
数据查询
数据查询
概述
在 IoTDB 中,使用 SELECT 语句从一条或多条时间序列中查询数据,IoTDB 不区分历史数据和实时数据,用户可以用统一的sql语法进行查询,通过 WHERE 子句中的时间过滤谓词决定查询的时间范围。
语法定义
SELECT [LAST] selectExpr [, selectExpr] ...
[INTO intoItem [, intoItem] ...]
FROM prefixPath [, prefixPath] ...
[WHERE whereCondition]
[GROUP BY {
([startTime, endTime), interval [, slidingStep]) |
LEVEL = levelNum [, levelNum] ... |
TAGS(tagKey [, tagKey] ... |
VARIATION(expression[,delta][,ignoreNull=true/false]) |
CONDITION(expression,[keep>/>=/=/</<=]threshold[,ignoreNull=true/false]) |
SESSION(timeInterval) |
COUNT(expression, size[,ignoreNull=true/false])
}]
[HAVING havingCondition]
[ORDER BY sortKey {ASC | DESC}]
[FILL ({PREVIOUS | LINEAR | constant}) (, interval=DURATION_LITERAL)?)]
[SLIMIT seriesLimit] [SOFFSET seriesOffset]
[LIMIT rowLimit] [OFFSET rowOffset]
[ALIGN BY {TIME | DEVICE}]
语法说明
SELECT 子句
SELECT子句指定查询的输出,由若干个selectExpr组成。- 每个
selectExpr定义查询结果中的一列或多列,它是一个由时间序列路径后缀、常量、函数和运算符组成的表达式。 - 支持使用
AS为查询结果集中的列指定别名。 - 在
SELECT子句中使用LAST关键词可以指定查询为最新点查询
INTO 子句
SELECT INTO用于将查询结果写入一系列指定的时间序列中。INTO子句指定了查询结果写入的目标时间序列。
FROM 子句
FROM子句包含要查询的一个或多个时间序列的路径前缀,支持使用通配符。- 在执行查询时,会将
FROM子句中的路径前缀和SELECT子句中的后缀进行拼接得到完整的查询目标序列。
WHERE 子句
WHERE子句指定了对数据行的筛选条件,由一个whereCondition组成。whereCondition是一个逻辑表达式,对于要选择的每一行,其计算结果为真。如果没有WHERE子句,将选择所有行。- 在
whereCondition中,可以使用除聚合函数之外的任何 IOTDB 支持的函数和运算符。
GROUP BY 子句
GROUP BY子句指定对序列进行分段或分组聚合的方式。- 分段聚合是指按照时间维度,针对同时间序列中不同数据点之间的时间关系,对数据在行的方向进行分段,每个段得到一个聚合值。目前支持时间区间分段、差值分段、条件分段、会话分段和点数分段,未来将支持更多分段方式。
- 分组聚合是指针对不同时间序列,在时间序列的潜在业务属性上分组,每个组包含若干条时间序列,每个组得到一个聚合值。支持按路径层级分组和按序列标签分组两种分组方式。
- 分段聚合和分组聚合可以混合使用。
HAVING 子句
HAVING子句指定了对聚合结果的筛选条件,由一个havingCondition组成。havingCondition是一个逻辑表达式,对于要选择的聚合结果,其计算结果为真。如果没有HAVING子句,将选择所有聚合结果。HAVING要和聚合函数以及GROUP BY子句一起使用。
ORDER BY 子句
ORDER BY子句用于指定结果集的排序方式。- 按时间对齐模式下:默认按照时间戳大小升序排列,可以通过
ORDER BY TIME DESC指定结果集按照时间戳大小降序排列。 - 按设备对齐模式下:默认按照设备名的字典序升序排列,每个设备内部按照时间戳大小升序排列,可以通过
ORDER BY子句调整设备列和时间列的排序优先级。
FILL 子句
FILL子句用于指定数据缺失情况下的填充模式,允许用户按照特定的方法对任何查询的结果集填充空值。
SLIMIT 和 SOFFSET 子句
SLIMIT指定查询结果的列数,SOFFSET指定查询结果显示的起始列位置。SLIMIT和SOFFSET仅用于控制值列,对时间列和设备列无效。
LIMIT 和 OFFSET 子句
LIMIT指定查询结果的行数,OFFSET指定查询结果显示的起始行位置。
ALIGN BY 子句
- 查询结果集默认按时间对齐,包含一列时间列和若干个值列,每一行数据各列的时间戳相同。
- 除按时间对齐之外,还支持按设备对齐,查询结果集包含一列时间列、一列设备列和若干个值列。
SQL 示例
IoTDB 支持即席(Ad_hoc)查询,即支持用户在使用系统时,自定义查询条件,根据自己当时的需求写出查询sql并执行。用户可以通过上述介绍的子句,进行组合,指定任意合法的过滤条件来满足当时的查询需求,下面介绍了一些查询的示例:
示例1:根据一个时间区间选择一列数据
SQL 语句为:
select temperature from root.ln.wf01.wt01 where time < 2017-11-01T00:08:00.000
其含义为:
被选择的设备为 ln 集团 wf01 子站 wt01 设备;被选择的时间序列为温度传感器(temperature);该语句要求选择出该设备在 “2017-11-01T00:08:00.000” 时间点以前的所有温度传感器的值。
该 SQL 语句的执行结果如下:
+-----------------------------+-----------------------------+
| Time|root.ln.wf01.wt01.temperature|
+-----------------------------+-----------------------------+
|2017-11-01T00:00:00.000+08:00| 25.96|
|2017-11-01T00:01:00.000+08:00| 24.36|
|2017-11-01T00:02:00.000+08:00| 20.09|
|2017-11-01T00:03:00.000+08:00| 20.18|
|2017-11-01T00:04:00.000+08:00| 21.13|
|2017-11-01T00:05:00.000+08:00| 22.72|
|2017-11-01T00:06:00.000+08:00| 20.71|
|2017-11-01T00:07:00.000+08:00| 21.45|
+-----------------------------+-----------------------------+
Total line number = 8
It costs 0.026s
示例2:根据一个时间区间选择多列数据
SQL 语句为:
select status, temperature from root.ln.wf01.wt01 where time > 2017-11-01T00:05:00.000 and time < 2017-11-01T00:12:00.000;
其含义为:
被选择的设备为 ln 集团 wf01 子站 wt01 设备;被选择的时间序列为供电状态(status)和温度传感器(temperature);该语句要求选择出 “2017-11-01T00:05:00.000” 至 “2017-11-01T00:12:00.000” 之间的所选时间序列的值。
该 SQL 语句的执行结果如下:
+-----------------------------+------------------------+-----------------------------+
| Time|root.ln.wf01.wt01.status|root.ln.wf01.wt01.temperature|
+-----------------------------+------------------------+-----------------------------+
|2017-11-01T00:06:00.000+08:00| false| 20.71|
|2017-11-01T00:07:00.000+08:00| false| 21.45|
|2017-11-01T00:08:00.000+08:00| false| 22.58|
|2017-11-01T00:09:00.000+08:00| false| 20.98|
|2017-11-01T00:10:00.000+08:00| true| 25.52|
|2017-11-01T00:11:00.000+08:00| false| 22.91|
+-----------------------------+------------------------+-----------------------------+
Total line number = 6
It costs 0.018s
示例3:按照多个时间区间选择同一设备的多列数据
IoTDB 支持在一次查询中指定多个时间区间条件,用户可以根据需求随意组合时间区间条件。例如,
SQL 语句为:
select status, temperature from root.ln.wf01.wt01 where (time > 2017-11-01T00:05:00.000 and time < 2017-11-01T00:12:00.000) or (time >= 2017-11-01T16:35:00.000 and time <= 2017-11-01T16:37:00.000);
其含义为:
被选择的设备为 ln 集团 wf01 子站 wt01 设备;被选择的时间序列为“供电状态(status)”和“温度传感器(temperature)”;该语句指定了两个不同的时间区间,分别为“2017-11-01T00:05:00.000 至 2017-11-01T00:12:00.000”和“2017-11-01T16:35:00.000 至 2017-11-01T16:37:00.000”;该语句要求选择出满足任一时间区间的被选时间序列的值。
该 SQL 语句的执行结果如下:
+-----------------------------+------------------------+-----------------------------+
| Time|root.ln.wf01.wt01.status|root.ln.wf01.wt01.temperature|
+-----------------------------+------------------------+-----------------------------+
|2017-11-01T00:06:00.000+08:00| false| 20.71|
|2017-11-01T00:07:00.000+08:00| false| 21.45|
|2017-11-01T00:08:00.000+08:00| false| 22.58|
|2017-11-01T00:09:00.000+08:00| false| 20.98|
|2017-11-01T00:10:00.000+08:00| true| 25.52|
|2017-11-01T00:11:00.000+08:00| false| 22.91|
|2017-11-01T16:35:00.000+08:00| true| 23.44|
|2017-11-01T16:36:00.000+08:00| false| 21.98|
|2017-11-01T16:37:00.000+08:00| false| 21.93|
+-----------------------------+------------------------+-----------------------------+
Total line number = 9
It costs 0.018s
示例4:按照多个时间区间选择不同设备的多列数据
该系统支持在一次查询中选择任意列的数据,也就是说,被选择的列可以来源于不同的设备。例如,SQL 语句为:
select wf01.wt01.status, wf02.wt02.hardware from root.ln where (time > 2017-11-01T00:05:00.000 and time < 2017-11-01T00:12:00.000) or (time >= 2017-11-01T16:35:00.000 and time <= 2017-11-01T16:37:00.000);
其含义为:
被选择的时间序列为 “ln 集团 wf01 子站 wt01 设备的供电状态” 以及 “ln 集团 wf02 子站 wt02 设备的硬件版本”;该语句指定了两个时间区间,分别为 “2017-11-01T00:05:00.000 至 2017-11-01T00:12:00.000” 和 “2017-11-01T16:35:00.000 至 2017-11-01T16:37:00.000”;该语句要求选择出满足任意时间区间的被选时间序列的值。
该 SQL 语句的执行结果如下:
+-----------------------------+------------------------+--------------------------+
| Time|root.ln.wf01.wt01.status|root.ln.wf02.wt02.hardware|
+-----------------------------+------------------------+--------------------------+
|2017-11-01T00:06:00.000+08:00| false| v1|
|2017-11-01T00:07:00.000+08:00| false| v1|
|2017-11-01T00:08:00.000+08:00| false| v1|
|2017-11-01T00:09:00.000+08:00| false| v1|
|2017-11-01T00:10:00.000+08:00| true| v2|
|2017-11-01T00:11:00.000+08:00| false| v1|
|2017-11-01T16:35:00.000+08:00| true| v2|
|2017-11-01T16:36:00.000+08:00| false| v1|
|2017-11-01T16:37:00.000+08:00| false| v1|
+-----------------------------+------------------------+--------------------------+
Total line number = 9
It costs 0.014s
示例5:根据时间降序返回结果集
IoTDB 支持 order by time 语句,用于对结果按照时间进行降序展示。例如,SQL 语句为:
select * from root.ln.** where time > 1 order by time desc limit 10;
语句执行的结果为:
+-----------------------------+--------------------------+------------------------+-----------------------------+------------------------+
| Time|root.ln.wf02.wt02.hardware|root.ln.wf02.wt02.status|root.ln.wf01.wt01.temperature|root.ln.wf01.wt01.status|
+-----------------------------+--------------------------+------------------------+-----------------------------+------------------------+
|2017-11-07T23:59:00.000+08:00| v1| false| 21.07| false|
|2017-11-07T23:58:00.000+08:00| v1| false| 22.93| false|
|2017-11-07T23:57:00.000+08:00| v2| true| 24.39| true|
|2017-11-07T23:56:00.000+08:00| v2| true| 24.44| true|
|2017-11-07T23:55:00.000+08:00| v2| true| 25.9| true|
|2017-11-07T23:54:00.000+08:00| v1| false| 22.52| false|
|2017-11-07T23:53:00.000+08:00| v2| true| 24.58| true|
|2017-11-07T23:52:00.000+08:00| v1| false| 20.18| false|
|2017-11-07T23:51:00.000+08:00| v1| false| 22.24| false|
|2017-11-07T23:50:00.000+08:00| v2| true| 23.7| true|
+-----------------------------+--------------------------+------------------------+-----------------------------+------------------------+
Total line number = 10
It costs 0.016s
查询执行接口
在 IoTDB 中,提供两种方式执行数据查询操作:
- 使用 IoTDB-SQL 执行查询。
- 常用查询的高效执行接口,包括时间序列原始数据范围查询、最新点查询、简单聚合查询。
使用 IoTDB-SQL 执行查询
数据查询语句支持在 SQL 命令行终端、JDBC、JAVA / C++ / Python / Go 等编程语言 API、RESTful API 中使用。
在 SQL 命令行终端中执行查询语句:启动 SQL 命令行终端,直接输入查询语句执行即可,详见 SQL 命令行终端。
在 JDBC 中执行查询语句,详见 JDBC 。
在 JAVA / C++ / Python / Go 等编程语言 API 中执行查询语句,详见应用编程接口一章相应文档。接口原型如下:
SessionDataSet executeQueryStatement(String sql);在 RESTful API 中使用,详见 HTTP API V1 或者 HTTP API V2。
常用查询的高效执行接口
各编程语言的 API 为常用的查询提供了高效执行接口,可以省去 SQL 解析等操作的耗时。包括:
- 时间序列原始数据范围查询:
- 指定的查询时间范围为左闭右开区间,包含开始时间但不包含结束时间。
SessionDataSet executeRawDataQuery(List<String> paths, long startTime, long endTime);
- 最新点查询:
- 查询最后一条时间戳大于等于某个时间点的数据。
SessionDataSet executeLastDataQuery(List<String> paths, long lastTime);
- 聚合查询:
- 支持指定查询时间范围。指定的查询时间范围为左闭右开区间,包含开始时间但不包含结束时间。
- 支持按照时间区间分段查询。
SessionDataSet executeAggregationQuery(List<String> paths, List<Aggregation> aggregations);
SessionDataSet executeAggregationQuery(
List<String> paths, List<Aggregation> aggregations, long startTime, long endTime);
SessionDataSet executeAggregationQuery(
List<String> paths,
List<Aggregation> aggregations,
long startTime,
long endTime,
long interval);
SessionDataSet executeAggregationQuery(
List<String> paths,
List<Aggregation> aggregations,
long startTime,
long endTime,
long interval,
long slidingStep);
选择表达式(SELECT FROM 子句)
SELECT 子句指定查询的输出,由若干个 selectExpr 组成。 每个 selectExpr 定义了查询结果中的一列或多列。
selectExpr 是一个由时间序列路径后缀、常量、函数和运算符组成的表达式。即 selectExpr 中可以包含:
- 时间序列路径后缀(支持使用通配符)
