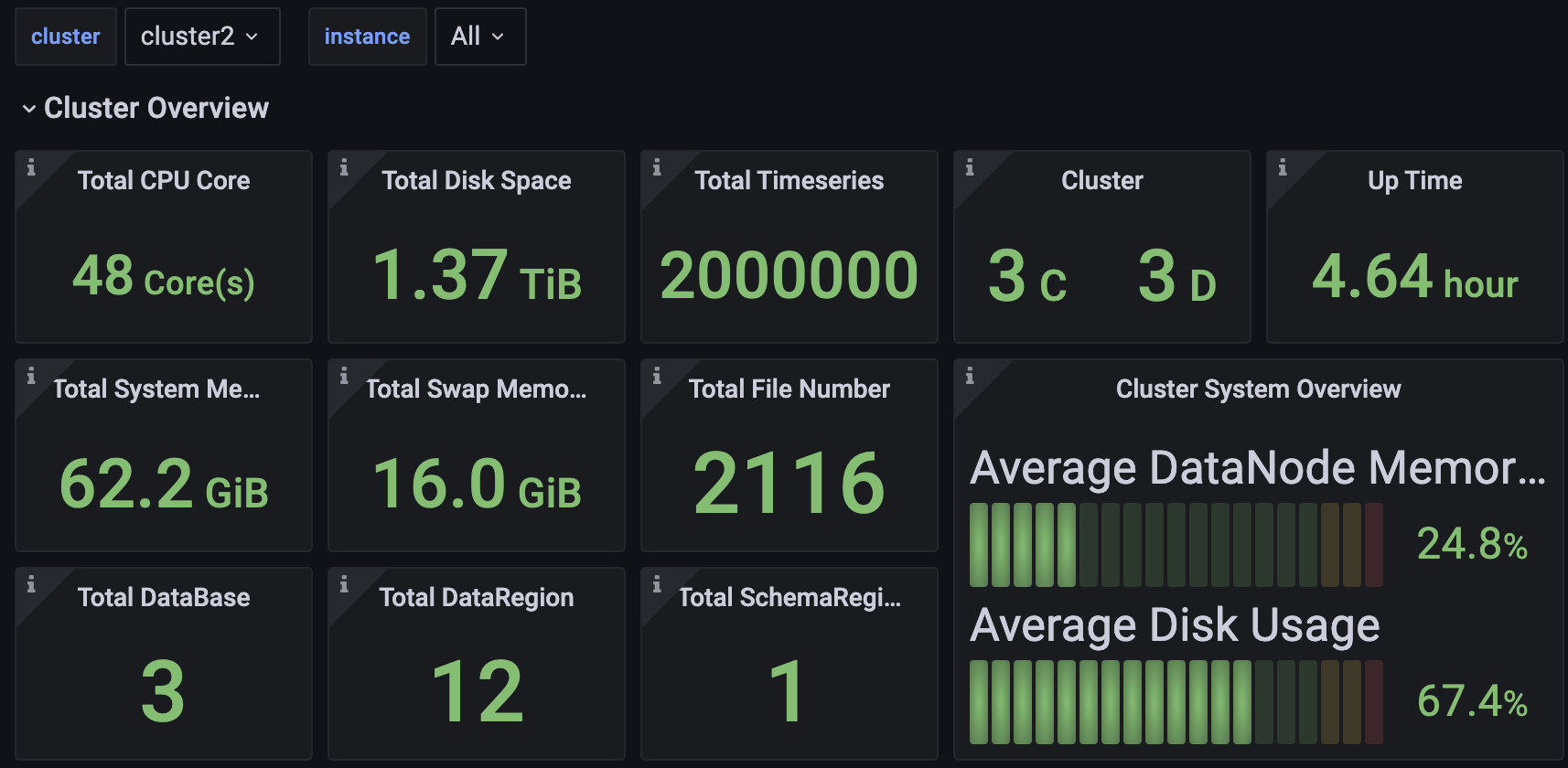
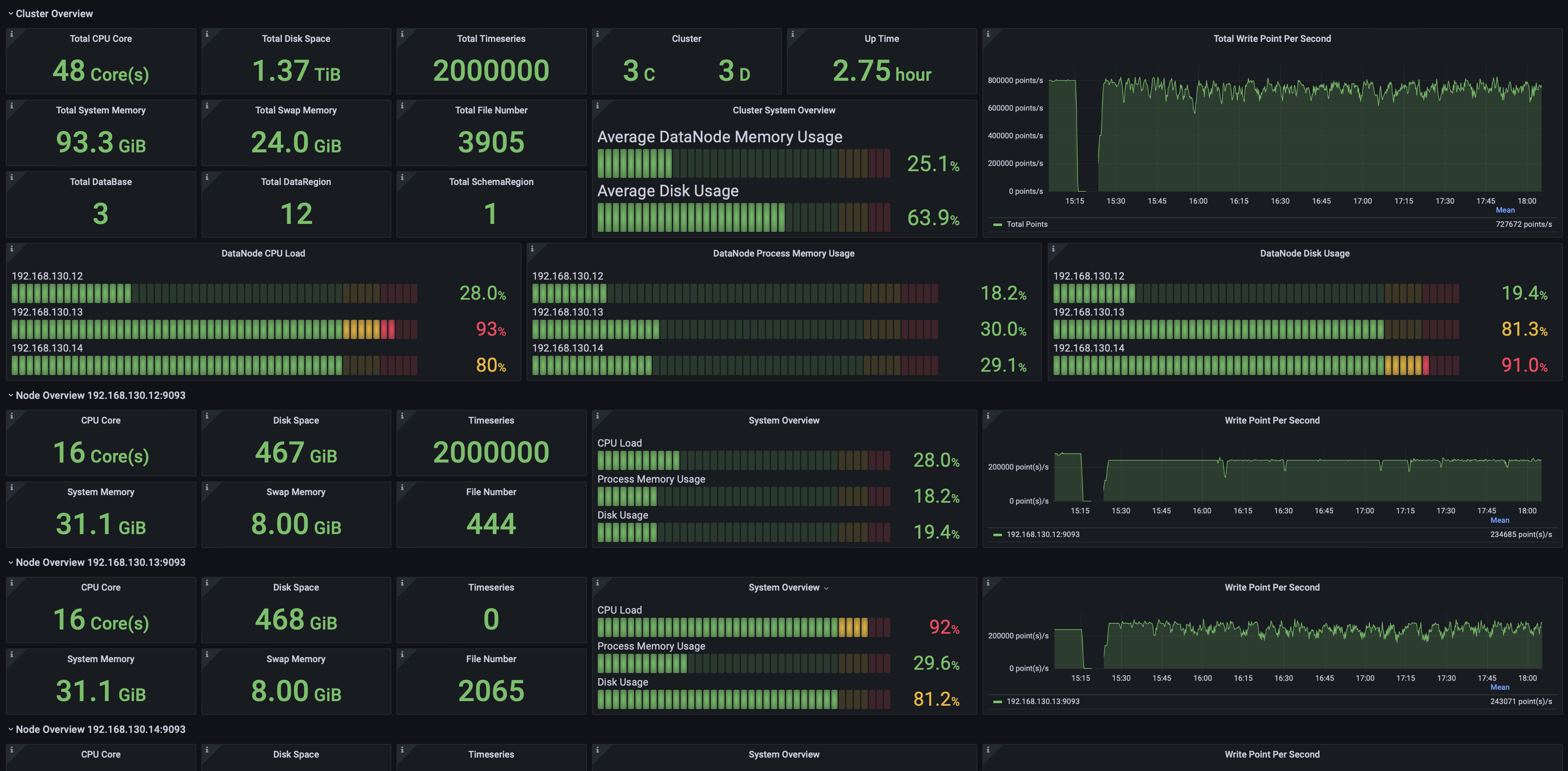
集群概览
可以监控包括但不限于:
- 集群总CPU核数、总内存空间、总硬盘空间
