
连续查询
连续查询
1. 简介
连续查询(Continuous queries, aka CQ) 是对实时数据周期性地自动执行的查询,并将查询结果写入指定的时间序列中。
用户可以通过连续查询实现滑动窗口流式计算,如计算某个序列每小时平均温度,并写入一个新序列中。用户可以自定义 RESAMPLE 子句去创建不同的滑动窗口,可以实现对于乱序数据一定程度的容忍。
2. 语法
CREATE (CONTINUOUS QUERY | CQ) <cq_id>
[RESAMPLE
[EVERY <every_interval>]
[BOUNDARY <execution_boundary_time>]
[RANGE <start_time_offset>[, end_time_offset]]
]
[TIMEOUT POLICY BLOCKED|DISCARD]
BEGIN
SELECT CLAUSE
INTO CLAUSE
FROM CLAUSE
[WHERE CLAUSE]
[GROUP BY(<group_by_interval>[, <sliding_step>]) [, level = <level>]]
[HAVING CLAUSE]
[FILL {PREVIOUS | LINEAR | constant}]
[LIMIT rowLimit OFFSET rowOffset]
[ALIGN BY DEVICE]
END注意:
- 如果where子句中出现任何时间过滤条件,IoTDB将会抛出异常,因为IoTDB会自动为每次查询执行指定时间范围。
- GROUP BY TIME CLAUSE在连续查询中的语法稍有不同,它不能包含原来的第一个参数,即 [start_time, end_time),IoTDB会自动填充这个缺失的参数。如果指定,IoTDB将会抛出异常。
- 如果连续查询中既没有GROUP BY TIME子句,也没有指定EVERY子句,IoTDB将会抛出异常。
2.1 连续查询语法中参数含义的描述
<cq_id>为连续查询指定一个全局唯一的标识。<every_interval>指定了连续查询周期性执行的间隔。现在支持的时间单位有:ns, us, ms, s, m, h, d, w, 并且它的值不能小于用户在iotdb-system.properties配置文件中指定的continuous_query_min_every_interval。这是一个可选参数,默认等于group by子句中的group_by_interval。<start_time_offset>指定了每次查询执行窗口的开始时间,即now()-<start_time_offset>。现在支持的时间单位有:ns, us, ms, s, m, h, d, w。这是一个可选参数,默认等于EVERY子句中的every_interval。<end_time_offset>指定了每次查询执行窗口的结束时间,即now()-<end_time_offset>。现在支持的时间单位有:ns, us, ms, s, m, h, d, w。这是一个可选参数,默认等于0.<execution_boundary_time>表示用户期待的连续查询的首个周期任务的执行时间。(因为连续查询只会对当前实时的数据流做计算,所以该连续查询实际首个周期任务的执行时间并不一定等于用户指定的时间,具体计算逻辑如下所示)<execution_boundary_time>可以早于、等于或者迟于当前时间。- 这个参数是可选的,默认等于
0。 - 首次查询执行窗口的开始时间为
<execution_boundary_time> - <start_time_offset>. - 首次查询执行窗口的结束时间为
<execution_boundary_time> - <end_time_offset>. - 第i个查询执行窗口的时间范围是
[<execution_boundary_time> - <start_time_offset> + (i - 1) * <every_interval>, <execution_boundary_time> - <end_time_offset> + (i - 1) * <every_interval>)。 - 如果当前时间早于或等于, 那连续查询的首个周期任务的执行时间就是用户指定的
execution_boundary_time. - 如果当前时间迟于用户指定的
execution_boundary_time,那么连续查询的首个周期任务的执行时间就是execution_boundary_time + i * <every_interval>中第一个大于或等于当前时间的值。
- <every_interval>,<start_time_offset> 和 <group_by_interval> 都应该大于 0
- <group_by_interval>应该小于等于<start_time_offset>
- 用户应该根据实际需求,为<start_time_offset> 和 <every_interval> 指定合适的值
- 如果<start_time_offset>大于<every_interval>,在每一次查询执行的时间窗口上会有部分重叠
- 如果<start_time_offset>小于<every_interval>,在连续的两次查询执行的时间窗口中间将会有未覆盖的时间范围
- start_time_offset 应该大于end_time_offset
<start_time_offset>等于<every_interval>
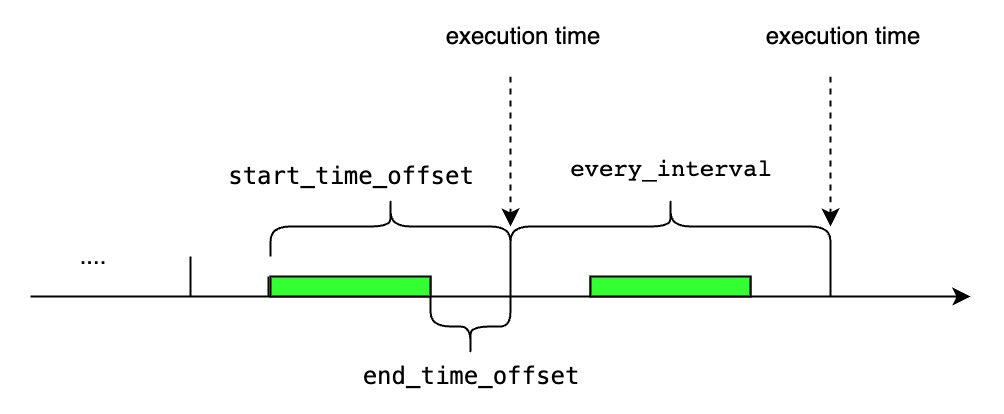
<start_time_offset>大于<every_interval>
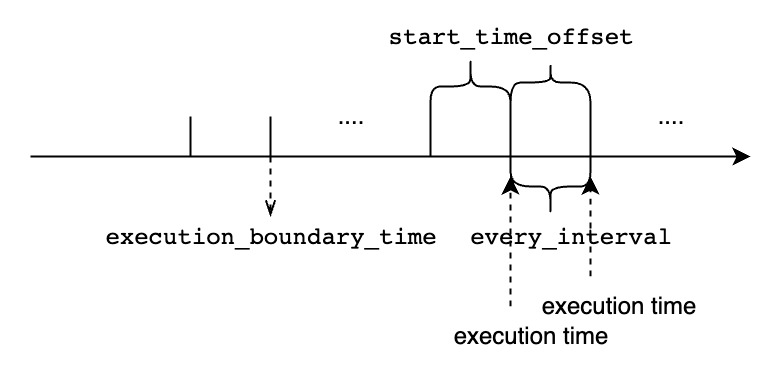
<start_time_offset>小于<every_interval>
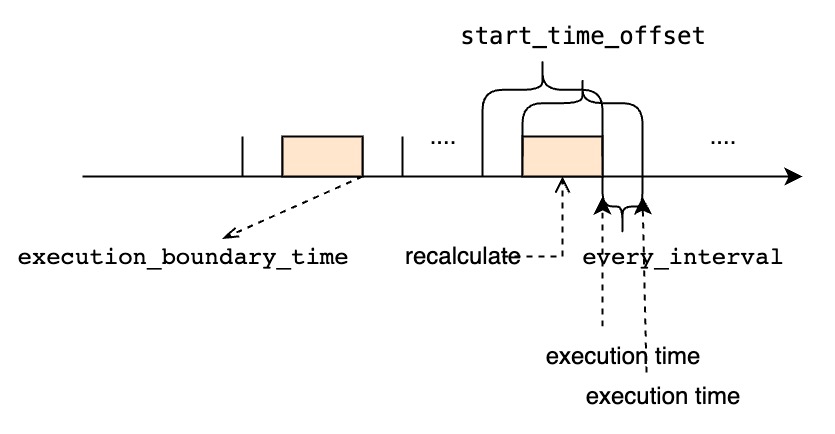
<every_interval>不为0
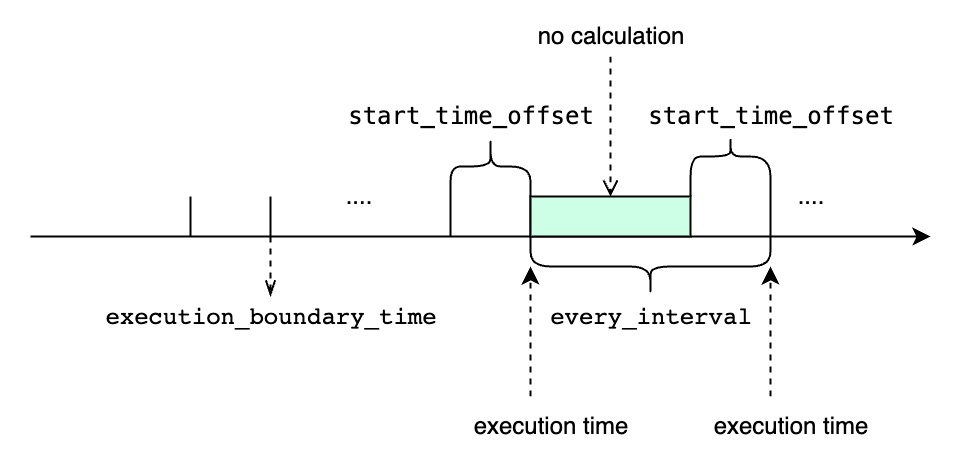