- 运算符
- 算数运算符
- 比较运算符
- 逻辑运算符
- 函数
- 聚合函数
- 时间序列生成函数(包括内置函数和用户自定义函数)
- 常量
使用别名
由于 IoTDB 独特的数据模型,在每个传感器前都附带有设备等诸多额外信息。有时,我们只针对某个具体设备查询,而这些前缀信息频繁显示造成了冗余,影响了结果集的显示与分析。
IoTDB 支持使用AS为查询结果集中的列指定别名。
示例:
select s1 as temperature, s2 as speed from root.ln.wf01.wt01;
结果集将显示为:
| Time | temperature | speed |
|---|---|---|
| ... | ... | ... |
运算符
IoTDB 中支持的运算符列表见文档 运算符和函数。
函数
聚合函数
聚合函数是多对一函数。它们对一组值进行聚合计算,得到单个聚合结果。
包含聚合函数的查询称为聚合查询,否则称为时间序列查询。
注意:聚合查询和时间序列查询不能混合使用。 下列语句是不支持的:
select s1, count(s1) from root.sg.d1;
select sin(s1), count(s1) from root.sg.d1;
select s1, count(s1) from root.sg.d1 group by ([10,100),10ms);
IoTDB 支持的聚合函数见文档 聚合函数。
时间序列生成函数
时间序列生成函数接受若干原始时间序列作为输入,产生一列时间序列输出。与聚合函数不同的是,时间序列生成函数的结果集带有时间戳列。
所有的时间序列生成函数都可以接受 * 作为输入,都可以与原始时间序列查询混合进行。
内置时间序列生成函数
IoTDB 中支持的内置函数列表见文档 运算符和函数。
自定义时间序列生成函数
IoTDB 支持通过用户自定义函数(点击查看: 用户自定义函数 )能力进行函数功能扩展。
嵌套表达式举例
IoTDB 支持嵌套表达式,由于聚合查询和时间序列查询不能在一条查询语句中同时出现,我们将支持的嵌套表达式分为时间序列查询嵌套表达式和聚合查询嵌套表达式两类。
时间序列查询嵌套表达式
IoTDB 支持在 SELECT 子句中计算由时间序列、常量、时间序列生成函数(包括用户自定义函数)和运算符组成的任意嵌套表达式。
说明:
- 当某个时间戳下左操作数和右操作数都不为空(
null)时,表达式才会有结果,否则表达式值为null,且默认不出现在结果集中。 - 如果表达式中某个操作数对应多条时间序列(如通配符
*),那么每条时间序列对应的结果都会出现在结果集中(按照笛卡尔积形式)。
示例 1:
select a,
b,
((a + 1) * 2 - 1) % 2 + 1.5,
sin(a + sin(a + sin(b))),
-(a + b) * (sin(a + b) * sin(a + b) + cos(a + b) * cos(a + b)) + 1
from root.sg1;
运行结果:
+-----------------------------+----------+----------+----------------------------------------+---------------------------------------------------+----------------------------------------------------------------------------------------------------------------------------------------------------------------+
| Time|root.sg1.a|root.sg1.b|((((root.sg1.a + 1) * 2) - 1) % 2) + 1.5|sin(root.sg1.a + sin(root.sg1.a + sin(root.sg1.b)))|(-root.sg1.a + root.sg1.b * ((sin(root.sg1.a + root.sg1.b) * sin(root.sg1.a + root.sg1.b)) + (cos(root.sg1.a + root.sg1.b) * cos(root.sg1.a + root.sg1.b)))) + 1|
+-----------------------------+----------+----------+----------------------------------------+---------------------------------------------------+----------------------------------------------------------------------------------------------------------------------------------------------------------------+
|1970-01-01T08:00:00.010+08:00| 1| 1| 2.5| 0.9238430524420609| -1.0|
|1970-01-01T08:00:00.020+08:00| 2| 2| 2.5| 0.7903505371876317| -3.0|
|1970-01-01T08:00:00.030+08:00| 3| 3| 2.5| 0.14065207680386618| -5.0|
|1970-01-01T08:00:00.040+08:00| 4| null| 2.5| null| null|
|1970-01-01T08:00:00.050+08:00| null| 5| null| null| null|
|1970-01-01T08:00:00.060+08:00| 6| 6| 2.5| -0.7288037411970916| -11.0|
+-----------------------------+----------+----------+----------------------------------------+---------------------------------------------------+----------------------------------------------------------------------------------------------------------------------------------------------------------------+
Total line number = 6
It costs 0.048s
示例 2:
select (a + b) * 2 + sin(a) from root.sg
运行结果:
+-----------------------------+----------------------------------------------+
| Time|((root.sg.a + root.sg.b) * 2) + sin(root.sg.a)|
+-----------------------------+----------------------------------------------+
|1970-01-01T08:00:00.010+08:00| 59.45597888911063|
|1970-01-01T08:00:00.020+08:00| 100.91294525072763|
|1970-01-01T08:00:00.030+08:00| 139.01196837590714|
|1970-01-01T08:00:00.040+08:00| 180.74511316047935|
|1970-01-01T08:00:00.050+08:00| 219.73762514629607|
|1970-01-01T08:00:00.060+08:00| 259.6951893788978|
|1970-01-01T08:00:00.070+08:00| 300.7738906815579|
|1970-01-01T08:00:00.090+08:00| 39.45597888911063|
|1970-01-01T08:00:00.100+08:00| 39.45597888911063|
+-----------------------------+----------------------------------------------+
Total line number = 9
It costs 0.011s
示例 3:
select (a + *) / 2 from root.sg1
运行结果:
+-----------------------------+-----------------------------+-----------------------------+
| Time|(root.sg1.a + root.sg1.a) / 2|(root.sg1.a + root.sg1.b) / 2|
+-----------------------------+-----------------------------+-----------------------------+
|1970-01-01T08:00:00.010+08:00| 1.0| 1.0|
|1970-01-01T08:00:00.020+08:00| 2.0| 2.0|
|1970-01-01T08:00:00.030+08:00| 3.0| 3.0|
|1970-01-01T08:00:00.040+08:00| 4.0| null|
|1970-01-01T08:00:00.060+08:00| 6.0| 6.0|
+-----------------------------+-----------------------------+-----------------------------+
Total line number = 5
It costs 0.011s
示例 4:
select (a + b) * 3 from root.sg, root.ln
运行结果:
+-----------------------------+---------------------------+---------------------------+---------------------------+---------------------------+
| Time|(root.sg.a + root.sg.b) * 3|(root.sg.a + root.ln.b) * 3|(root.ln.a + root.sg.b) * 3|(root.ln.a + root.ln.b) * 3|
+-----------------------------+---------------------------+---------------------------+---------------------------+---------------------------+
|1970-01-01T08:00:00.010+08:00| 90.0| 270.0| 360.0| 540.0|
|1970-01-01T08:00:00.020+08:00| 150.0| 330.0| 690.0| 870.0|
|1970-01-01T08:00:00.030+08:00| 210.0| 450.0| 570.0| 810.0|
|1970-01-01T08:00:00.040+08:00| 270.0| 240.0| 690.0| 660.0|
|1970-01-01T08:00:00.050+08:00| 330.0| null| null| null|
|1970-01-01T08:00:00.060+08:00| 390.0| null| null| null|
|1970-01-01T08:00:00.070+08:00| 450.0| null| null| null|
|1970-01-01T08:00:00.090+08:00| 60.0| null| null| null|
|1970-01-01T08:00:00.100+08:00| 60.0| null| null| null|
+-----------------------------+---------------------------+---------------------------+---------------------------+---------------------------+
Total line number = 9
It costs 0.014s
聚合查询嵌套表达式
IoTDB 支持在 SELECT 子句中计算由聚合函数、常量、时间序列生成函数和表达式组成的任意嵌套表达式。
说明:
- 当某个时间戳下左操作数和右操作数都不为空(
null)时,表达式才会有结果,否则表达式值为null,且默认不出现在结果集中。但在使用GROUP BY子句的聚合查询嵌套表达式中,我们希望保留每个时间窗口的值,所以表达式值为null的窗口也包含在结果集中。 - 如果表达式中某个操作数对应多条时间序列(如通配符
*),那么每条时间序列对应的结果都会出现在结果集中(按照笛卡尔积形式)。
示例 1:
select avg(temperature),
sin(avg(temperature)),
avg(temperature) + 1,
-sum(hardware),
avg(temperature) + sum(hardware)
from root.ln.wf01.wt01;
运行结果:
+----------------------------------+---------------------------------------+--------------------------------------+--------------------------------+--------------------------------------------------------------------+
|avg(root.ln.wf01.wt01.temperature)|sin(avg(root.ln.wf01.wt01.temperature))|avg(root.ln.wf01.wt01.temperature) + 1|-sum(root.ln.wf01.wt01.hardware)|avg(root.ln.wf01.wt01.temperature) + sum(root.ln.wf01.wt01.hardware)|
+----------------------------------+---------------------------------------+--------------------------------------+--------------------------------+--------------------------------------------------------------------+
| 15.927999999999999| -0.21826546964855045| 16.927999999999997| -7426.0| 7441.928|
+----------------------------------+---------------------------------------+--------------------------------------+--------------------------------+--------------------------------------------------------------------+
Total line number = 1
It costs 0.009s
示例 2:
select avg(*),
(avg(*) + 1) * 3 / 2 -1
from root.sg1
运行结果:
+---------------+---------------+-------------------------------------+-------------------------------------+
|avg(root.sg1.a)|avg(root.sg1.b)|(avg(root.sg1.a) + 1) * 3 / 2 - 1 |(avg(root.sg1.b) + 1) * 3 / 2 - 1 |
+---------------+---------------+-------------------------------------+-------------------------------------+
| 3.2| 3.4| 5.300000000000001| 5.6000000000000005|
+---------------+---------------+-------------------------------------+-------------------------------------+
Total line number = 1
It costs 0.007s
示例 3:
select avg(temperature),
sin(avg(temperature)),
avg(temperature) + 1,
-sum(hardware),
avg(temperature) + sum(hardware) as custom_sum
from root.ln.wf01.wt01
GROUP BY([10, 90), 10ms);
运行结果:
+-----------------------------+----------------------------------+---------------------------------------+--------------------------------------+--------------------------------+----------+
| Time|avg(root.ln.wf01.wt01.temperature)|sin(avg(root.ln.wf01.wt01.temperature))|avg(root.ln.wf01.wt01.temperature) + 1|-sum(root.ln.wf01.wt01.hardware)|custom_sum|
+-----------------------------+----------------------------------+---------------------------------------+--------------------------------------+--------------------------------+----------+
|1970-01-01T08:00:00.010+08:00| 13.987499999999999| 0.9888207947857667| 14.987499999999999| -3211.0| 3224.9875|
|1970-01-01T08:00:00.020+08:00| 29.6| -0.9701057337071853| 30.6| -3720.0| 3749.6|
|1970-01-01T08:00:00.030+08:00| null| null| null| null| null|
|1970-01-01T08:00:00.040+08:00| null| null| null| null| null|
|1970-01-01T08:00:00.050+08:00| null| null| null| null| null|
|1970-01-01T08:00:00.060+08:00| null| null| null| null| null|
|1970-01-01T08:00:00.070+08:00| null| null| null| null| null|
|1970-01-01T08:00:00.080+08:00| null| null| null| null| null|
+-----------------------------+----------------------------------+---------------------------------------+--------------------------------------+--------------------------------+----------+
Total line number = 8
It costs 0.012s
最新点查询
最新点查询是时序数据库 Apache IoTDB 中提供的一种特殊查询。它返回指定时间序列中时间戳最大的数据点,即一条序列的最新状态。
在物联网数据分析场景中,此功能尤为重要。为了满足了用户对设备实时监控的需求,Apache IoTDB 对最新点查询进行了缓存优化,能够提供毫秒级的返回速度。
SQL 语法:
select last <Path> [COMMA <Path>]* from < PrefixPath > [COMMA < PrefixPath >]* <whereClause> [ORDER BY TIMESERIES (DESC | ASC)?]
