
Dual Active Deployment
Dual Active Deployment
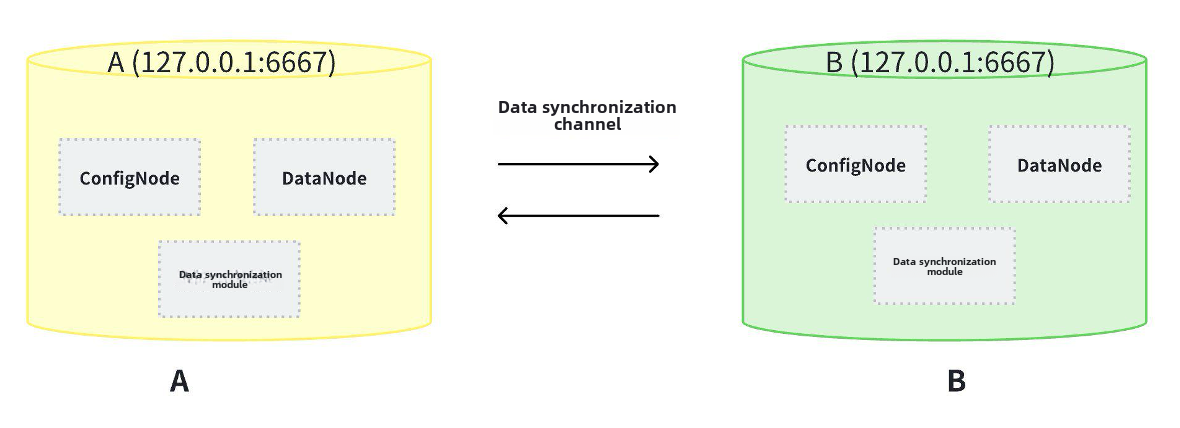
1. What is a double active version?
Dual active usually refers to two independent machines (or clusters) that perform real-time mirror synchronization. Their configurations are completely independent and can simultaneously receive external writes. Each independent machine (or cluster) can synchronize the data written to itself to another machine (or cluster), and the data of the two machines (or clusters) can achieve final consistency.
- Two standalone machines (or clusters) can form a high availability group: when one of the standalone machines (or clusters) stops serving, the other standalone machine (or cluster) will not be affected. When the single machine (or cluster) that stopped the service is restarted, another single machine (or cluster) will synchronize the newly written data. Business can be bound to two standalone machines (or clusters) for read and write operations, thereby achieving high availability.
- The dual active deployment scheme allows for high availability with fewer than 3 physical nodes and has certain advantages in deployment costs. At the same time, the physical supply isolation of two sets of single machines (or clusters) can be achieved through the dual ring network of power and network, ensuring the stability of operation.
- At present, the dual active capability is a feature of the enterprise version.
2. Note
It is recommended to prioritize using
hostnamefor IP configuration during deployment to avoid the problem of database failure caused by modifying the host IP in the later stage. To set the hostname, you need to configure/etc/hostson the target server. If the local IP is 192.168.1.3 and the hostname is iotdb-1, you can use the following command to set the server's hostname and configure IoTDB'scn_internal-addressanddn_internal-addressusing the hostname.echo "192.168.1.3 iotdb-1" >> /etc/hostsSome parameters cannot be modified after the first startup, please refer to the "Installation Steps" section below to set them.