TIMEOUT POLICY指定了我们如何处理“前一个时间窗口还未执行完时,下一个窗口的执行时间已经到达的场景,默认值是BLOCKED.BLOCKED意味着即使下一个窗口的执行时间已经到达,我们依旧需要阻塞等待前一个时间窗口的查询执行完再开始执行下一个窗口。如果使用BLOCKED策略,所有的时间窗口都将会被依此执行,但是如果遇到执行查询的时间长于周期性间隔时,连续查询的结果会迟于最新的时间窗口范围。DISCARD意味着如果前一个时间窗口还未执行完,我们会直接丢弃下一个窗口的执行时间。如果使用DISCARD策略,可能会有部分时间窗口得不到执行。但是一旦前一个查询执行完后,它将会使用最新的时间窗口,所以它的执行结果总能赶上最新的时间窗口范围,当然是以部分时间窗口得不到执行为代价。
3. 连续查询的用例
下面是用例数据,这是一个实时的数据流,我们假设数据都按时到达。
+-----------------------------+-----------------------------+-----------------------------+-----------------------------+-----------------------------+
| Time|root.ln.wf02.wt02.temperature|root.ln.wf02.wt01.temperature|root.ln.wf01.wt02.temperature|root.ln.wf01.wt01.temperature|
+-----------------------------+-----------------------------+-----------------------------+-----------------------------+-----------------------------+
|2021-05-11T22:18:14.598+08:00| 121.0| 72.0| 183.0| 115.0|
|2021-05-11T22:18:19.941+08:00| 0.0| 68.0| 68.0| 103.0|
|2021-05-11T22:18:24.949+08:00| 122.0| 45.0| 11.0| 14.0|
|2021-05-11T22:18:29.967+08:00| 47.0| 14.0| 59.0| 181.0|
|2021-05-11T22:18:34.979+08:00| 182.0| 113.0| 29.0| 180.0|
|2021-05-11T22:18:39.990+08:00| 42.0| 11.0| 52.0| 19.0|
|2021-05-11T22:18:44.995+08:00| 78.0| 38.0| 123.0| 52.0|
|2021-05-11T22:18:49.999+08:00| 137.0| 172.0| 135.0| 193.0|
|2021-05-11T22:18:55.003+08:00| 16.0| 124.0| 183.0| 18.0|
+-----------------------------+-----------------------------+-----------------------------+-----------------------------+-----------------------------+3.1 配置连续查询执行的周期性间隔
在RESAMPLE子句中使用EVERY参数指定连续查询的执行间隔,如果没有指定,默认等于group_by_interval。
CREATE CONTINUOUS QUERY cq1
RESAMPLE EVERY 20s
BEGIN
SELECT max_value(temperature)
INTO root.ln.wf02.wt02(temperature_max), root.ln.wf02.wt01(temperature_max), root.ln.wf01.wt02(temperature_max), root.ln.wf01.wt01(temperature_max)
FROM root.ln.*.*
GROUP BY(10s)
ENDcq1计算出temperature传感器每10秒的平均值,并且将查询结果存储在temperature_max传感器下,传感器路径前缀使用跟原来一样的前缀。
cq1每20秒执行一次,每次执行的查询的时间窗口范围是从过去20秒到当前时间。
假设当前时间是2021-05-11T22:18:40.000+08:00,如果把日志等级设置为DEBUG,我们可以在cq1执行的DataNode上看到如下的输出:
At **2021-05-11T22:18:40.000+08:00**, `cq1` executes a query within the time range `[2021-05-11T22:18:20, 2021-05-11T22:18:40)`.
`cq1` generate 2 lines:
>
+-----------------------------+---------------------------------+---------------------------------+---------------------------------+---------------------------------+
| Time|root.ln.wf02.wt02.temperature_max|root.ln.wf02.wt01.temperature_max|root.ln.wf01.wt02.temperature_max|root.ln.wf01.wt01.temperature_max|
+-----------------------------+---------------------------------+---------------------------------+---------------------------------+---------------------------------+
|2021-05-11T22:18:20.000+08:00| 122.0| 45.0| 59.0| 181.0|
|2021-05-11T22:18:30.000+08:00| 182.0| 113.0| 52.0| 180.0|