其含义是: 查询时间序列 prefixPath.path 中最近时间戳的数据。
whereClause中当前只支持时间过滤条件,任何其他过滤条件都将会返回异常。当缓存的最新点不满足过滤条件时,IoTDB 需要从存储中获取结果,此时性能将会有所下降。结果集为四列的结构:
+----+----------+-----+--------+ |Time|timeseries|value|dataType| +----+----------+-----+--------+可以使用
ORDER BY TIME/TIMESERIES/VALUE/DATATYPE (DESC | ASC)指定结果集按照某一列进行降序/升序排列。当值列包含多种类型的数据时,按照字符串类型来排序。
示例 1: 查询 root.ln.wf01.wt01.status 的最新数据点
IoTDB> select last status from root.ln.wf01.wt01
+-----------------------------+------------------------+-----+--------+
| Time| timeseries|value|dataType|
+-----------------------------+------------------------+-----+--------+
|2017-11-07T23:59:00.000+08:00|root.ln.wf01.wt01.status|false| BOOLEAN|
+-----------------------------+------------------------+-----+--------+
Total line number = 1
It costs 0.000s
示例 2: 查询 root.ln.wf01.wt01 下 status,temperature 时间戳大于等于 2017-11-07T23:50:00 的最新数据点。
IoTDB> select last status, temperature from root.ln.wf01.wt01 where time >= 2017-11-07T23:50:00
+-----------------------------+-----------------------------+---------+--------+
| Time| timeseries| value|dataType|
+-----------------------------+-----------------------------+---------+--------+
|2017-11-07T23:59:00.000+08:00| root.ln.wf01.wt01.status| false| BOOLEAN|
|2017-11-07T23:59:00.000+08:00|root.ln.wf01.wt01.temperature|21.067368| DOUBLE|
+-----------------------------+-----------------------------+---------+--------+
Total line number = 2
It costs 0.002s
示例 3: 查询 root.ln.wf01.wt01 下所有序列的最新数据点,并按照序列名降序排列。
IoTDB> select last * from root.ln.wf01.wt01 order by timeseries desc;
+-----------------------------+-----------------------------+---------+--------+
| Time| timeseries| value|dataType|
+-----------------------------+-----------------------------+---------+--------+
|2017-11-07T23:59:00.000+08:00|root.ln.wf01.wt01.temperature|21.067368| DOUBLE|
|2017-11-07T23:59:00.000+08:00| root.ln.wf01.wt01.status| false| BOOLEAN|
+-----------------------------+-----------------------------+---------+--------+
Total line number = 2
It costs 0.002s
示例 4: 查询 root.ln.wf01.wt01 下所有序列的最新数据点,并按照dataType降序排列。
IoTDB> select last * from root.ln.wf01.wt01 order by dataType desc;
+-----------------------------+-----------------------------+---------+--------+
| Time| timeseries| value|dataType|
+-----------------------------+-----------------------------+---------+--------+
|2017-11-07T23:59:00.000+08:00|root.ln.wf01.wt01.temperature|21.067368| DOUBLE|
|2017-11-07T23:59:00.000+08:00| root.ln.wf01.wt01.status| false| BOOLEAN|
+-----------------------------+-----------------------------+---------+--------+
Total line number = 2
It costs 0.002s
查询过滤条件(WHERE 子句)
WHERE 子句指定了对数据行的筛选条件,由一个 whereCondition 组成。
whereCondition 是一个逻辑表达式,对于要选择的每一行,其计算结果为真。如果没有 WHERE 子句,将选择所有行。
在 whereCondition 中,可以使用除聚合函数之外的任何 IOTDB 支持的函数和运算符。
根据过滤条件的不同,可以分为时间过滤条件和值过滤条件。时间过滤条件和值过滤条件可以混合使用。
时间过滤条件
使用时间过滤条件可以筛选特定时间范围的数据。对于时间戳支持的格式,请参考 时间戳类型 。
示例如下:
选择时间戳大于 2022-01-01T00:05:00.000 的数据:
select s1 from root.sg1.d1 where time > 2022-01-01T00:05:00.000;选择时间戳等于 2022-01-01T00:05:00.000 的数据:
select s1 from root.sg1.d1 where time = 2022-01-01T00:05:00.000;选择时间区间 [2017-11-01T00:05:00.000, 2017-11-01T00:12:00.000) 内的数据:
select s1 from root.sg1.d1 where time >= 2022-01-01T00:05:00.000 and time < 2017-11-01T00:12:00.000;
注:在上述示例中,time 也可写做 timestamp。
值过滤条件
使用值过滤条件可以筛选数据值满足特定条件的数据。
允许使用 select 子句中未选择的时间序列作为值过滤条件。
示例如下:
选择值大于 36.5 的数据:
select temperature from root.sg1.d1 where temperature > 36.5;选择值等于 true 的数据:
select status from root.sg1.d1 where status = true;选择区间 [36.5,40] 内或之外的数据:
select temperature from root.sg1.d1 where temperature between 36.5 and 40;select temperature from root.sg1.d1 where temperature not between 36.5 and 40;选择值在特定范围内的数据:
select code from root.sg1.d1 where code in ('200', '300', '400', '500');选择值在特定范围外的数据:
select code from root.sg1.d1 where code not in ('200', '300', '400', '500');选择值为空的数据:
select code from root.sg1.d1 where temperature is null;选择值为非空的数据:
select code from root.sg1.d1 where temperature is not null;
模糊查询
对于 TEXT 类型的数据,支持使用 Like 和 Regexp 运算符对数据进行模糊匹配
使用 Like 进行模糊匹配
匹配规则:
%表示任意0个或多个字符。_表示任意单个字符。
示例 1: 查询 root.sg.d1 下 value 含有'cc'的数据。
IoTDB> select * from root.sg.d1 where value like '%cc%'
+-----------------------------+----------------+
| Time|root.sg.d1.value|
+-----------------------------+----------------+
|2017-11-01T00:00:00.000+08:00| aabbccdd|
|2017-11-01T00:00:01.000+08:00| cc|
+-----------------------------+----------------+
Total line number = 2
It costs 0.002s
示例 2: 查询 root.sg.d1 下 value 中间为 'b'、前后为任意单个字符的数据。
IoTDB> select * from root.sg.device where value like '_b_'
+-----------------------------+----------------+
| Time|root.sg.d1.value|
+-----------------------------+----------------+
|2017-11-01T00:00:02.000+08:00| abc|
+-----------------------------+----------------+
Total line number = 1
It costs 0.002s
使用 Regexp 进行模糊匹配
需要传入的过滤条件为 Java 标准库风格的正则表达式。
常见的正则匹配举例:
长度为3-20的所有字符:^.{3,20}$
大写英文字符:^[A-Z]+$
数字和英文字符:^[A-Za-z0-9]+$
以a开头的:^a.*
示例 1: 查询 root.sg.d1 下 value 值为26个英文字符组成的字符串。
IoTDB> select * from root.sg.d1 where value regexp '^[A-Za-z]+$'
+-----------------------------+----------------+
| Time|root.sg.d1.value|
+-----------------------------+----------------+
|2017-11-01T00:00:00.000+08:00| aabbccdd|
|2017-11-01T00:00:01.000+08:00| cc|
+-----------------------------+----------------+
Total line number = 2
It costs 0.002s
示例 2: 查询 root.sg.d1 下 value 值为26个小写英文字符组成的字符串且时间大于100的。
IoTDB> select * from root.sg.d1 where value regexp '^[a-z]+$' and time > 100
+-----------------------------+----------------+
| Time|root.sg.d1.value|
+-----------------------------+----------------+
|2017-11-01T00:00:00.000+08:00| aabbccdd|
|2017-11-01T00:00:01.000+08:00| cc|
+-----------------------------+----------------+
Total line number = 2
It costs 0.002s
分段分组聚合(GROUP BY 子句)
IoTDB支持通过GROUP BY子句对序列进行分段或者分组聚合。
分段聚合是指按照时间维度,针对同时间序列中不同数据点之间的时间关系,对数据在行的方向进行分段,每个段得到一个聚合值。目前支持时间区间分段、差值分段、条件分段、会话分段和点数分段,未来将支持更多分段方式。
分组聚合是指针对不同时间序列,在时间序列的潜在业务属性上分组,每个组包含若干条时间序列,每个组得到一个聚合值。支持按路径层级分组和按序列标签分组两种分组方式。
分段聚合
时间区间分段聚合
时间区间分段聚合是一种时序数据典型的查询方式,数据以高频进行采集,需要按照一定的时间间隔进行聚合计算,如计算每天的平均气温,需要将气温的序列按天进行分段,然后计算平均值。
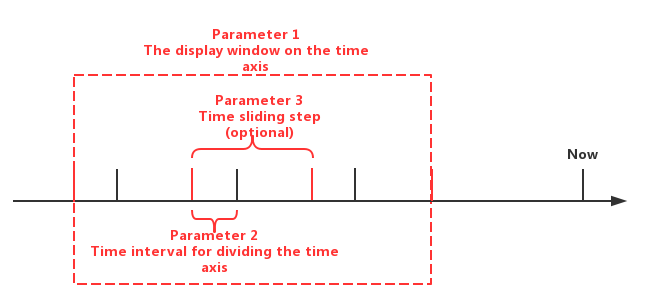
在 IoTDB 中,聚合查询可以通过 GROUP BY 子句指定按照时间区间分段聚合。用户可以指定聚合的时间间隔和滑动步长,相关参数如下:
- 参数 1:时间轴显示时间窗口大小
- 参数 2:聚合窗口的大小(必须为正数)
- 参数 3:聚合窗口的滑动步长(可选,默认与聚合窗口大小相同)
下图中指出了这三个参数的含义:
接下来,我们给出几个典型例子:
未指定滑动步长的时间区间分段聚合查询
对应的 SQL 语句是:
select count(status), max_value(temperature) from root.ln.wf01.wt01 group by ([2017-11-01T00:00:00, 2017-11-07T23:00:00),1d);
这条查询的含义是:
由于用户没有指定滑动步长,滑动步长将会被默认设置为跟时间间隔参数相同,也就是1d。
上面这个例子的第一个参数是显示窗口参数,决定了最终的显示范围是 [2017-11-01T00:00:00, 2017-11-07T23:00:00)。
上面这个例子的第二个参数是划分时间轴的时间间隔参数,将1d当作划分间隔,显示窗口参数的起始时间当作分割原点,时间轴即被划分为连续的时间间隔:[0,1d), [1d, 2d), [2d, 3d) 等等。
然后系统将会用 WHERE 子句中的时间和值过滤条件以及 GROUP BY 语句中的第一个参数作为数据的联合过滤条件,获得满足所有过滤条件的数据(在这个例子里是在 [2017-11-01T00:00:00, 2017-11-07 T23:00:00) 这个时间范围的数据),并把这些数据映射到之前分割好的时间轴中(这个例子里是从 2017-11-01T00:00:00 到 2017-11-07T23:00:00:00 的每一天)
每个时间间隔窗口内都有数据,SQL 执行后的结果集如下所示:
+-----------------------------+-------------------------------+----------------------------------------+
| Time|count(root.ln.wf01.wt01.status)|max_value(root.ln.wf01.wt01.temperature)|
+-----------------------------+-------------------------------+----------------------------------------+
|2017-11-01T00:00:00.000+08:00| 1440| 26.0|
|2017-11-02T00:00:00.000+08:00| 1440| 26.0|
|2017-11-03T00:00:00.000+08:00| 1440| 25.99|
|2017-11-04T00:00:00.000+08:00| 1440| 26.0|
|2017-11-05T00:00:00.000+08:00| 1440| 26.0|
|2017-11-06T00:00:00.000+08:00| 1440| 25.99|
|2017-11-07T00:00:00.000+08:00| 1380| 26.0|
+-----------------------------+-------------------------------+----------------------------------------+
Total line number = 7
It costs 0.024s
指定滑动步长的时间区间分段聚合查询
对应的 SQL 语句是:
select count(status), max_value(temperature) from root.ln.wf01.wt01 group by ([2017-11-01 00:00:00, 2017-11-07 23:00:00), 3h, 1d);
这条查询的含义是:
由于用户指定了滑动步长为1d,GROUP BY 语句执行时将会每次把时间间隔往后移动一天的步长,而不是默认的 3 小时。
也就意味着,我们想要取从 2017-11-01 到 2017-11-07 每一天的凌晨 0 点到凌晨 3 点的数据。
上面这个例子的第一个参数是显示窗口参数,决定了最终的显示范围是 [2017-11-01T00:00:00, 2017-11-07T23:00:00)。
上面这个例子的第二个参数是划分时间轴的时间间隔参数,将3h当作划分间隔,显示窗口参数的起始时间当作分割原点,时间轴即被划分为连续的时间间隔:[2017-11-01T00:00:00, 2017-11-01T03:00:00), [2017-11-02T00:00:00, 2017-11-02T03:00:00), [2017-11-03T00:00:00, 2017-11-03T03:00:00) 等等。
上面这个例子的第三个参数是每次时间间隔的滑动步长。
然后系统将会用 WHERE 子句中的时间和值过滤条件以及 GROUP BY 语句中的第一个参数作为数据的联合过滤条件,获得满足所有过滤条件的数据(在这个例子里是在 [2017-11-01T00:00:00, 2017-11-07 T23:00:00) 这个时间范围的数据),并把这些数据映射到之前分割好的时间轴中(这个例子里是从 2017-11-01T00:00:00 到 2017-11-07T23:00:00:00 的每一天的凌晨 0 点到凌晨 3 点)
每个时间间隔窗口内都有数据,SQL 执行后的结果集如下所示:
+-----------------------------+-------------------------------+----------------------------------------+
| Time|count(root.ln.wf01.wt01.status)|max_value(root.ln.wf01.wt01.temperature)|
+-----------------------------+-------------------------------+----------------------------------------+
|2017-11-01T00:00:00.000+08:00| 180| 25.98|
|2017-11-02T00:00:00.000+08:00| 180| 25.98|
|2017-11-03T00:00:00.000+08:00| 180| 25.96|
|2017-11-04T00:00:00.000+08:00| 180| 25.96|
|2017-11-05T00:00:00.000+08:00| 180| 26.0|
|2017-11-06T00:00:00.000+08:00| 180| 25.85|
|2017-11-07T00:00:00.000+08:00| 180| 25.99|
+-----------------------------+-------------------------------+----------------------------------------+
Total line number = 7
It costs 0.006s
滑动步长可以小于聚合窗口,此时聚合窗口之间有重叠时间(类似于一个滑动窗口)。
例如 SQL:
select count(status), max_value(temperature) from root.ln.wf01.wt01 group by ([2017-11-01 00:00:00, 2017-11-01 10:00:00), 4h, 2h);
SQL 执行后的结果集如下所示:
+-----------------------------+-------------------------------+----------------------------------------+
| Time|count(root.ln.wf01.wt01.status)|max_value(root.ln.wf01.wt01.temperature)|