- 集群包含多少个ConfigNode与DataNode
- 集群启动时长
- 集群写入速度
- 集群各节点当前CPU、内存、磁盘使用率
- 分节点的信息
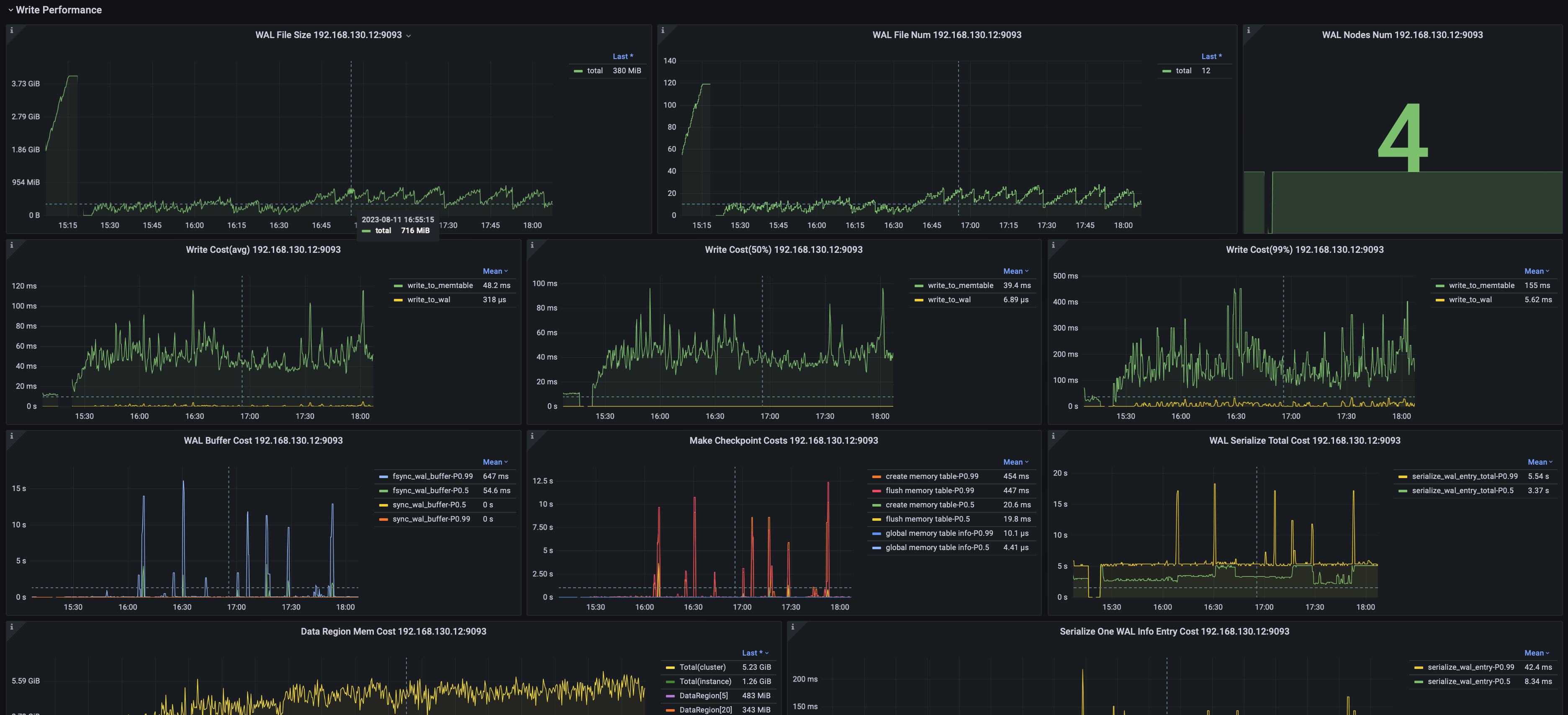
数据写入
可以监控包括但不限于:
- 写入平均耗时、耗时中位数、99%分位耗时
- WAL文件数量与尺寸
- 节点 WAL flush SyncBuffer 耗时
数据查询
可以监控包括但不限于:
- 节点查询加载时间序列元数据耗时
- 节点查询读取时间序列耗时
- 节点查询修改时间序列元数据耗时
- 节点查询加载Chunk元数据列表耗时
- 节点查询修改Chunk元数据耗时
- 节点查询按照Chunk元数据过滤耗时
- 节点查询构造Chunk Reader耗时的平均值

存储引擎
可以监控包括但不限于:
- 分类型的文件数量、大小
- 处于各阶段的TsFile数量、大小
- 各类任务的数量与耗时

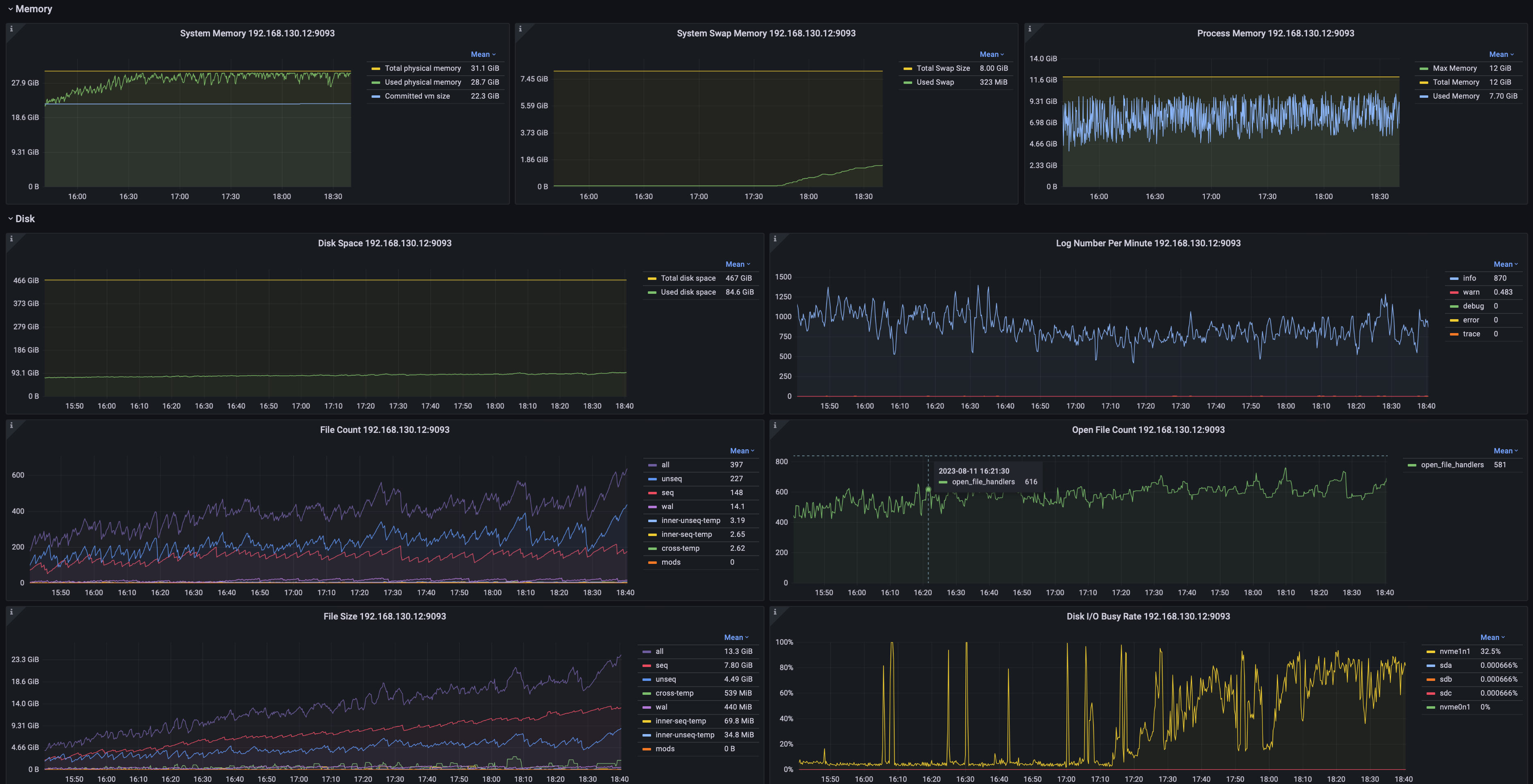
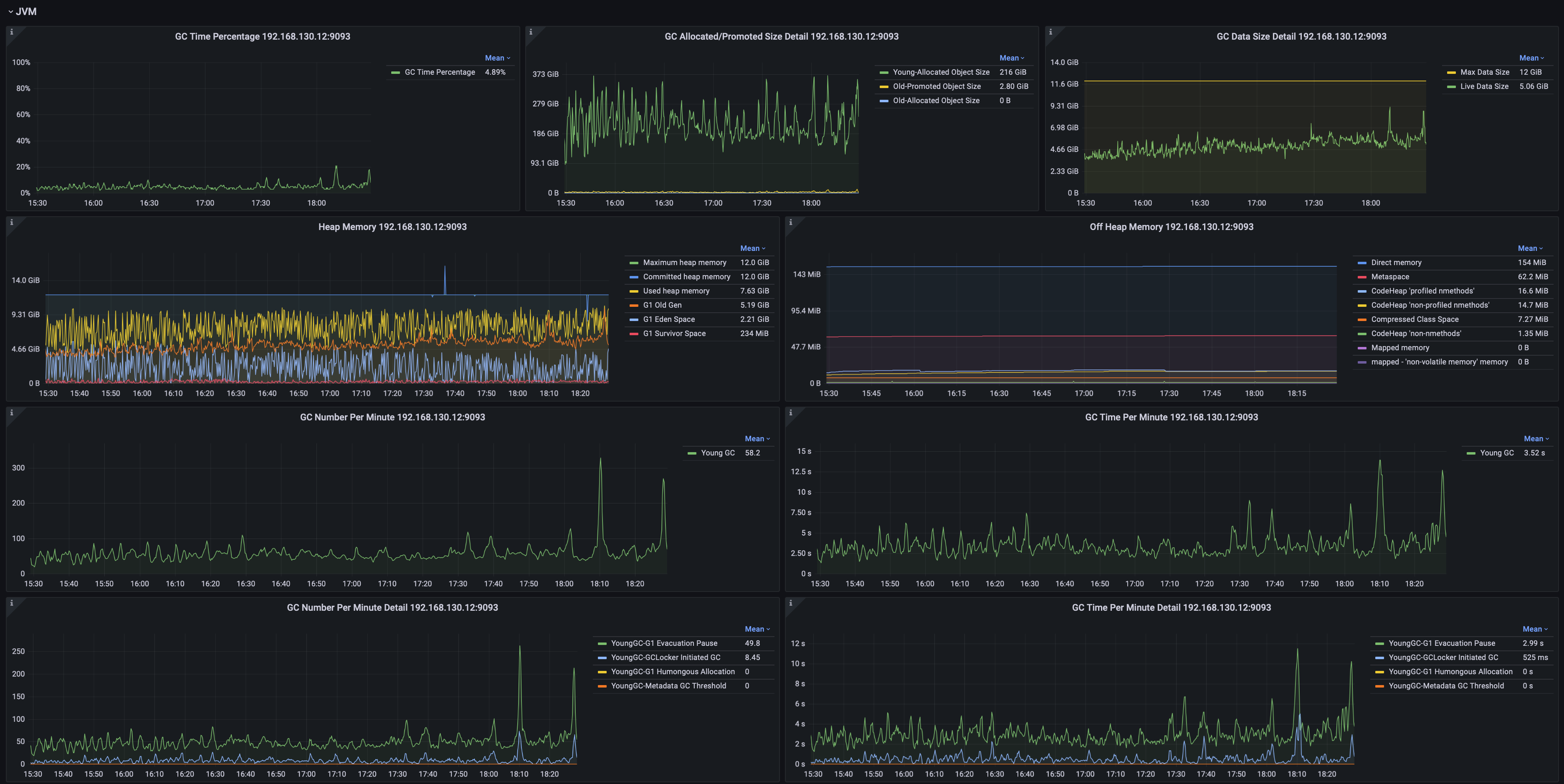