+-----------------------------+---------------------------------+---------------------------------+---------------------------------+---------------------------------+
>
At **2021-05-11T22:19:00.000+08:00**, `cq1` executes a query within the time range `[2021-05-11T22:18:40, 2021-05-11T22:19:00)`.
`cq1` generate 2 lines:
>
+-----------------------------+---------------------------------+---------------------------------+---------------------------------+---------------------------------+
| Time|root.ln.wf02.wt02.temperature_max|root.ln.wf02.wt01.temperature_max|root.ln.wf01.wt02.temperature_max|root.ln.wf01.wt01.temperature_max|
+-----------------------------+---------------------------------+---------------------------------+---------------------------------+---------------------------------+
|2021-05-11T22:18:40.000+08:00| 137.0| 172.0| 135.0| 193.0|
|2021-05-11T22:18:50.000+08:00| 16.0| 124.0| 183.0| 18.0|
+-----------------------------+---------------------------------+---------------------------------+---------------------------------+---------------------------------+
>cq1并不会处理当前时间窗口以外的数据,即2021-05-11T22:18:20.000+08:00以前的数据,所以我们会得到如下结果:
> SELECT temperature_max from root.ln.*.*;
+-----------------------------+---------------------------------+---------------------------------+---------------------------------+---------------------------------+
| Time|root.ln.wf02.wt02.temperature_max|root.ln.wf02.wt01.temperature_max|root.ln.wf01.wt02.temperature_max|root.ln.wf01.wt01.temperature_max|
+-----------------------------+---------------------------------+---------------------------------+---------------------------------+---------------------------------+
|2021-05-11T22:18:20.000+08:00| 122.0| 45.0| 59.0| 181.0|
|2021-05-11T22:18:30.000+08:00| 182.0| 113.0| 52.0| 180.0|
|2021-05-11T22:18:40.000+08:00| 137.0| 172.0| 135.0| 193.0|
|2021-05-11T22:18:50.000+08:00| 16.0| 124.0| 183.0| 18.0|
+-----------------------------+---------------------------------+---------------------------------+---------------------------------+---------------------------------+3.2 配置连续查询的时间窗口大小
使用RANGE子句中的start_time_offset参数指定连续查询每次执行的时间窗口的开始时间偏移,如果没有指定,默认值等于EVERY参数。
CREATE CONTINUOUS QUERY cq2
RESAMPLE RANGE 40s
BEGIN
SELECT max_value(temperature)
INTO root.ln.wf02.wt02(temperature_max), root.ln.wf02.wt01(temperature_max), root.ln.wf01.wt02(temperature_max), root.ln.wf01.wt01(temperature_max)
FROM root.ln.*.*
GROUP BY(10s)
ENDcq2计算出temperature传感器每10秒的平均值,并且将查询结果存储在temperature_max传感器下,传感器路径前缀使用跟原来一样的前缀。
cq2每10秒执行一次,每次执行的查询的时间窗口范围是从过去40秒到当前时间。
假设当前时间是2021-05-11T22:18:40.000+08:00,如果把日志等级设置为DEBUG,我们可以在cq2执行的DataNode上看到如下的输出:
At **2021-05-11T22:18:40.000+08:00**, `cq2` executes a query within the time range `[2021-05-11T22:18:00, 2021-05-11T22:18:40)`.