+-----------------------------+-------------------------------+----------------------------------------+
|2017-11-01T00:00:00.000+08:00| 180| 25.98|
|2017-11-01T02:00:00.000+08:00| 180| 25.98|
|2017-11-01T04:00:00.000+08:00| 180| 25.96|
|2017-11-01T06:00:00.000+08:00| 180| 25.96|
|2017-11-01T08:00:00.000+08:00| 180| 26.0|
+-----------------------------+-------------------------------+----------------------------------------+
Total line number = 5
It costs 0.006s
按照自然月份的时间区间分段聚合查询
对应的 SQL 语句是:
select count(status) from root.ln.wf01.wt01 where time > 2017-11-01T01:00:00 group by([2017-11-01T00:00:00, 2019-11-07T23:00:00), 1mo, 2mo);
这条查询的含义是:
由于用户指定了滑动步长为2mo,GROUP BY 语句执行时将会每次把时间间隔往后移动 2 个自然月的步长,而不是默认的 1 个自然月。
也就意味着,我们想要取从 2017-11-01 到 2019-11-07 每 2 个自然月的第一个月的数据。
上面这个例子的第一个参数是显示窗口参数,决定了最终的显示范围是 [2017-11-01T00:00:00, 2019-11-07T23:00:00)。
起始时间为 2017-11-01T00:00:00,滑动步长将会以起始时间作为标准按月递增,取当月的 1 号作为时间间隔的起始时间。
上面这个例子的第二个参数是划分时间轴的时间间隔参数,将1mo当作划分间隔,显示窗口参数的起始时间当作分割原点,时间轴即被划分为连续的时间间隔:[2017-11-01T00:00:00, 2017-12-01T00:00:00), [2018-02-01T00:00:00, 2018-03-01T00:00:00), [2018-05-03T00:00:00, 2018-06-01T00:00:00) 等等。
上面这个例子的第三个参数是每次时间间隔的滑动步长。
然后系统将会用 WHERE 子句中的时间和值过滤条件以及 GROUP BY 语句中的第一个参数作为数据的联合过滤条件,获得满足所有过滤条件的数据(在这个例子里是在 [2017-11-01T00:00:00, 2019-11-07T23:00:00) 这个时间范围的数据),并把这些数据映射到之前分割好的时间轴中(这个例子里是从 2017-11-01T00:00:00 到 2019-11-07T23:00:00:00 的每两个自然月的第一个月)
每个时间间隔窗口内都有数据,SQL 执行后的结果集如下所示:
+-----------------------------+-------------------------------+
| Time|count(root.ln.wf01.wt01.status)|
+-----------------------------+-------------------------------+
|2017-11-01T00:00:00.000+08:00| 259|
|2018-01-01T00:00:00.000+08:00| 250|
|2018-03-01T00:00:00.000+08:00| 259|
|2018-05-01T00:00:00.000+08:00| 251|
|2018-07-01T00:00:00.000+08:00| 242|
|2018-09-01T00:00:00.000+08:00| 225|
|2018-11-01T00:00:00.000+08:00| 216|
|2019-01-01T00:00:00.000+08:00| 207|
|2019-03-01T00:00:00.000+08:00| 216|
|2019-05-01T00:00:00.000+08:00| 207|
|2019-07-01T00:00:00.000+08:00| 199|
|2019-09-01T00:00:00.000+08:00| 181|
|2019-11-01T00:00:00.000+08:00| 60|
+-----------------------------+-------------------------------+
对应的 SQL 语句是:
select count(status) from root.ln.wf01.wt01 group by([2017-10-31T00:00:00, 2019-11-07T23:00:00), 1mo, 2mo);
这条查询的含义是:
由于用户指定了滑动步长为2mo,GROUP BY 语句执行时将会每次把时间间隔往后移动 2 个自然月的步长,而不是默认的 1 个自然月。
也就意味着,我们想要取从 2017-10-31 到 2019-11-07 每 2 个自然月的第一个月的数据。
与上述示例不同的是起始时间为 2017-10-31T00:00:00,滑动步长将会以起始时间作为标准按月递增,取当月的 31 号(即最后一天)作为时间间隔的起始时间。若起始时间设置为 30 号,滑动步长会将时间间隔的起始时间设置为当月 30 号,若不存在则为最后一天。
上面这个例子的第一个参数是显示窗口参数,决定了最终的显示范围是 [2017-10-31T00:00:00, 2019-11-07T23:00:00)。
上面这个例子的第二个参数是划分时间轴的时间间隔参数,将1mo当作划分间隔,显示窗口参数的起始时间当作分割原点,时间轴即被划分为连续的时间间隔:[2017-10-31T00:00:00, 2017-11-31T00:00:00), [2018-02-31T00:00:00, 2018-03-31T00:00:00), [2018-05-31T00:00:00, 2018-06-31T00:00:00) 等等。
上面这个例子的第三个参数是每次时间间隔的滑动步长。
然后系统将会用 WHERE 子句中的时间和值过滤条件以及 GROUP BY 语句中的第一个参数作为数据的联合过滤条件,获得满足所有过滤条件的数据(在这个例子里是在 [2017-10-31T00:00:00, 2019-11-07T23:00:00) 这个时间范围的数据),并把这些数据映射到之前分割好的时间轴中(这个例子里是从 2017-10-31T00:00:00 到 2019-11-07T23:00:00:00 的每两个自然月的第一个月)
每个时间间隔窗口内都有数据,SQL 执行后的结果集如下所示:
+-----------------------------+-------------------------------+
| Time|count(root.ln.wf01.wt01.status)|
+-----------------------------+-------------------------------+
|2017-10-31T00:00:00.000+08:00| 251|
|2017-12-31T00:00:00.000+08:00| 250|
|2018-02-28T00:00:00.000+08:00| 259|
|2018-04-30T00:00:00.000+08:00| 250|
|2018-06-30T00:00:00.000+08:00| 242|
|2018-08-31T00:00:00.000+08:00| 225|
|2018-10-31T00:00:00.000+08:00| 216|
|2018-12-31T00:00:00.000+08:00| 208|
|2019-02-28T00:00:00.000+08:00| 216|
|2019-04-30T00:00:00.000+08:00| 208|
|2019-06-30T00:00:00.000+08:00| 199|
|2019-08-31T00:00:00.000+08:00| 181|
|2019-10-31T00:00:00.000+08:00| 69|
+-----------------------------+-------------------------------+
左开右闭区间
每个区间的结果时间戳为区间右端点,对应的 SQL 语句是:
select count(status) from root.ln.wf01.wt01 group by ((2017-11-01T00:00:00, 2017-11-07T23:00:00],1d);
这条查询语句的时间区间是左开右闭的,结果中不会包含时间点 2017-11-01 的数据,但是会包含时间点 2017-11-07 的数据。
SQL 执行后的结果集如下所示:
+-----------------------------+-------------------------------+
| Time|count(root.ln.wf01.wt01.status)|
+-----------------------------+-------------------------------+
|2017-11-02T00:00:00.000+08:00| 1440|
|2017-11-03T00:00:00.000+08:00| 1440|
|2017-11-04T00:00:00.000+08:00| 1440|
|2017-11-05T00:00:00.000+08:00| 1440|
|2017-11-06T00:00:00.000+08:00| 1440|
|2017-11-07T00:00:00.000+08:00| 1440|
|2017-11-07T23:00:00.000+08:00| 1380|
+-----------------------------+-------------------------------+
Total line number = 7
It costs 0.004s
差值分段聚合
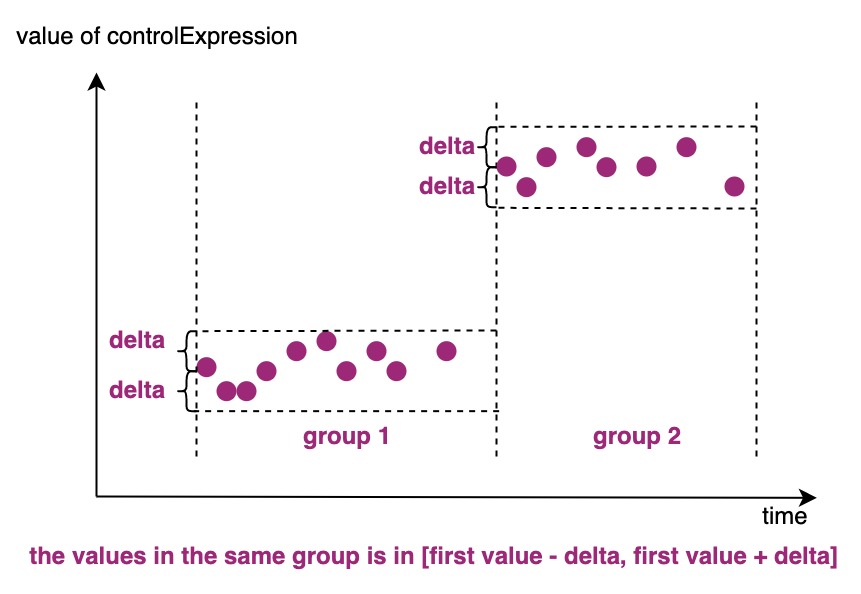
IoTDB支持通过GROUP BY VARIATION语句来根据差值进行分组。GROUP BY VARIATION会将第一个点作为一个组的基准点,每个新的数据在按照给定规则与基准点进行差值运算后,
如果差值小于给定的阈值则将该新点归于同一组,否则结束当前分组,以这个新的数据为新的基准点开启新的分组。
该分组方式不会重叠,且没有固定的开始结束时间。其子句语法如下:
group by variation(controlExpression[,delta][,ignoreNull=true/false])
不同的参数含义如下
- controlExpression
分组所参照的值,可以是查询数据中的某一列或是多列的表达式
(多列表达式计算后仍为一个值,使用多列表达式时指定的列必须都为数值列), 差值便是根据数据的controlExpression的差值运算。
- delta
分组所使用的阈值,同一分组中每个点的controlExpression对应的值与该组中基准点对应值的差值都小于delta。当delta=0时,相当于一个等值分组,所有连续且expression值相同的数据将被分到一组。
- ignoreNull
用于指定controlExpression的值为null时对数据的处理方式,当ignoreNull为false时,该null值会被视为新的值,ignoreNull为true时,则直接跳过对应的点。
在delta取不同值时,controlExpression支持的返回数据类型以及当ignoreNull为false时对于null值的处理方式可以见下表:
| delta | controlExpression支持的返回类型 | ignoreNull=false时对于Null值的处理 |
|---|---|---|
| delta!=0 | INT32、INT64、FLOAT、DOUBLE | 若正在维护分组的值不为null,null视为无穷大/无穷小,结束当前分组。连续的null视为差值相等的值,会被分配在同一个分组 |
| delta=0 | TEXT、BINARY、INT32、INT64、FLOAT、DOUBLE | null被视为新分组中的新值,连续的null属于相同的分组 |
下图为差值分段的一个分段方式示意图,与组中第一个数据的控制列值的差值在delta内的控制列对应的点属于相同的分组。
使用注意事项
controlExpression的结果应该为唯一值,如果使用通配符拼接后出现多列,则报错。- 对于一个分组,默认Time列输出分组的开始时间,查询时可以使用select
__endTime的方式来使得结果输出分组的结束时间。 - 与
ALIGN BY DEVICE搭配使用时会对每个device进行单独的分组操作。 - 当没有指定
delta和ignoreNull时,delta默认为0,ignoreNull默认为true。 - 当前暂不支持与
GROUP BY LEVEL搭配使用。
使用如下的原始数据,接下来会给出几个事件分段查询的使用样例
+-----------------------------+-------+-------+-------+--------+-------+-------+
| Time| s1| s2| s3| s4| s5| s6|
+-----------------------------+-------+-------+-------+--------+-------+-------+
|1970-01-01T08:00:00.000+08:00| 4.5| 9.0| 0.0| 45.0| 9.0| 8.25|
|1970-01-01T08:00:00.010+08:00| null| 19.0| 10.0| 145.0| 19.0| 8.25|
|1970-01-01T08:00:00.020+08:00| 24.5| 29.0| null| 245.0| 29.0| null|
|1970-01-01T08:00:00.030+08:00| 34.5| null| 30.0| 345.0| null| null|
|1970-01-01T08:00:00.040+08:00| 44.5| 49.0| 40.0| 445.0| 49.0| 8.25|
|1970-01-01T08:00:00.050+08:00| null| 59.0| 50.0| 545.0| 59.0| 6.25|
|1970-01-01T08:00:00.060+08:00| 64.5| 69.0| 60.0| 645.0| 69.0| null|
|1970-01-01T08:00:00.070+08:00| 74.5| 79.0| null| null| 79.0| 3.25|
|1970-01-01T08:00:00.080+08:00| 84.5| 89.0| 80.0| 845.0| 89.0| 3.25|
|1970-01-01T08:00:00.090+08:00| 94.5| 99.0| 90.0| 945.0| 99.0| 3.25|
|1970-01-01T08:00:00.150+08:00| 66.5| 77.0| 90.0| 945.0| 99.0| 9.25|
+-----------------------------+-------+-------+-------+--------+-------+-------+
delta=0时的等值事件分段
使用如下sql语句
select __endTime, avg(s1), count(s2), sum(s3) from root.sg.d group by variation(s6)
得到如下的查询结果,这里忽略了s6为null的行
+-----------------------------+-----------------------------+-----------------+-------------------+-----------------+
| Time| __endTime|avg(root.sg.d.s1)|count(root.sg.d.s2)|sum(root.sg.d.s3)|
+-----------------------------+-----------------------------+-----------------+-------------------+-----------------+
|1970-01-01T08:00:00.000+08:00|1970-01-01T08:00:00.040+08:00| 24.5| 3| 50.0|
|1970-01-01T08:00:00.050+08:00|1970-01-01T08:00:00.050+08:00| null| 1| 50.0|
|1970-01-01T08:00:00.070+08:00|1970-01-01T08:00:00.090+08:00| 84.5| 3| 170.0|
|1970-01-01T08:00:00.150+08:00|1970-01-01T08:00:00.150+08:00| 66.5| 1| 90.0|
+-----------------------------+-----------------------------+-----------------+-------------------+-----------------+
当指定ignoreNull为false时,会将s6为null的数据也考虑进来
select __endTime, avg(s1), count(s2), sum(s3) from root.sg.d group by variation(s6, ignoreNull=false)
得到如下的结果
+-----------------------------+-----------------------------+-----------------+-------------------+-----------------+
| Time| __endTime|avg(root.sg.d.s1)|count(root.sg.d.s2)|sum(root.sg.d.s3)|
+-----------------------------+-----------------------------+-----------------+-------------------+-----------------+
|1970-01-01T08:00:00.000+08:00|1970-01-01T08:00:00.010+08:00| 4.5| 2| 10.0|
|1970-01-01T08:00:00.020+08:00|1970-01-01T08:00:00.030+08:00| 29.5| 1| 30.0|
|1970-01-01T08:00:00.040+08:00|1970-01-01T08:00:00.040+08:00| 44.5| 1| 40.0|
|1970-01-01T08:00:00.050+08:00|1970-01-01T08:00:00.050+08:00| null| 1| 50.0|
|1970-01-01T08:00:00.060+08:00|1970-01-01T08:00:00.060+08:00| 64.5| 1| 60.0|
|1970-01-01T08:00:00.070+08:00|1970-01-01T08:00:00.090+08:00| 84.5| 3| 170.0|
|1970-01-01T08:00:00.150+08:00|1970-01-01T08:00:00.150+08:00| 66.5| 1| 90.0|
+-----------------------------+-----------------------------+-----------------+-------------------+-----------------+
delta!=0时的差值事件分段
使用如下sql语句
select __endTime, avg(s1), count(s2), sum(s3) from root.sg.d group by variation(s6, 4)
得到如下的查询结果
+-----------------------------+-----------------------------+-----------------+-------------------+-----------------+
| Time| __endTime|avg(root.sg.d.s1)|count(root.sg.d.s2)|sum(root.sg.d.s3)|
+-----------------------------+-----------------------------+-----------------+-------------------+-----------------+
|1970-01-01T08:00:00.000+08:00|1970-01-01T08:00:00.050+08:00| 24.5| 4| 100.0|
|1970-01-01T08:00:00.070+08:00|1970-01-01T08:00:00.090+08:00| 84.5| 3| 170.0|
|1970-01-01T08:00:00.150+08:00|1970-01-01T08:00:00.150+08:00| 66.5| 1| 90.0|
+-----------------------------+-----------------------------+-----------------+-------------------+-----------------+
group by子句中的controlExpression同样支持列的表达式