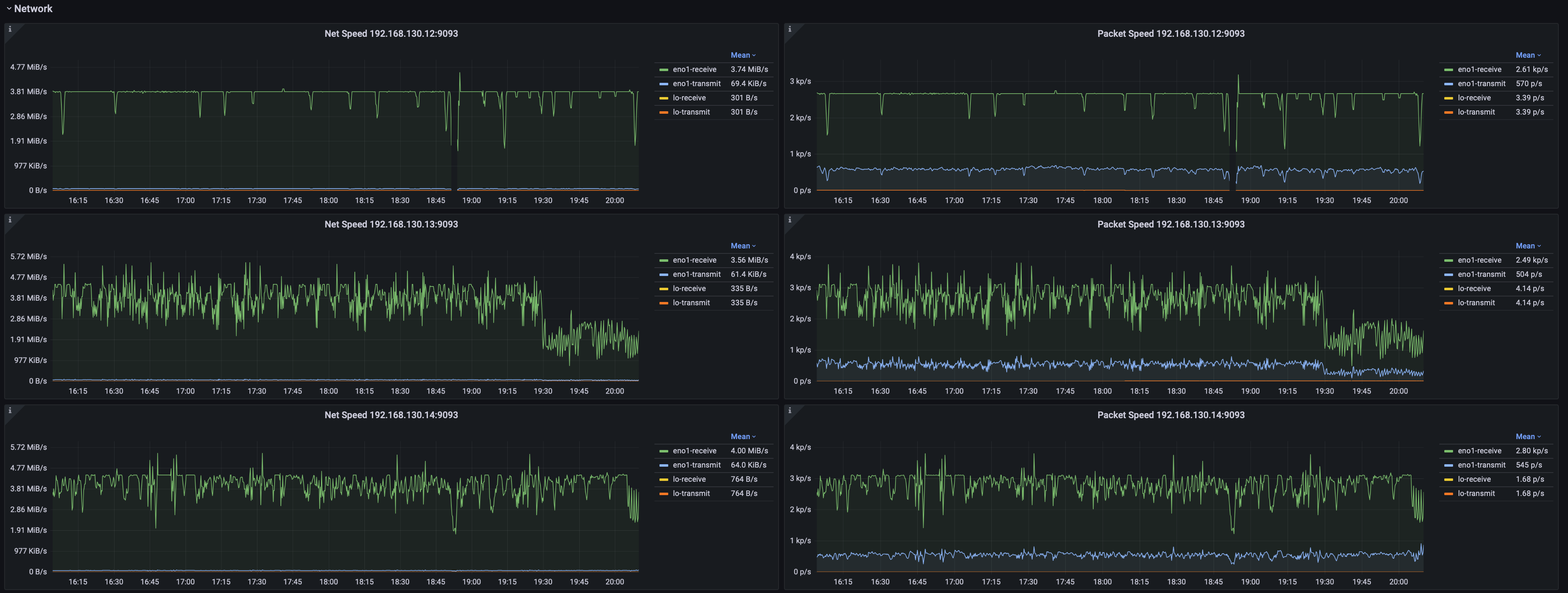
系统监控
可以监控包括但不限于:
- 系统内存、交换内存、进程内存
- 磁盘空间、文件数、文件尺寸
- JVM GC时间占比、分类型的GC次数、GC数据量、各年代的堆内存占用
- 网络传输速率、包发送速率