`cq2` generate 4 lines:
>
+-----------------------------+---------------------------------+---------------------------------+---------------------------------+---------------------------------+
| Time|root.ln.wf02.wt02.temperature_max|root.ln.wf02.wt01.temperature_max|root.ln.wf01.wt02.temperature_max|root.ln.wf01.wt01.temperature_max|
+-----------------------------+---------------------------------+---------------------------------+---------------------------------+---------------------------------+
|2021-05-11T22:18:00.000+08:00| NULL| NULL| NULL| NULL|
|2021-05-11T22:18:10.000+08:00| 121.0| 72.0| 183.0| 115.0|
|2021-05-11T22:18:20.000+08:00| 122.0| 45.0| 59.0| 181.0|
|2021-05-11T22:18:30.000+08:00| 182.0| 113.0| 52.0| 180.0|
+-----------------------------+---------------------------------+---------------------------------+---------------------------------+---------------------------------+
>
At **2021-05-11T22:18:50.000+08:00**, `cq2` executes a query within the time range `[2021-05-11T22:18:10, 2021-05-11T22:18:50)`.
`cq2` generate 4 lines:
>
+-----------------------------+---------------------------------+---------------------------------+---------------------------------+---------------------------------+
| Time|root.ln.wf02.wt02.temperature_max|root.ln.wf02.wt01.temperature_max|root.ln.wf01.wt02.temperature_max|root.ln.wf01.wt01.temperature_max|
+-----------------------------+---------------------------------+---------------------------------+---------------------------------+---------------------------------+
|2021-05-11T22:18:10.000+08:00| 121.0| 72.0| 183.0| 115.0|
|2021-05-11T22:18:20.000+08:00| 122.0| 45.0| 59.0| 181.0|
|2021-05-11T22:18:30.000+08:00| 182.0| 113.0| 52.0| 180.0|
|2021-05-11T22:18:40.000+08:00| 137.0| 172.0| 135.0| 193.0|
+-----------------------------+---------------------------------+---------------------------------+---------------------------------+---------------------------------+
>
At **2021-05-11T22:19:00.000+08:00**, `cq2` executes a query within the time range `[2021-05-11T22:18:20, 2021-05-11T22:19:00)`.
`cq2` generate 4 lines:
>
+-----------------------------+---------------------------------+---------------------------------+---------------------------------+---------------------------------+
| Time|root.ln.wf02.wt02.temperature_max|root.ln.wf02.wt01.temperature_max|root.ln.wf01.wt02.temperature_max|root.ln.wf01.wt01.temperature_max|
+-----------------------------+---------------------------------+---------------------------------+---------------------------------+---------------------------------+
|2021-05-11T22:18:20.000+08:00| 122.0| 45.0| 59.0| 181.0|
|2021-05-11T22:18:30.000+08:00| 182.0| 113.0| 52.0| 180.0|
|2021-05-11T22:18:40.000+08:00| 137.0| 172.0| 135.0| 193.0|
|2021-05-11T22:18:50.000+08:00| 16.0| 124.0| 183.0| 18.0|
+-----------------------------+---------------------------------+---------------------------------+---------------------------------+---------------------------------+
>cq2并不会写入全是null值的行,值得注意的是cq2会多次计算某些区间的聚合值,下面是计算结果:
> SELECT temperature_max from root.ln.*.*;
+-----------------------------+---------------------------------+---------------------------------+---------------------------------+---------------------------------+
| Time|root.ln.wf02.wt02.temperature_max|root.ln.wf02.wt01.temperature_max|root.ln.wf01.wt02.temperature_max|root.ln.wf01.wt01.temperature_max|
+-----------------------------+---------------------------------+---------------------------------+---------------------------------+---------------------------------+
|2021-05-11T22:18:10.000+08:00| 121.0| 72.0| 183.0| 115.0|
|2021-05-11T22:18:20.000+08:00| 122.0| 45.0| 59.0| 181.0|
|2021-05-11T22:18:30.000+08:00| 182.0| 113.0| 52.0| 180.0|
|2021-05-11T22:18:40.000+08:00| 137.0| 172.0| 135.0| 193.0|
|2021-05-11T22:18:50.000+08:00| 16.0| 124.0| 183.0| 18.0|
+-----------------------------+---------------------------------+---------------------------------+---------------------------------+---------------------------------+3.3 同时配置连续查询执行的周期性间隔和时间窗口大小
使用RESAMPLE子句中的EVERY参数和RANGE参数分别指定连续查询的执行间隔和窗口大小。并且使用fill()来填充没有值的时间区间。
CREATE CONTINUOUS QUERY cq3
RESAMPLE EVERY 20s RANGE 40s
BEGIN
SELECT max_value(temperature)