select __endTime, avg(s1), count(s2), sum(s3) from root.sg.d group by variation(s6+s5, 10)
得到如下的查询结果
+-----------------------------+-----------------------------+-----------------+-------------------+-----------------+
| Time| __endTime|avg(root.sg.d.s1)|count(root.sg.d.s2)|sum(root.sg.d.s3)|
+-----------------------------+-----------------------------+-----------------+-------------------+-----------------+
|1970-01-01T08:00:00.000+08:00|1970-01-01T08:00:00.010+08:00| 4.5| 2| 10.0|
|1970-01-01T08:00:00.040+08:00|1970-01-01T08:00:00.050+08:00| 44.5| 2| 90.0|
|1970-01-01T08:00:00.070+08:00|1970-01-01T08:00:00.080+08:00| 79.5| 2| 80.0|
|1970-01-01T08:00:00.090+08:00|1970-01-01T08:00:00.150+08:00| 80.5| 2| 180.0|
+-----------------------------+-----------------------------+-----------------+-------------------+-----------------+
条件分段聚合
当需要根据指定条件对数据进行筛选,并将连续的符合条件的行分为一组进行聚合运算时,可以使用GROUP BY CONDITION的分段方式;不满足给定条件的行因为不属于任何分组会被直接简单忽略。
其语法定义如下:
group by condition(predict,[keep>/>=/=/<=/<]threshold,[,ignoreNull=true/false])
- predict
返回boolean数据类型的合法表达式,用于分组的筛选。
- keep[>/>=/=/<=/<]threshold
keep表达式用来指定形成分组所需要连续满足predict条件的数据行数,只有行数满足keep表达式的分组才会被输出。keep表达式由一个'keep'字符串和long类型的threshold组合或者是单独的long类型数据构成。
- ignoreNull=true/false
用于指定遇到predict为null的数据行时的处理方式,为true则跳过该行,为false则结束当前分组。
使用注意事项
- keep条件在查询中是必需的,但可以省略掉keep字符串给出一个
long类型常数,默认为keep=该long型常数的等于条件。 ignoreNull默认为true。- 对于一个分组,默认Time列输出分组的开始时间,查询时可以使用select
__endTime的方式来使得结果输出分组的结束时间。 - 与
ALIGN BY DEVICE搭配使用时会对每个device进行单独的分组操作。 - 当前暂不支持与
GROUP BY LEVEL搭配使用。
对于如下原始数据,下面会给出几个查询样例:
+-----------------------------+-------------------------+-------------------------------------+------------------------------------+
| Time|root.sg.beijing.car01.soc|root.sg.beijing.car01.charging_status|root.sg.beijing.car01.vehicle_status|
+-----------------------------+-------------------------+-------------------------------------+------------------------------------+
|1970-01-01T08:00:00.001+08:00| 14.0| 1| 1|
|1970-01-01T08:00:00.002+08:00| 16.0| 1| 1|
|1970-01-01T08:00:00.003+08:00| 16.0| 0| 1|
|1970-01-01T08:00:00.004+08:00| 16.0| 0| 1|
|1970-01-01T08:00:00.005+08:00| 18.0| 1| 1|
|1970-01-01T08:00:00.006+08:00| 24.0| 1| 1|
|1970-01-01T08:00:00.007+08:00| 36.0| 1| 1|
|1970-01-01T08:00:00.008+08:00| 36.0| null| 1|
|1970-01-01T08:00:00.009+08:00| 45.0| 1| 1|
|1970-01-01T08:00:00.010+08:00| 60.0| 1| 1|
+-----------------------------+-------------------------+-------------------------------------+------------------------------------+
查询至少连续两行以上的charging_status=1的数据,sql语句如下:
select max_time(charging_status),count(vehicle_status),last_value(soc) from root.** group by condition(charging_status=1,KEEP>=2,ignoreNull=true)
得到结果如下:
+-----------------------------+-----------------------------------------------+-------------------------------------------+-------------------------------------+
| Time|max_time(root.sg.beijing.car01.charging_status)|count(root.sg.beijing.car01.vehicle_status)|last_value(root.sg.beijing.car01.soc)|
+-----------------------------+-----------------------------------------------+-------------------------------------------+-------------------------------------+
|1970-01-01T08:00:00.001+08:00| 2| 2| 16.0|
|1970-01-01T08:00:00.005+08:00| 10| 5| 60.0|
+-----------------------------+-----------------------------------------------+-------------------------------------------+-------------------------------------+
当设置ignoreNull为false时,遇到null值为将其视为一个不满足条件的行,会结束正在计算的分组。
select max_time(charging_status),count(vehicle_status),last_value(soc) from root.** group by condition(charging_status=1,KEEP>=2,ignoreNull=false)
得到如下结果,原先的分组被含null的行拆分:
+-----------------------------+-----------------------------------------------+-------------------------------------------+-------------------------------------+
| Time|max_time(root.sg.beijing.car01.charging_status)|count(root.sg.beijing.car01.vehicle_status)|last_value(root.sg.beijing.car01.soc)|
+-----------------------------+-----------------------------------------------+-------------------------------------------+-------------------------------------+
|1970-01-01T08:00:00.001+08:00| 2| 2| 16.0|
|1970-01-01T08:00:00.005+08:00| 7| 3| 36.0|
|1970-01-01T08:00:00.009+08:00| 10| 2| 60.0|
+-----------------------------+-----------------------------------------------+-------------------------------------------+-------------------------------------+
会话分段聚合
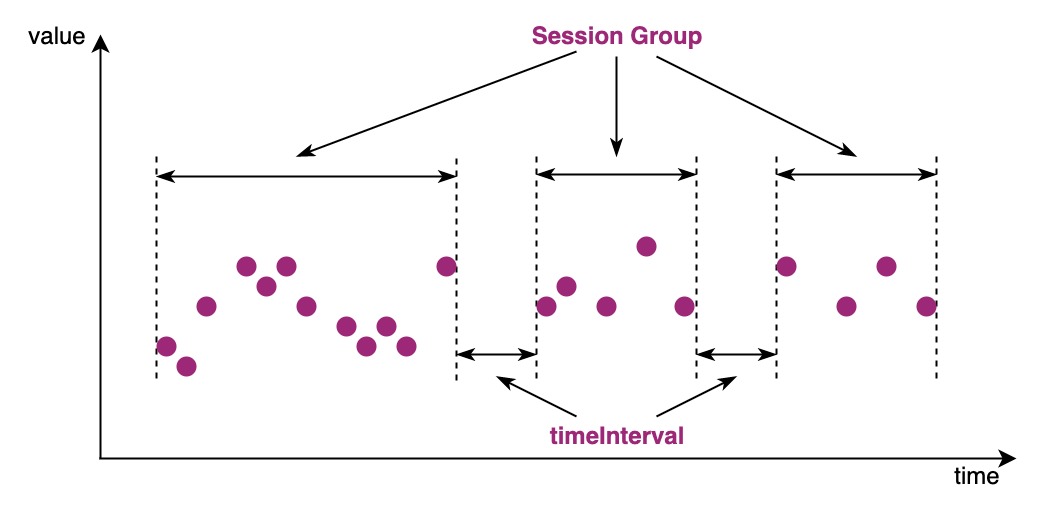
GROUP BY SESSION可以根据时间列的间隔进行分组,在结果集的时间列中,时间间隔小于等于设定阈值的数据会被分为一组。例如在工业场景中,设备并不总是连续运行,GROUP BY SESSION会将设备每次接入会话所产生的数据分为一组。
其语法定义如下:
group by session(timeInterval)
- timeInterval
设定的时间差阈值,当两条数据时间列的差值大于该阈值,则会给数据创建一个新的分组。
下图为group by session下的一个分组示意图
使用注意事项
- 对于一个分组,默认Time列输出分组的开始时间,查询时可以使用select
__endTime的方式来使得结果输出分组的结束时间。 - 与
ALIGN BY DEVICE搭配使用时会对每个device进行单独的分组操作。 - 当前暂不支持与
GROUP BY LEVEL搭配使用。
对于下面的原始数据,给出几个查询样例。
+-----------------------------+-----------------+-----------+--------+------+
| Time| Device|temperature|hardware|status|
+-----------------------------+-----------------+-----------+--------+------+
|1970-01-01T08:00:01.000+08:00|root.ln.wf02.wt01| 35.7| 11| false|
|1970-01-01T08:00:02.000+08:00|root.ln.wf02.wt01| 35.8| 22| true|
|1970-01-01T08:00:03.000+08:00|root.ln.wf02.wt01| 35.4| 33| false|
|1970-01-01T08:00:04.000+08:00|root.ln.wf02.wt01| 36.4| 44| false|
|1970-01-01T08:00:05.000+08:00|root.ln.wf02.wt01| 36.8| 55| false|
|1970-01-01T08:00:10.000+08:00|root.ln.wf02.wt01| 36.8| 110| false|
|1970-01-01T08:00:20.000+08:00|root.ln.wf02.wt01| 37.8| 220| true|
|1970-01-01T08:00:30.000+08:00|root.ln.wf02.wt01| 37.5| 330| false|
|1970-01-01T08:00:40.000+08:00|root.ln.wf02.wt01| 37.4| 440| false|
|1970-01-01T08:00:50.000+08:00|root.ln.wf02.wt01| 37.9| 550| false|
|1970-01-01T08:01:40.000+08:00|root.ln.wf02.wt01| 38.0| 110| false|
|1970-01-01T08:02:30.000+08:00|root.ln.wf02.wt01| 38.8| 220| true|
|1970-01-01T08:03:20.000+08:00|root.ln.wf02.wt01| 38.6| 330| false|
|1970-01-01T08:04:20.000+08:00|root.ln.wf02.wt01| 38.4| 440| false|
|1970-01-01T08:05:20.000+08:00|root.ln.wf02.wt01| 38.3| 550| false|
|1970-01-01T08:06:40.000+08:00|root.ln.wf02.wt01| null| 0| null|
|1970-01-01T08:07:50.000+08:00|root.ln.wf02.wt01| null| 0| null|
|1970-01-01T08:08:00.000+08:00|root.ln.wf02.wt01| null| 0| null|
|1970-01-02T08:08:01.000+08:00|root.ln.wf02.wt01| 38.2| 110| false|
|1970-01-02T08:08:02.000+08:00|root.ln.wf02.wt01| 37.5| 220| true|
|1970-01-02T08:08:03.000+08:00|root.ln.wf02.wt01| 37.4| 330| false|
|1970-01-02T08:08:04.000+08:00|root.ln.wf02.wt01| 36.8| 440| false|
|1970-01-02T08:08:05.000+08:00|root.ln.wf02.wt01| 37.4| 550| false|
+-----------------------------+-----------------+-----------+--------+------+
可以按照不同的时间单位设定时间间隔,sql语句如下:
select __endTime,count(*) from root.** group by session(1d)
得到如下结果:
+-----------------------------+-----------------------------+------------------------------------+---------------------------------+-------------------------------+
| Time| __endTime|count(root.ln.wf02.wt01.temperature)|count(root.ln.wf02.wt01.hardware)|count(root.ln.wf02.wt01.status)|
+-----------------------------+-----------------------------+------------------------------------+---------------------------------+-------------------------------+
|1970-01-01T08:00:01.000+08:00|1970-01-01T08:08:00.000+08:00| 15| 18| 15|
|1970-01-02T08:08:01.000+08:00|1970-01-02T08:08:05.000+08:00| 5| 5| 5|
+-----------------------------+-----------------------------+------------------------------------+---------------------------------+-------------------------------+
也可以和HAVING、ALIGN BY DEVICE共同使用
select __endTime,sum(hardware) from root.ln.wf02.wt01 group by session(50s) having sum(hardware)>0 align by device
得到如下结果,其中排除了sum(hardware)为0的部分
+-----------------------------+-----------------+-----------------------------+-------------+
| Time| Device| __endTime|sum(hardware)|
+-----------------------------+-----------------+-----------------------------+-------------+
|1970-01-01T08:00:01.000+08:00|root.ln.wf02.wt01|1970-01-01T08:03:20.000+08:00| 2475.0|
|1970-01-01T08:04:20.000+08:00|root.ln.wf02.wt01|1970-01-01T08:04:20.000+08:00| 440.0|
|1970-01-01T08:05:20.000+08:00|root.ln.wf02.wt01|1970-01-01T08:05:20.000+08:00| 550.0|
|1970-01-02T08:08:01.000+08:00|root.ln.wf02.wt01|1970-01-02T08:08:05.000+08:00| 1650.0|
+-----------------------------+-----------------+-----------------------------+-------------+
点数分段聚合
GROUP BY COUNT可以根据点数分组进行聚合运算,将连续的指定数量数据点分为一组,即按照固定的点数进行分组。
其语法定义如下:
group by count(controlExpression, size[,ignoreNull=true/false])
- controlExpression
计数参照的对象,可以是结果集的任意列或是列的表达式
- size
一个组中数据点的数量,每size个数据点会被分到同一个组
- ignoreNull=true/false
是否忽略controlExpression为null的数据点,当ignoreNull为true时,在计数时会跳过controlExpression结果为null的数据点
使用注意事项
- 对于一个分组,默认Time列输出分组的开始时间,查询时可以使用select
__endTime的方式来使得结果输出分组的结束时间。 - 与
ALIGN BY DEVICE搭配使用时会对每个device进行单独的分组操作。 - 当前暂不支持与
GROUP BY LEVEL搭配使用。 - 当一个分组内最终的点数不满足
size的数量时,不会输出该分组的结果
对于下面的原始数据,给出几个查询样例。
+-----------------------------+-----------+-----------------------+
| Time|root.sg.soc|root.sg.charging_status|
+-----------------------------+-----------+-----------------------+
|1970-01-01T08:00:00.001+08:00| 14.0| 1|
|1970-01-01T08:00:00.002+08:00| 16.0| 1|
|1970-01-01T08:00:00.003+08:00| 16.0| 0|
|1970-01-01T08:00:00.004+08:00| 16.0| 0|
|1970-01-01T08:00:00.005+08:00| 18.0| 1|
|1970-01-01T08:00:00.006+08:00| 24.0| 1|
|1970-01-01T08:00:00.007+08:00| 36.0| 1|
|1970-01-01T08:00:00.008+08:00| 36.0| null|
|1970-01-01T08:00:00.009+08:00| 45.0| 1|
|1970-01-01T08:00:00.010+08:00| 60.0| 1|
+-----------------------------+-----------+-----------------------+
sql语句如下
select count(charging_stauts), first_value(soc) from root.sg group by count(charging_status,5)