Recommend deploying a monitoring panel, which can monitor important operational indicators and keep track of database operation status at any time. The monitoring panel can be obtained by contacting the business department. The steps for deploying the monitoring panel can be referred to Monitoring Panel Deployment
3. Installation Steps
Taking the dual active version IoTDB built by two single machines A and B as an example, the IP addresses of A and B are 192.168.1.3 and 192.168.1.4, respectively. Here, we use hostname to represent different hosts. The plan is as follows:
| Machine | Machine IP | Host Name |
|---|---|---|
| A | 192.168.1.3 | iotdb-1 |
| B | 192.168.1.4 | iotdb-2 |
3.1 Install Two Independent IoTDBs Separately
Install IoTDB on two machines separately, and refer to the deployment documentation for the standalone version Stand-Alone Deployment,The deployment document for the cluster version can be referred to Cluster Deployment。It is recommended that the configurations of clusters A and B remain consistent to achieve the best dual active effect
3.2 Create A Aata Synchronization Task On Machine A To Machine B
Create a data synchronization process on machine A, where the data on machine A is automatically synchronized to machine B. Use the cli tool in the sbin directory to connect to the IoTDB database on machine A:
# Unix/OS X ./sbin/start-cli.sh -h iotdb-1 # Windows # Before version V2.0.4.x .\sbin\start-cli.bat -h iotdb-1 # V2.0.4.x and later versions .\sbin\windows\start-cli.bat -h iotdb-1Create and start the data synchronization command with the following SQL:
create pipe AB with source ( 'source.forwarding-pipe-requests' = 'false' ) with sink ( 'sink'='iotdb-thrift-sink', 'sink.ip'='iotdb-2', 'sink.port'='6667' )Note: To avoid infinite data loops, it is necessary to set the parameter
source. forwarding pipe questionson both A and B tofalse, indicating that data transmitted from another pipe will not be forwarded.
3.3 Create A Data Synchronization Task On Machine B To Machine A
Create a data synchronization process on machine B, where the data on machine B is automatically synchronized to machine A. Use the cli tool in the sbin directory to connect to the IoTDB database on machine B
# Unix/OS X ./sbin/start-cli.sh -h iotdb-2 # Windows # Before version V2.0.4.x .\sbin\start-cli.bat -h iotdb-2 # V2.0.4.x and later versions .\sbin\windows\start-cli.bat -h iotdb-2Create and start the pipe with the following SQL:
create pipe BA with source ( 'source.forwarding-pipe-requests' = 'false' ) with sink ( 'sink'='iotdb-thrift-sink', 'sink.ip'='iotdb-1', 'sink.port'='6667' )Note: To avoid infinite data loops, it is necessary to set the parameter
source. forwarding pipe questionson both A and B tofalse, indicating that data transmitted from another pipe will not be forwarded.
3.4 Validate Deployment
After the above data synchronization process is created, the dual active cluster can be started.
Check the running status of the cluster
#Execute the show cluster command on two nodes respectively to check the status of IoTDB service
show clusterMachine A:

Machine B:

Ensure that every Configurable Node and DataNode is in the Running state.
Check synchronization status
- Check the synchronization status on machine A
show pipes
- Check the synchronization status on machine B
show pipes
Ensure that every pipe is in the RUNNING state.
3.5 Stop Dual Active Version IoTDB
Execute the following command on machine A:
# Unix/OS X ./sbin/start-cli.sh -h iotdb-1 #Log in to CLI IoTDB> stop pipe AB #Stop the data synchronization process ./sbin/stop-standalone.sh #Stop database service # Windows # Before version V2.0.4.x .\sbin\start-cli.bat -h iotdb-1 IoTDB> stop pipe AB .\sbin\stop-standalone.bat # V2.0.4.x and later versions .\sbin\windows\start-cli.bat -h iotdb-1 IoTDB> stop pipe AB .\sbin\windows\stop-standalone.batExecute the following command on machine B:
# Unix/OS X ./sbin/start-cli.sh -h iotdb-2 #Log in to CLI IoTDB> stop pipe BA #Stop the data synchronization process ./sbin/stop-standalone.sh #Stop database service # Windows # Before version V2.0.4.x .\sbin\start-cli.bat -h iotdb-2 IoTDB> stop pipe BA .\sbin\stop-standalone.bat # V2.0.4.x and later versions .\sbin\windows\start-cli.bat -h iotdb-2 IoTDB> stop pipe BA .\sbin\windows\stop-standalone.bat