INTO root.ln.wf02.wt02(temperature_max), root.ln.wf02.wt01(temperature_max), root.ln.wf01.wt02(temperature_max), root.ln.wf01.wt01(temperature_max)
FROM root.ln.*.*
GROUP BY(10s)
FILL(100.0)
ENDcq3计算出temperature传感器每10秒的平均值,并且将查询结果存储在temperature_max传感器下,传感器路径前缀使用跟原来一样的前缀。如果某些区间没有值,用100.0填充。
cq3每20秒执行一次,每次执行的查询的时间窗口范围是从过去40秒到当前时间。
假设当前时间是2021-05-11T22:18:40.000+08:00,如果把日志等级设置为DEBUG,我们可以在cq3执行的DataNode上看到如下的输出:
At **2021-05-11T22:18:40.000+08:00**, `cq3` executes a query within the time range `[2021-05-11T22:18:00, 2021-05-11T22:18:40)`.
`cq3` generate 4 lines:
>
+-----------------------------+---------------------------------+---------------------------------+---------------------------------+---------------------------------+
| Time|root.ln.wf02.wt02.temperature_max|root.ln.wf02.wt01.temperature_max|root.ln.wf01.wt02.temperature_max|root.ln.wf01.wt01.temperature_max|
+-----------------------------+---------------------------------+---------------------------------+---------------------------------+---------------------------------+
|2021-05-11T22:18:00.000+08:00| 100.0| 100.0| 100.0| 100.0|
|2021-05-11T22:18:10.000+08:00| 121.0| 72.0| 183.0| 115.0|
|2021-05-11T22:18:20.000+08:00| 122.0| 45.0| 59.0| 181.0|
|2021-05-11T22:18:30.000+08:00| 182.0| 113.0| 52.0| 180.0|
+-----------------------------+---------------------------------+---------------------------------+---------------------------------+---------------------------------+
>
At **2021-05-11T22:19:00.000+08:00**, `cq3` executes a query within the time range `[2021-05-11T22:18:20, 2021-05-11T22:19:00)`.
`cq3` generate 4 lines:
>
+-----------------------------+---------------------------------+---------------------------------+---------------------------------+---------------------------------+
| Time|root.ln.wf02.wt02.temperature_max|root.ln.wf02.wt01.temperature_max|root.ln.wf01.wt02.temperature_max|root.ln.wf01.wt01.temperature_max|
+-----------------------------+---------------------------------+---------------------------------+---------------------------------+---------------------------------+
|2021-05-11T22:18:20.000+08:00| 122.0| 45.0| 59.0| 181.0|
|2021-05-11T22:18:30.000+08:00| 182.0| 113.0| 52.0| 180.0|
|2021-05-11T22:18:40.000+08:00| 137.0| 172.0| 135.0| 193.0|
|2021-05-11T22:18:50.000+08:00| 16.0| 124.0| 183.0| 18.0|
+-----------------------------+---------------------------------+---------------------------------+---------------------------------+---------------------------------+
>值得注意的是cq3会多次计算某些区间的聚合值,下面是计算结果:
> SELECT temperature_max from root.ln.*.*;
+-----------------------------+---------------------------------+---------------------------------+---------------------------------+---------------------------------+
| Time|root.ln.wf02.wt02.temperature_max|root.ln.wf02.wt01.temperature_max|root.ln.wf01.wt02.temperature_max|root.ln.wf01.wt01.temperature_max|
+-----------------------------+---------------------------------+---------------------------------+---------------------------------+---------------------------------+
|2021-05-11T22:18:00.000+08:00| 100.0| 100.0| 100.0| 100.0|
|2021-05-11T22:18:10.000+08:00| 121.0| 72.0| 183.0| 115.0|
|2021-05-11T22:18:20.000+08:00| 122.0| 45.0| 59.0| 181.0|
|2021-05-11T22:18:30.000+08:00| 182.0| 113.0| 52.0| 180.0|
|2021-05-11T22:18:40.000+08:00| 137.0| 172.0| 135.0| 193.0|
|2021-05-11T22:18:50.000+08:00| 16.0| 124.0| 183.0| 18.0|
+-----------------------------+---------------------------------+---------------------------------+---------------------------------+---------------------------------+3.4 配置连续查询每次查询执行时间窗口的结束时间
使用RESAMPLE子句中的EVERY参数和RANGE参数分别指定连续查询的执行间隔和窗口大小。并且使用fill()来填充没有值的时间区间。
CREATE CONTINUOUS QUERY cq4
RESAMPLE EVERY 20s RANGE 40s, 20s
BEGIN
SELECT max_value(temperature)
INTO root.ln.wf02.wt02(temperature_max), root.ln.wf02.wt01(temperature_max), root.ln.wf01.wt02(temperature_max), root.ln.wf01.wt01(temperature_max)
FROM root.ln.*.*
GROUP BY(10s)
FILL(100.0)
ENDcq4计算出temperature传感器每10秒的平均值,并且将查询结果存储在temperature_max传感器下,传感器路径前缀使用跟原来一样的前缀。如果某些区间没有值,用100.0填充。
cq4每20秒执行一次,每次执行的查询的时间窗口范围是从过去40秒到过去20秒。
假设当前时间是2021-05-11T22:18:40.000+08:00,如果把日志等级设置为DEBUG,我们可以在cq4执行的DataNode上看到如下的输出:
At **2021-05-11T22:18:40.000+08:00**, `cq4` executes a query within the time range `[2021-05-11T22:18:00, 2021-05-11T22:18:20)`.