得到如下结果,其中由于第二个1970-01-01T08:00:00.006+08:00到1970-01-01T08:00:00.010+08:00的窗口中包含四个点,不符合size = 5的条件,因此不被输出
+-----------------------------+-----------------------------+--------------------------------------+
| Time| __endTime|first_value(root.sg.beijing.car01.soc)|
+-----------------------------+-----------------------------+--------------------------------------+
|1970-01-01T08:00:00.001+08:00|1970-01-01T08:00:00.005+08:00| 14.0|
+-----------------------------+-----------------------------+--------------------------------------+
而当使用ignoreNull将null值也考虑进来时,可以得到两个点计数为5的窗口,sql如下
select count(charging_stauts), first_value(soc) from root.sg group by count(charging_status,5,ignoreNull=false)
得到如下结果
+-----------------------------+-----------------------------+--------------------------------------+
| Time| __endTime|first_value(root.sg.beijing.car01.soc)|
+-----------------------------+-----------------------------+--------------------------------------+
|1970-01-01T08:00:00.001+08:00|1970-01-01T08:00:00.005+08:00| 14.0|
|1970-01-01T08:00:00.006+08:00|1970-01-01T08:00:00.010+08:00| 24.0|
+-----------------------------+-----------------------------+--------------------------------------+
分组聚合
路径层级分组聚合
在时间序列层级结构中,路径层级分组聚合查询用于对某一层级下同名的序列进行聚合查询。
- 使用
GROUP BY LEVEL = INT来指定需要聚合的层级,并约定ROOT为第 0 层。若统计 "root.ln" 下所有序列则需指定 level 为 1。 - 路径层次分组聚合查询支持使用所有内置聚合函数。对于
sum,avg,min_value,max_value,extreme五种聚合函数,需保证所有聚合的时间序列数据类型相同。其他聚合函数没有此限制。
示例1: 不同 database 下均存在名为 status 的序列, 如 "root.ln.wf01.wt01.status", "root.ln.wf02.wt02.status", 以及 "root.sgcc.wf03.wt01.status", 如果需要统计不同 database 下 status 序列的数据点个数,使用以下查询:
select count(status) from root.** group by level = 1
运行结果为:
+-------------------------+---------------------------+
|count(root.ln.*.*.status)|count(root.sgcc.*.*.status)|
+-------------------------+---------------------------+
| 20160| 10080|
+-------------------------+---------------------------+
Total line number = 1
It costs 0.003s
示例2: 统计不同设备下 status 序列的数据点个数,可以规定 level = 3,
select count(status) from root.** group by level = 3
运行结果为:
+---------------------------+---------------------------+
|count(root.*.*.wt01.status)|count(root.*.*.wt02.status)|
+---------------------------+---------------------------+
| 20160| 10080|
+---------------------------+---------------------------+
Total line number = 1
It costs 0.003s
注意,这时会将 database ln 和 sgcc 下名为 wt01 的设备视为同名设备聚合在一起。
示例3: 统计不同 database 下的不同设备中 status 序列的数据点个数,可以使用以下查询:
select count(status) from root.** group by level = 1, 3
运行结果为:
+----------------------------+----------------------------+------------------------------+
|count(root.ln.*.wt01.status)|count(root.ln.*.wt02.status)|count(root.sgcc.*.wt01.status)|
+----------------------------+----------------------------+------------------------------+
| 10080| 10080| 10080|
+----------------------------+----------------------------+------------------------------+
Total line number = 1
It costs 0.003s
示例4: 查询所有序列下温度传感器 temperature 的最大值,可以使用下列查询语句:
select max_value(temperature) from root.** group by level = 0
运行结果:
+---------------------------------+
|max_value(root.*.*.*.temperature)|
+---------------------------------+
| 26.0|
+---------------------------------+
Total line number = 1
It costs 0.013s
示例5: 上面的查询都是针对某一个传感器,特别地,如果想要查询某一层级下所有传感器拥有的总数据点数,则需要显式规定测点为 *
select count(*) from root.ln.** group by level = 2
运行结果:
+----------------------+----------------------+
|count(root.*.wf01.*.*)|count(root.*.wf02.*.*)|
+----------------------+----------------------+
| 20160| 20160|
+----------------------+----------------------+
Total line number = 1
It costs 0.013s
与时间区间分段聚合混合使用
通过定义 LEVEL 来统计指定层级下的数据点个数。
例如:
统计降采样后的数据点个数
select count(status) from root.ln.wf01.wt01 group by ((2017-11-01T00:00:00, 2017-11-07T23:00:00],1d), level=1;
结果:
+-----------------------------+-------------------------+
| Time|COUNT(root.ln.*.*.status)|
+-----------------------------+-------------------------+
|2017-11-02T00:00:00.000+08:00| 1440|
|2017-11-03T00:00:00.000+08:00| 1440|
|2017-11-04T00:00:00.000+08:00| 1440|
|2017-11-05T00:00:00.000+08:00| 1440|
|2017-11-06T00:00:00.000+08:00| 1440|
|2017-11-07T00:00:00.000+08:00| 1440|
|2017-11-07T23:00:00.000+08:00| 1380|
+-----------------------------+-------------------------+
Total line number = 7
It costs 0.006s
加上滑动 Step 的降采样后的结果也可以汇总
select count(status) from root.ln.wf01.wt01 group by ([2017-11-01 00:00:00, 2017-11-07 23:00:00), 3h, 1d), level=1;
+-----------------------------+-------------------------+
| Time|COUNT(root.ln.*.*.status)|
+-----------------------------+-------------------------+
|2017-11-01T00:00:00.000+08:00| 180|
|2017-11-02T00:00:00.000+08:00| 180|
|2017-11-03T00:00:00.000+08:00| 180|
|2017-11-04T00:00:00.000+08:00| 180|
|2017-11-05T00:00:00.000+08:00| 180|
|2017-11-06T00:00:00.000+08:00| 180|
|2017-11-07T00:00:00.000+08:00| 180|
+-----------------------------+-------------------------+
Total line number = 7
It costs 0.004s
标签分组聚合
IoTDB 支持通过 GROUP BY TAGS 语句根据时间序列中定义的标签的键值做分组聚合查询。
我们先在 IoTDB 中写入如下示例数据,稍后会以这些数据为例介绍标签聚合查询。
这些是某工厂 factory1 在多个城市的多个车间的设备温度数据, 时间范围为 [1000, 10000)。
时间序列路径中的设备一级是设备唯一标识。城市信息 city 和车间信息 workshop 则被建模在该设备时间序列的标签中。
其中,设备 d1、d2 在 Beijing 的 w1 车间, d3、d4 在 Beijing 的 w2 车间,d5、d6 在 Shanghai 的 w1 车间,d7 在 Shanghai 的 w2 车间。d8 和 d9 设备目前处于调试阶段,还未被分配到具体的城市和车间,所以其相应的标签值为空值。
create database root.factory1;
create timeseries root.factory1.d1.temperature with datatype=FLOAT tags(city=Beijing, workshop=w1);
create timeseries root.factory1.d2.temperature with datatype=FLOAT tags(city=Beijing, workshop=w1);
create timeseries root.factory1.d3.temperature with datatype=FLOAT tags(city=Beijing, workshop=w2);
create timeseries root.factory1.d4.temperature with datatype=FLOAT tags(city=Beijing, workshop=w2);
create timeseries root.factory1.d5.temperature with datatype=FLOAT tags(city=Shanghai, workshop=w1);
create timeseries root.factory1.d6.temperature with datatype=FLOAT tags(city=Shanghai, workshop=w1);
create timeseries root.factory1.d7.temperature with datatype=FLOAT tags(city=Shanghai, workshop=w2);
create timeseries root.factory1.d8.temperature with datatype=FLOAT;
create timeseries root.factory1.d9.temperature with datatype=FLOAT;
insert into root.factory1.d1(time, temperature) values(1000, 104.0);
insert into root.factory1.d1(time, temperature) values(3000, 104.2);
insert into root.factory1.d1(time, temperature) values(5000, 103.3);
insert into root.factory1.d1(time, temperature) values(7000, 104.1);
insert into root.factory1.d2(time, temperature) values(1000, 104.4);
insert into root.factory1.d2(time, temperature) values(3000, 103.7);
insert into root.factory1.d2(time, temperature) values(5000, 103.3);
insert into root.factory1.d2(time, temperature) values(7000, 102.9);
insert into root.factory1.d3(time, temperature) values(1000, 103.9);
insert into root.factory1.d3(time, temperature) values(3000, 103.8);
insert into root.factory1.d3(time, temperature) values(5000, 102.7);
insert into root.factory1.d3(time, temperature) values(7000, 106.9);
insert into root.factory1.d4(time, temperature) values(1000, 103.9);
insert into root.factory1.d4(time, temperature) values(5000, 102.7);
insert into root.factory1.d4(time, temperature) values(7000, 106.9);
insert into root.factory1.d5(time, temperature) values(1000, 112.9);
insert into root.factory1.d5(time, temperature) values(7000, 113.0);
insert into root.factory1.d6(time, temperature) values(1000, 113.9);
insert into root.factory1.d6(time, temperature) values(3000, 113.3);
insert into root.factory1.d6(time, temperature) values(5000, 112.7);
insert into root.factory1.d6(time, temperature) values(7000, 112.3);
insert into root.factory1.d7(time, temperature) values(1000, 101.2);
insert into root.factory1.d7(time, temperature) values(3000, 99.3);
insert into root.factory1.d7(time, temperature) values(5000, 100.1);
insert into root.factory1.d7(time, temperature) values(7000, 99.8);
insert into root.factory1.d8(time, temperature) values(1000, 50.0);
insert into root.factory1.d8(time, temperature) values(3000, 52.1);
insert into root.factory1.d8(time, temperature) values(5000, 50.1);
insert into root.factory1.d8(time, temperature) values(7000, 50.5);
insert into root.factory1.d9(time, temperature) values(1000, 50.3);
insert into root.factory1.d9(time, temperature) values(3000, 52.1);
单标签聚合查询
用户想统计该工厂每个地区的设备的温度的平均值,可以使用如下查询语句
SELECT AVG(temperature) FROM root.factory1.** GROUP BY TAGS(city);
该查询会将具有同一个 city 标签值的时间序列的所有满足查询条件的点做平均值计算,计算结果如下
+--------+------------------+
| city| avg(temperature)|
+--------+------------------+
| Beijing|104.04666697184244|
|Shanghai|107.85000076293946|
| NULL| 50.84999910990397|
+--------+------------------+
Total line number = 3
It costs 0.231s
从结果集中可以看到,和分段聚合、按层次分组聚合相比,标签聚合的查询结果的不同点是:
- 标签聚合查询的聚合结果不会再做去星号展开,而是将多个时间序列的数据作为一个整体进行聚合计算。
- 标签聚合查询除了输出聚合结果列,还会输出聚合标签的键值列。该列的列名为聚合指定的标签键,列的值则为所有查询的时间序列中出现的该标签的值。
如果某些时间序列未设置该标签,则在键值列中有一行单独的NULL,代表未设置标签的所有时间序列数据的聚合结果。
多标签分组聚合查询
除了基本的单标签聚合查询外,还可以按顺序指定多个标签进行聚合计算。
例如,用户想统计每个城市的每个车间内设备的平均温度。但因为各个城市的车间名称有可能相同,所以不能直接按照 workshop 做标签聚合。必须要先按照城市,再按照车间处理。
SQL 语句如下
SELECT avg(temperature) FROM root.factory1.** GROUP BY TAGS(city, workshop);
查询结果如下
+--------+--------+------------------+
| city|workshop| avg(temperature)|
+--------+--------+------------------+
| NULL| NULL| 50.84999910990397|
|Shanghai| w1|113.01666768391927|
| Beijing| w2| 104.4000004359654|
|Shanghai| w2|100.10000038146973|
| Beijing| w1|103.73750019073486|
+--------+--------+------------------+
Total line number = 5
It costs 0.027s
从结果集中可以看到,和单标签聚合相比,多标签聚合的查询结果会根据指定的标签顺序,输出相应标签的键值列。
基于时间区间的标签聚合查询
按照时间区间聚合是时序数据库中最常用的查询需求之一。IoTDB 在基于时间区间的聚合基础上,支持进一步按照标签进行聚合查询。
例如,用户想统计时间 [1000, 10000) 范围内,每个城市每个车间中的设备每 5 秒内的平均温度。
SQL 语句如下