`cq4` generate 2 lines:
>
+-----------------------------+---------------------------------+---------------------------------+---------------------------------+---------------------------------+
| Time|root.ln.wf02.wt02.temperature_max|root.ln.wf02.wt01.temperature_max|root.ln.wf01.wt02.temperature_max|root.ln.wf01.wt01.temperature_max|
+-----------------------------+---------------------------------+---------------------------------+---------------------------------+---------------------------------+
|2021-05-11T22:18:00.000+08:00| 100.0| 100.0| 100.0| 100.0|
|2021-05-11T22:18:10.000+08:00| 121.0| 72.0| 183.0| 115.0|
+-----------------------------+---------------------------------+---------------------------------+---------------------------------+---------------------------------+
>
At **2021-05-11T22:19:00.000+08:00**, `cq4` executes a query within the time range `[2021-05-11T22:18:20, 2021-05-11T22:18:40)`.
`cq4` generate 2 lines:
>
+-----------------------------+---------------------------------+---------------------------------+---------------------------------+---------------------------------+
| Time|root.ln.wf02.wt02.temperature_max|root.ln.wf02.wt01.temperature_max|root.ln.wf01.wt02.temperature_max|root.ln.wf01.wt01.temperature_max|
+-----------------------------+---------------------------------+---------------------------------+---------------------------------+---------------------------------+
|2021-05-11T22:18:20.000+08:00| 122.0| 45.0| 59.0| 181.0|
|2021-05-11T22:18:30.000+08:00| 182.0| 113.0| 52.0| 180.0|
+-----------------------------+---------------------------------+---------------------------------+---------------------------------+---------------------------------+
>值得注意的是cq4只会计算每个聚合区间一次,并且每次开始执行计算的时间都会比当前的时间窗口结束时间迟20s, 下面是计算结果:
> SELECT temperature_max from root.ln.*.*;
+-----------------------------+---------------------------------+---------------------------------+---------------------------------+---------------------------------+
| Time|root.ln.wf02.wt02.temperature_max|root.ln.wf02.wt01.temperature_max|root.ln.wf01.wt02.temperature_max|root.ln.wf01.wt01.temperature_max|
+-----------------------------+---------------------------------+---------------------------------+---------------------------------+---------------------------------+
|2021-05-11T22:18:00.000+08:00| 100.0| 100.0| 100.0| 100.0|
|2021-05-11T22:18:10.000+08:00| 121.0| 72.0| 183.0| 115.0|
|2021-05-11T22:18:20.000+08:00| 122.0| 45.0| 59.0| 181.0|
|2021-05-11T22:18:30.000+08:00| 182.0| 113.0| 52.0| 180.0|
+-----------------------------+---------------------------------+---------------------------------+---------------------------------+---------------------------------+3.5 没有GROUP BY TIME子句的连续查询
不使用GROUP BY TIME子句,并在RESAMPLE子句中显式使用EVERY参数指定连续查询的执行间隔。
CREATE CONTINUOUS QUERY cq5
RESAMPLE EVERY 20s
BEGIN
SELECT temperature + 1
INTO root.precalculated_sg.::(temperature)
FROM root.ln.*.*
align by device
ENDcq5计算以root.ln为前缀的所有temperature + 1的值,并将结果储存在另一个 database root.precalculated_sg中。除 database 名称不同外,目标序列与源序列路径名均相同。
cq5每20秒执行一次,每次执行的查询的时间窗口范围是从过去20秒到当前时间。
假设当前时间是2021-05-11T22:18:40.000+08:00,如果把日志等级设置为DEBUG,我们可以在cq5执行的DataNode上看到如下的输出:
At **2021-05-11T22:18:40.000+08:00**, `cq5` executes a query within the time range `[2021-05-11T22:18:20, 2021-05-11T22:18:40)`.
`cq5` generate 16 lines:
>
+-----------------------------+-------------------------------+-----------+
| Time| Device|temperature|
+-----------------------------+-------------------------------+-----------+
|2021-05-11T22:18:24.949+08:00|root.precalculated_sg.wf02.wt02| 123.0|
|2021-05-11T22:18:29.967+08:00|root.precalculated_sg.wf02.wt02| 48.0|
|2021-05-11T22:18:34.979+08:00|root.precalculated_sg.wf02.wt02| 183.0|
|2021-05-11T22:18:39.990+08:00|root.precalculated_sg.wf02.wt02| 45.0|
|2021-05-11T22:18:24.949+08:00|root.precalculated_sg.wf02.wt01| 46.0|
|2021-05-11T22:18:29.967+08:00|root.precalculated_sg.wf02.wt01| 15.0|
|2021-05-11T22:18:34.979+08:00|root.precalculated_sg.wf02.wt01| 114.0|
|2021-05-11T22:18:39.990+08:00|root.precalculated_sg.wf02.wt01| 12.0|
|2021-05-11T22:18:24.949+08:00|root.precalculated_sg.wf01.wt02| 12.0|
|2021-05-11T22:18:29.967+08:00|root.precalculated_sg.wf01.wt02| 60.0|
|2021-05-11T22:18:34.979+08:00|root.precalculated_sg.wf01.wt02| 30.0|
|2021-05-11T22:18:39.990+08:00|root.precalculated_sg.wf01.wt02| 53.0|
|2021-05-11T22:18:24.949+08:00|root.precalculated_sg.wf01.wt01| 15.0|
|2021-05-11T22:18:29.967+08:00|root.precalculated_sg.wf01.wt01| 182.0|
|2021-05-11T22:18:34.979+08:00|root.precalculated_sg.wf01.wt01| 181.0|
|2021-05-11T22:18:39.990+08:00|root.precalculated_sg.wf01.wt01| 20.0|
+-----------------------------+-------------------------------+-----------+
>
At **2021-05-11T22:19:00.000+08:00**, `cq5` executes a query within the time range `[2021-05-11T22:18:40, 2021-05-11T22:19:00)`.
`cq5` generate 12 lines:
>
+-----------------------------+-------------------------------+-----------+
| Time| Device|temperature|
+-----------------------------+-------------------------------+-----------+
|2021-05-11T22:18:44.995+08:00|root.precalculated_sg.wf02.wt02| 79.0|
|2021-05-11T22:18:49.999+08:00|root.precalculated_sg.wf02.wt02| 138.0|
|2021-05-11T22:18:55.003+08:00|root.precalculated_sg.wf02.wt02| 17.0|
|2021-05-11T22:18:44.995+08:00|root.precalculated_sg.wf02.wt01| 39.0|
|2021-05-11T22:18:49.999+08:00|root.precalculated_sg.wf02.wt01| 173.0|
|2021-05-11T22:18:55.003+08:00|root.precalculated_sg.wf02.wt01| 125.0|
|2021-05-11T22:18:44.995+08:00|root.precalculated_sg.wf01.wt02| 124.0|
|2021-05-11T22:18:49.999+08:00|root.precalculated_sg.wf01.wt02| 136.0|
|2021-05-11T22:18:55.003+08:00|root.precalculated_sg.wf01.wt02| 184.0|
|2021-05-11T22:18:44.995+08:00|root.precalculated_sg.wf01.wt01| 53.0|
|2021-05-11T22:18:49.999+08:00|root.precalculated_sg.wf01.wt01| 194.0|
|2021-05-11T22:18:55.003+08:00|root.precalculated_sg.wf01.wt01| 19.0|
+-----------------------------+-------------------------------+-----------+
>cq5并不会处理当前时间窗口以外的数据,即2021-05-11T22:18:20.000+08:00以前的数据,所以我们会得到如下结果:
> SELECT temperature from root.precalculated_sg.*.* align by device;
+-----------------------------+-------------------------------+-----------+
| Time| Device|temperature|
+-----------------------------+-------------------------------+-----------+
|2021-05-11T22:18:24.949+08:00|root.precalculated_sg.wf02.wt02| 123.0|
|2021-05-11T22:18:29.967+08:00|root.precalculated_sg.wf02.wt02| 48.0|
|2021-05-11T22:18:34.979+08:00|root.precalculated_sg.wf02.wt02| 183.0|
|2021-05-11T22:18:39.990+08:00|root.precalculated_sg.wf02.wt02| 45.0|
|2021-05-11T22:18:44.995+08:00|root.precalculated_sg.wf02.wt02| 79.0|
|2021-05-11T22:18:49.999+08:00|root.precalculated_sg.wf02.wt02| 138.0|