SELECT AVG(temperature) FROM root.factory1.** GROUP BY ([1000, 10000), 5s), TAGS(city, workshop);
查询结果如下
+-----------------------------+--------+--------+------------------+
| Time| city|workshop| avg(temperature)|
+-----------------------------+--------+--------+------------------+
|1970-01-01T08:00:01.000+08:00| NULL| NULL| 50.91999893188476|
|1970-01-01T08:00:01.000+08:00|Shanghai| w1|113.20000076293945|
|1970-01-01T08:00:01.000+08:00| Beijing| w2| 103.4|
|1970-01-01T08:00:01.000+08:00|Shanghai| w2| 100.1999994913737|
|1970-01-01T08:00:01.000+08:00| Beijing| w1|103.81666692097981|
|1970-01-01T08:00:06.000+08:00| NULL| NULL| 50.5|
|1970-01-01T08:00:06.000+08:00|Shanghai| w1| 112.6500015258789|
|1970-01-01T08:00:06.000+08:00| Beijing| w2| 106.9000015258789|
|1970-01-01T08:00:06.000+08:00|Shanghai| w2| 99.80000305175781|
|1970-01-01T08:00:06.000+08:00| Beijing| w1| 103.5|
+-----------------------------+--------+--------+------------------+
和标签聚合相比,基于时间区间的标签聚合的查询会首先按照时间区间划定聚合范围,在时间区间内部再根据指定的标签顺序,进行相应数据的聚合计算。在输出的结果集中,会包含一列时间列,该时间列值的含义和时间区间聚合查询的相同。
标签分组聚合的限制
由于标签聚合功能仍然处于开发阶段,目前有如下未实现功能。
- 暂不支持
HAVING子句过滤查询结果。- 暂不支持结果按照标签值排序。
- 暂不支持
LIMIT,OFFSET,SLIMIT,SOFFSET。- 暂不支持
ALIGN BY DEVICE。- 暂不支持聚合函数内部包含表达式,例如
count(s+1)。- 不支持值过滤条件聚合,和分层聚合查询行为保持一致。
聚合结果过滤(HAVING 子句)
如果想对聚合查询的结果进行过滤,可以在 GROUP BY 子句之后使用 HAVING 子句。
注意:
HAVING子句中的过滤条件必须由聚合值构成,原始序列不能单独出现。下列使用方式是不正确的:
select count(s1) from root.** group by ([1,3),1ms) having sum(s1) > s1 select count(s1) from root.** group by ([1,3),1ms) having s1 > 1对
GROUP BY LEVEL结果进行过滤时,SELECT和HAVING中出现的PATH只能有一级。下列使用方式是不正确的:
select count(s1) from root.** group by ([1,3),1ms), level=1 having sum(d1.s1) > 1 select count(d1.s1) from root.** group by ([1,3),1ms), level=1 having sum(s1) > 1
SQL 示例:
示例 1:
对于以下聚合结果进行过滤:
+-----------------------------+---------------------+---------------------+ | Time|count(root.test.*.s1)|count(root.test.*.s2)| +-----------------------------+---------------------+---------------------+ |1970-01-01T08:00:00.001+08:00| 4| 4| |1970-01-01T08:00:00.003+08:00| 1| 0| |1970-01-01T08:00:00.005+08:00| 2| 4| |1970-01-01T08:00:00.007+08:00| 3| 2| |1970-01-01T08:00:00.009+08:00| 4| 4| +-----------------------------+---------------------+---------------------+select count(s1) from root.** group by ([1,11),2ms), level=1 having count(s2) > 2;执行结果如下:
+-----------------------------+---------------------+ | Time|count(root.test.*.s1)| +-----------------------------+---------------------+ |1970-01-01T08:00:00.001+08:00| 4| |1970-01-01T08:00:00.005+08:00| 2| |1970-01-01T08:00:00.009+08:00| 4| +-----------------------------+---------------------+示例 2:
对于以下聚合结果进行过滤:
+-----------------------------+-------------+---------+---------+ | Time| Device|count(s1)|count(s2)| +-----------------------------+-------------+---------+---------+ |1970-01-01T08:00:00.001+08:00|root.test.sg1| 1| 2| |1970-01-01T08:00:00.003+08:00|root.test.sg1| 1| 0| |1970-01-01T08:00:00.005+08:00|root.test.sg1| 1| 2| |1970-01-01T08:00:00.007+08:00|root.test.sg1| 2| 1| |1970-01-01T08:00:00.009+08:00|root.test.sg1| 2| 2| |1970-01-01T08:00:00.001+08:00|root.test.sg2| 2| 2| |1970-01-01T08:00:00.003+08:00|root.test.sg2| 0| 0| |1970-01-01T08:00:00.005+08:00|root.test.sg2| 1| 2| |1970-01-01T08:00:00.007+08:00|root.test.sg2| 1| 1| |1970-01-01T08:00:00.009+08:00|root.test.sg2| 2| 2| +-----------------------------+-------------+---------+---------+select count(s1), count(s2) from root.** group by ([1,11),2ms) having count(s2) > 1 align by device;执行结果如下:
+-----------------------------+-------------+---------+---------+ | Time| Device|count(s1)|count(s2)| +-----------------------------+-------------+---------+---------+ |1970-01-01T08:00:00.001+08:00|root.test.sg1| 1| 2| |1970-01-01T08:00:00.005+08:00|root.test.sg1| 1| 2| |1970-01-01T08:00:00.009+08:00|root.test.sg1| 2| 2| |1970-01-01T08:00:00.001+08:00|root.test.sg2| 2| 2| |1970-01-01T08:00:00.005+08:00|root.test.sg2| 1| 2| |1970-01-01T08:00:00.009+08:00|root.test.sg2| 2| 2| +-----------------------------+-------------+---------+---------+
结果集补空值(FILL 子句)
功能介绍
当执行一些数据查询时,结果集的某行某列可能没有数据,则此位置结果为空,但这种空值不利于进行数据可视化展示和分析,需要对空值进行填充。
在 IoTDB 中,用户可以使用 FILL 子句指定数据缺失情况下的填充模式,允许用户按照特定的方法对任何查询的结果集填充空值,如取前一个不为空的值、线性插值等。
语法定义
FILL 子句的语法定义如下:
FILL '(' PREVIOUS | LINEAR | constant ')'
注意:
- 在
Fill语句中只能指定一种填充方法,该方法作用于结果集的全部列。 - 空值填充不兼容 0.13 版本及以前的语法(即不支持
FILL((<data_type>[<fill_method>(, <before_range>, <after_range>)?])+))
填充方式
IoTDB 目前支持以下三种空值填充方式:
PREVIOUS填充:使用该列前一个非空值进行填充。LINEAR填充:使用该列前一个非空值和下一个非空值的线性插值进行填充。- 常量填充:使用指定常量填充。
各数据类型支持的填充方法如下表所示:
| 数据类型 | 支持的填充方法 |
|---|---|
| BOOLEAN | PREVIOUS、常量 |
| INT32 | PREVIOUS、LINEAR、常量 |
| INT64 | PREVIOUS、LINEAR、常量 |
| FLOAT | PREVIOUS、LINEAR、常量 |
| DOUBLE | PREVIOUS、LINEAR、常量 |
| TEXT | PREVIOUS、常量 |
注意: 对于数据类型不支持指定填充方法的列,既不会填充它,也不会报错,只是让那一列保持原样。
下面通过举例进一步说明。
如果我们不使用任何填充方式:
select temperature, status from root.sgcc.wf03.wt01 where time >= 2017-11-01T16:37:00.000 and time <= 2017-11-01T16:40:00.000;
查询结果如下:
+-----------------------------+-------------------------------+--------------------------+
| Time|root.sgcc.wf03.wt01.temperature|root.sgcc.wf03.wt01.status|
+-----------------------------+-------------------------------+--------------------------+
|2017-11-01T16:37:00.000+08:00| 21.93| true|
+-----------------------------+-------------------------------+--------------------------+
|2017-11-01T16:38:00.000+08:00| null| false|
+-----------------------------+-------------------------------+--------------------------+
|2017-11-01T16:39:00.000+08:00| 22.23| null|
+-----------------------------+-------------------------------+--------------------------+
|2017-11-01T16:40:00.000+08:00| 23.43| null|
+-----------------------------+-------------------------------+--------------------------+
Total line number = 4
PREVIOUS 填充
对于查询结果集中的空值,使用该列前一个非空值进行填充。
注意: 如果结果集的某一列第一个值就为空,则不会填充该值,直到遇到该列第一个非空值为止。
例如,使用 PREVIOUS 填充,SQL 语句如下:
select temperature, status from root.sgcc.wf03.wt01 where time >= 2017-11-01T16:37:00.000 and time <= 2017-11-01T16:40:00.000 fill(previous);
PREVIOUS 填充后的结果如下:
+-----------------------------+-------------------------------+--------------------------+
| Time|root.sgcc.wf03.wt01.temperature|root.sgcc.wf03.wt01.status|
+-----------------------------+-------------------------------+--------------------------+
|2017-11-01T16:37:00.000+08:00| 21.93| true|
+-----------------------------+-------------------------------+--------------------------+
|2017-11-01T16:38:00.000+08:00| 21.93| false|
+-----------------------------+-------------------------------+--------------------------+
|2017-11-01T16:39:00.000+08:00| 22.23| false|
+-----------------------------+-------------------------------+--------------------------+
|2017-11-01T16:40:00.000+08:00| 23.43| false|
+-----------------------------+-------------------------------+--------------------------+
Total line number = 4
在前值填充时,能够支持指定一个时间间隔,如果当前null值的时间戳与前一个非null值的时间戳的间隔,超过指定的时间间隔,则不进行填充。
- 在线性填充和常量填充的情况下,如果指定了第二个参数,会抛出异常
- 时间超时参数仅支持整数
例如,原始数据如下所示:
select s1 from root.db.d1
+-----------------------------+-------------+
| Time|root.db.d1.s1|
+-----------------------------+-------------+
|2023-11-08T16:41:50.008+08:00| 1.0|
+-----------------------------+-------------+
|2023-11-08T16:46:50.011+08:00| 2.0|
+-----------------------------+-------------+
|2023-11-08T16:48:50.011+08:00| 3.0|
+-----------------------------+-------------+
根据时间分组,每1分钟求一个平均值
select avg(s1)
from root.db.d1
group by([2023-11-08T16:40:00.008+08:00, 2023-11-08T16:50:00.008+08:00), 1m)
+-----------------------------+------------------+
| Time|avg(root.db.d1.s1)|
+-----------------------------+------------------+
|2023-11-08T16:40:00.008+08:00| null|
+-----------------------------+------------------+
|2023-11-08T16:41:00.008+08:00| 1.0|
+-----------------------------+------------------+
|2023-11-08T16:42:00.008+08:00| null|
+-----------------------------+------------------+
|2023-11-08T16:43:00.008+08:00| null|
+-----------------------------+------------------+
|2023-11-08T16:44:00.008+08:00| null|
+-----------------------------+------------------+
|2023-11-08T16:45:00.008+08:00| null|
+-----------------------------+------------------+
|2023-11-08T16:46:00.008+08:00| 2.0|
+-----------------------------+------------------+
|2023-11-08T16:47:00.008+08:00| null|
+-----------------------------+------------------+
|2023-11-08T16:48:00.008+08:00| 3.0|
+-----------------------------+------------------+
|2023-11-08T16:49:00.008+08:00| null|
+-----------------------------+------------------+
根据时间分组并用前值填充
select avg(s1)
from root.db.d1
group by([2023-11-08T16:40:00.008+08:00, 2023-11-08T16:50:00.008+08:00), 1m)
FILL(PREVIOUS);
+-----------------------------+------------------+
| Time|avg(root.db.d1.s1)|
+-----------------------------+------------------+
|2023-11-08T16:40:00.008+08:00| null|
+-----------------------------+------------------+
|2023-11-08T16:41:00.008+08:00| 1.0|
+-----------------------------+------------------+
|2023-11-08T16:42:00.008+08:00| 1.0|
+-----------------------------+------------------+
|2023-11-08T16:43:00.008+08:00| 1.0|
+-----------------------------+------------------+
|2023-11-08T16:44:00.008+08:00| 1.0|
+-----------------------------+------------------+
|2023-11-08T16:45:00.008+08:00| 1.0|
+-----------------------------+------------------+
|2023-11-08T16:46:00.008+08:00| 2.0|
+-----------------------------+------------------+
|2023-11-08T16:47:00.008+08:00| 2.0|
+-----------------------------+------------------+
|2023-11-08T16:48:00.008+08:00| 3.0|
+-----------------------------+------------------+
|2023-11-08T16:49:00.008+08:00| 3.0|
+-----------------------------+------------------+
根据时间分组并用前值填充,并指定超过2分钟的就不填充
select avg(s1)
from root.db.d1