|2021-05-11T22:18:55.003+08:00|root.precalculated_sg.wf02.wt02| 17.0|
|2021-05-11T22:18:24.949+08:00|root.precalculated_sg.wf02.wt01| 46.0|
|2021-05-11T22:18:29.967+08:00|root.precalculated_sg.wf02.wt01| 15.0|
|2021-05-11T22:18:34.979+08:00|root.precalculated_sg.wf02.wt01| 114.0|
|2021-05-11T22:18:39.990+08:00|root.precalculated_sg.wf02.wt01| 12.0|
|2021-05-11T22:18:44.995+08:00|root.precalculated_sg.wf02.wt01| 39.0|
|2021-05-11T22:18:49.999+08:00|root.precalculated_sg.wf02.wt01| 173.0|
|2021-05-11T22:18:55.003+08:00|root.precalculated_sg.wf02.wt01| 125.0|
|2021-05-11T22:18:24.949+08:00|root.precalculated_sg.wf01.wt02| 12.0|
|2021-05-11T22:18:29.967+08:00|root.precalculated_sg.wf01.wt02| 60.0|
|2021-05-11T22:18:34.979+08:00|root.precalculated_sg.wf01.wt02| 30.0|
|2021-05-11T22:18:39.990+08:00|root.precalculated_sg.wf01.wt02| 53.0|
|2021-05-11T22:18:44.995+08:00|root.precalculated_sg.wf01.wt02| 124.0|
|2021-05-11T22:18:49.999+08:00|root.precalculated_sg.wf01.wt02| 136.0|
|2021-05-11T22:18:55.003+08:00|root.precalculated_sg.wf01.wt02| 184.0|
|2021-05-11T22:18:24.949+08:00|root.precalculated_sg.wf01.wt01| 15.0|
|2021-05-11T22:18:29.967+08:00|root.precalculated_sg.wf01.wt01| 182.0|
|2021-05-11T22:18:34.979+08:00|root.precalculated_sg.wf01.wt01| 181.0|
|2021-05-11T22:18:39.990+08:00|root.precalculated_sg.wf01.wt01| 20.0|
|2021-05-11T22:18:44.995+08:00|root.precalculated_sg.wf01.wt01| 53.0|
|2021-05-11T22:18:49.999+08:00|root.precalculated_sg.wf01.wt01| 194.0|
|2021-05-11T22:18:55.003+08:00|root.precalculated_sg.wf01.wt01| 19.0|
+-----------------------------+-------------------------------+-----------+4. 连续查询的管理
4.1 查询系统已有的连续查询
展示集群中所有的已注册的连续查询
SHOW (CONTINUOUS QUERIES | CQS)SHOW (CONTINUOUS QUERIES | CQS)会将结果集按照cq_id排序。
例子
SHOW CONTINUOUS QUERIES;执行以上sql,我们将会得到如下的查询结果:
| cq_id | query | state |
|---|---|---|
| s1_count_cq | CREATE CQ s1_count_cq BEGIN SELECT count(s1) INTO root.sg_count.d.count_s1 FROM root.sg.d GROUP BY(30m) END | active |
4.2 删除已有的连续查询
删除指定的名为cq_id的连续查询:
DROP (CONTINUOUS QUERY | CQ) <cq_id>DROP CQ并不会返回任何结果集。
例子
删除名为s1_count_cq的连续查询:
DROP CONTINUOUS QUERY s1_count_cq;4.3 修改已有的连续查询
目前连续查询一旦被创建就不能再被修改。如果想要修改某个连续查询,只能先用DROP命令删除它,然后再用CREATE命令重新创建。
5. 连续查询的使用场景
5.1 对数据进行降采样并对降采样后的数据使用不同的保留策略
可以使用连续查询,定期将高频率采样的原始数据(如每秒1000个点),降采样(如每秒仅保留一个点)后保存到另一个 database 的同名序列中。高精度的原始数据所在 database 的TTL可能设置的比较短,比如一天,而低精度的降采样后的数据所在的 database TTL可以设置的比较长,比如一个月,从而达到快速释放磁盘空间的目的。
5.2 预计算代价昂贵的查询
我们可以通过连续查询对一些重复的查询进行预计算,并将查询结果保存在某些目标序列中,这样真实查询并不需要真的再次去做计算,而是直接查询目标序列的结果,从而缩短了查询的时间。
预计算查询结果尤其对一些可视化工具渲染时序图和工作台时有很大的加速作用。
5.3 作为子查询的替代品
IoTDB现在不支持子查询,但是我们可以通过创建连续查询得到相似的功能。我们可以将子查询注册为一个连续查询,并将子查询的结果物化到目标序列中,外层查询再直接查询哪个目标序列。
例子
IoTDB并不会接收如下的嵌套子查询。这个查询会计算s1序列每隔30分钟的非空值数量的平均值:
SELECT avg(count_s1) from (select count(s1) as count_s1 from root.sg.d group by([0, now()), 30m));为了得到相同的结果,我们可以:
1. 创建一个连续查询
这一步执行内层子查询部分。下面创建的连续查询每隔30分钟计算一次root.sg.d.s1序列的非空值数量,并将结果写入目标序列root.sg_count.d.count_s1中。
CREATE CQ s1_count_cq
BEGIN
SELECT count(s1)
INTO root.sg_count.d(count_s1)
FROM root.sg.d
GROUP BY(30m)
END2. 查询连续查询的结果
这一步执行外层查询的avg([...])部分。
查询序列root.sg_count.d.count_s1的值,并计算平均值:
SELECT avg(count_s1) from root.sg_count.d;6. 连续查询相关的配置参数
| 参数名 | 描述 | 类型 | 默认值 |
|---|---|---|---|
continuous_query_submit_thread_count | 用于周期性提交连续查询执行任务的线程数 | int32 | 2 |
continuous_query_min_every_interval_in_ms | 系统允许的连续查询最小的周期性时间间隔 | duration | 1000 |