group by([2023-11-08T16:40:00.008+08:00, 2023-11-08T16:50:00.008+08:00), 1m)
FILL(PREVIOUS, 2m);
+-----------------------------+------------------+
| Time|avg(root.db.d1.s1)|
+-----------------------------+------------------+
|2023-11-08T16:40:00.008+08:00| null|
+-----------------------------+------------------+
|2023-11-08T16:41:00.008+08:00| 1.0|
+-----------------------------+------------------+
|2023-11-08T16:42:00.008+08:00| 1.0|
+-----------------------------+------------------+
|2023-11-08T16:43:00.008+08:00| 1.0|
+-----------------------------+------------------+
|2023-11-08T16:44:00.008+08:00| null|
+-----------------------------+------------------+
|2023-11-08T16:45:00.008+08:00| null|
+-----------------------------+------------------+
|2023-11-08T16:46:00.008+08:00| 2.0|
+-----------------------------+------------------+
|2023-11-08T16:47:00.008+08:00| 2.0|
+-----------------------------+------------------+
|2023-11-08T16:48:00.008+08:00| 3.0|
+-----------------------------+------------------+
|2023-11-08T16:49:00.008+08:00| 3.0|
+-----------------------------+------------------+
LINEAR 填充
对于查询结果集中的空值,使用该列前一个非空值和下一个非空值的线性插值进行填充。
注意:
- 如果某个值之前的所有值都为空,或者某个值之后的所有值都为空,则不会填充该值。
- 如果某列的数据类型为boolean/text,我们既不会填充它,也不会报错,只是让那一列保持原样。
例如,使用 LINEAR 填充,SQL 语句如下:
select temperature, status from root.sgcc.wf03.wt01 where time >= 2017-11-01T16:37:00.000 and time <= 2017-11-01T16:40:00.000 fill(linear);
LINEAR 填充后的结果如下:
+-----------------------------+-------------------------------+--------------------------+
| Time|root.sgcc.wf03.wt01.temperature|root.sgcc.wf03.wt01.status|
+-----------------------------+-------------------------------+--------------------------+
|2017-11-01T16:37:00.000+08:00| 21.93| true|
+-----------------------------+-------------------------------+--------------------------+
|2017-11-01T16:38:00.000+08:00| 22.08| false|
+-----------------------------+-------------------------------+--------------------------+
|2017-11-01T16:39:00.000+08:00| 22.23| null|
+-----------------------------+-------------------------------+--------------------------+
|2017-11-01T16:40:00.000+08:00| 23.43| null|
+-----------------------------+-------------------------------+--------------------------+
Total line number = 4
常量填充
对于查询结果集中的空值,使用指定常量填充。
注意:
如果某列数据类型与常量类型不兼容,既不填充该列,也不报错,将该列保持原样。对于常量兼容的数据类型,如下表所示:
常量类型 能够填充的序列数据类型 BOOLEANBOOLEANTEXTINT64INT32INT64FLOATDOUBLETEXTDOUBLEFLOATDOUBLETEXTTEXTTEXT当常量值大于
INT32所能表示的最大值时,对于INT32类型的列,既不填充该列,也不报错,将该列保持原样。
例如,使用 FLOAT 类型的常量填充,SQL 语句如下:
select temperature, status from root.sgcc.wf03.wt01 where time >= 2017-11-01T16:37:00.000 and time <= 2017-11-01T16:40:00.000 fill(2.0);
FLOAT 类型的常量填充后的结果如下:
+-----------------------------+-------------------------------+--------------------------+
| Time|root.sgcc.wf03.wt01.temperature|root.sgcc.wf03.wt01.status|
+-----------------------------+-------------------------------+--------------------------+
|2017-11-01T16:37:00.000+08:00| 21.93| true|
+-----------------------------+-------------------------------+--------------------------+
|2017-11-01T16:38:00.000+08:00| 2.0| false|
+-----------------------------+-------------------------------+--------------------------+
|2017-11-01T16:39:00.000+08:00| 22.23| null|
+-----------------------------+-------------------------------+--------------------------+
|2017-11-01T16:40:00.000+08:00| 23.43| null|
+-----------------------------+-------------------------------+--------------------------+
Total line number = 4
再比如,使用 BOOLEAN 类型的常量填充,SQL 语句如下:
select temperature, status from root.sgcc.wf03.wt01 where time >= 2017-11-01T16:37:00.000 and time <= 2017-11-01T16:40:00.000 fill(true);
BOOLEAN 类型的常量填充后的结果如下:
+-----------------------------+-------------------------------+--------------------------+
| Time|root.sgcc.wf03.wt01.temperature|root.sgcc.wf03.wt01.status|
+-----------------------------+-------------------------------+--------------------------+
|2017-11-01T16:37:00.000+08:00| 21.93| true|
+-----------------------------+-------------------------------+--------------------------+
|2017-11-01T16:38:00.000+08:00| null| false|
+-----------------------------+-------------------------------+--------------------------+
|2017-11-01T16:39:00.000+08:00| 22.23| true|
+-----------------------------+-------------------------------+--------------------------+
|2017-11-01T16:40:00.000+08:00| 23.43| true|
+-----------------------------+-------------------------------+--------------------------+
Total line number = 4
查询结果分页(LIMIT/SLIMIT 子句)
当查询结果集数据量很大,放在一个页面不利于显示,可以使用 LIMIT/SLIMIT 子句和 OFFSET/SOFFSET 子句进行分页控制。
LIMIT和SLIMIT子句用于控制查询结果的行数和列数。OFFSET和SOFFSET子句用于控制结果显示的起始位置。
按行分页
用户可以通过 LIMIT 和 OFFSET 子句控制查询结果的行数,LIMIT rowLimit 指定查询结果的行数,OFFSET rowOffset 指定查询结果显示的起始行位置。
注意:
- 当
rowOffset超过结果集的大小时,返回空结果集。 - 当
rowLimit超过结果集的大小时,返回所有查询结果。 - 当
rowLimit和rowOffset不是正整数,或超过INT64允许的最大值时,系统将提示错误。
我们将通过以下示例演示如何使用 LIMIT 和 OFFSET 子句。
- 示例 1: 基本的
LIMIT子句
SQL 语句:
select status, temperature from root.ln.wf01.wt01 limit 10
含义:
所选设备为 ln 组 wf01 工厂 wt01 设备; 选择的时间序列是“状态”和“温度”。 SQL 语句要求返回查询结果的前 10 行。
结果如下所示:
+-----------------------------+------------------------+-----------------------------+
| Time|root.ln.wf01.wt01.status|root.ln.wf01.wt01.temperature|
+-----------------------------+------------------------+-----------------------------+
|2017-11-01T00:00:00.000+08:00| true| 25.96|
|2017-11-01T00:01:00.000+08:00| true| 24.36|
|2017-11-01T00:02:00.000+08:00| false| 20.09|
|2017-11-01T00:03:00.000+08:00| false| 20.18|
|2017-11-01T00:04:00.000+08:00| false| 21.13|
|2017-11-01T00:05:00.000+08:00| false| 22.72|
|2017-11-01T00:06:00.000+08:00| false| 20.71|
|2017-11-01T00:07:00.000+08:00| false| 21.45|
|2017-11-01T00:08:00.000+08:00| false| 22.58|
|2017-11-01T00:09:00.000+08:00| false| 20.98|
+-----------------------------+------------------------+-----------------------------+
Total line number = 10
It costs 0.000s
- 示例 2: 带
OFFSET的LIMIT子句
SQL 语句:
select status, temperature from root.ln.wf01.wt01 limit 5 offset 3
含义:
所选设备为 ln 组 wf01 工厂 wt01 设备; 选择的时间序列是“状态”和“温度”。 SQL 语句要求返回查询结果的第 3 至 7 行(第一行编号为 0 行)。
结果如下所示:
+-----------------------------+------------------------+-----------------------------+
| Time|root.ln.wf01.wt01.status|root.ln.wf01.wt01.temperature|
+-----------------------------+------------------------+-----------------------------+
|2017-11-01T00:03:00.000+08:00| false| 20.18|
|2017-11-01T00:04:00.000+08:00| false| 21.13|
|2017-11-01T00:05:00.000+08:00| false| 22.72|
|2017-11-01T00:06:00.000+08:00| false| 20.71|
|2017-11-01T00:07:00.000+08:00| false| 21.45|
+-----------------------------+------------------------+-----------------------------+
Total line number = 5
It costs 0.342s
- 示例 3:
LIMIT子句与WHERE子句结合
SQL 语句:
select status,temperature from root.ln.wf01.wt01 where time > 2024-07-07T00:05:00.000 and time< 2024-07-12T00:12:00.000 limit 5 offset 3
含义:
所选设备为 ln 组 wf01 工厂 wt01 设备; 选择的时间序列是“状态”和“温度”。 SQL 语句要求返回时间“ 2024-07-07T00:05:00.000”和“ 2024-07-12T00:12:00.000”之间的状态和温度传感器值的第 3 至 7 行(第一行编号为第 0 行)。
结果如下所示:
+-----------------------------+------------------------+-----------------------------+
| Time|root.ln.wf01.wt01.status|root.ln.wf01.wt01.temperature|
+-----------------------------+------------------------+-----------------------------+
|2024-07-09T17:32:11.943+08:00| true| 24.941973|
|2024-07-09T17:32:12.944+08:00| true| 20.05108|
|2024-07-09T17:32:13.945+08:00| true| 20.541632|
|2024-07-09T17:32:14.945+08:00| null| 23.09016|
|2024-07-09T17:32:14.946+08:00| true| null|
+-----------------------------+------------------------+-----------------------------+
Total line number = 5
It costs 0.070s
``
- **示例 4:** `LIMIT` 子句与 `GROUP BY` 子句组合
SQL 语句:
```sql
select count(status), max_value(temperature) from root.ln.wf01.wt01 group by ([2017-11-01T00:00:00, 2017-11-07T23:00:00),1d) limit 4 offset 3
含义:
SQL 语句子句要求返回查询结果的第 3 至 6 行(第一行编号为 0 行)。
结果如下所示:
+-----------------------------+-------------------------------+----------------------------------------+
| Time|count(root.ln.wf01.wt01.status)|max_value(root.ln.wf01.wt01.temperature)|
+-----------------------------+-------------------------------+----------------------------------------+
|2017-11-04T00:00:00.000+08:00| 1440| 26.0|
|2017-11-05T00:00:00.000+08:00| 1440| 26.0|
|2017-11-06T00:00:00.000+08:00| 1440| 25.99|
|2017-11-07T00:00:00.000+08:00| 1380| 26.0|
+-----------------------------+-------------------------------+----------------------------------------+
Total line number = 4
It costs 0.016s
按列分页
用户可以通过 SLIMIT 和 SOFFSET 子句控制查询结果的列数,SLIMIT seriesLimit 指定查询结果的列数,SOFFSET seriesOffset 指定查询结果显示的起始列位置。
注意:
- 仅用于控制值列,对时间列和设备列无效。
- 当
seriesOffset超过结果集的大小时,返回空结果集。 - 当
seriesLimit超过结果集的大小时,返回所有查询结果。 - 当
seriesLimit和seriesOffset不是正整数,或超过INT64允许的最大值时,系统将提示错误。
我们将通过以下示例演示如何使用 SLIMIT 和 SOFFSET 子句。
- 示例 1: 基本的
SLIMIT子句
SQL 语句:
select * from root.ln.wf01.wt01 where time > 2017-11-01T00:05:00.000 and time < 2017-11-01T00:12:00.000 slimit 1
含义:
所选设备为 ln 组 wf01 工厂 wt01 设备; 所选时间序列是该设备下的第二列,即温度。 SQL 语句要求在"2017-11-01T00:05:00.000"和"2017-11-01T00:12:00.000"的时间点之间选择温度传感器值。
结果如下所示:
+-----------------------------+-----------------------------+
| Time|root.ln.wf01.wt01.temperature|
+-----------------------------+-----------------------------+
|2017-11-01T00:06:00.000+08:00| 20.71|
|2017-11-01T00:07:00.000+08:00| 21.45|
|2017-11-01T00:08:00.000+08:00| 22.58|
|2017-11-01T00:09:00.000+08:00| 20.98|
|2017-11-01T00:10:00.000+08:00| 25.52|
|2017-11-01T00:11:00.000+08:00| 22.91|
+-----------------------------+-----------------------------+
Total line number = 6
It costs 0.000s
- 示例 2: 带
SOFFSET的SLIMIT子句
SQL 语句:
select * from root.ln.wf01.wt01 where time > 2017-11-01T00:05:00.000 and time < 2017-11-01T00:12:00.000 slimit 1 soffset 1
含义:
所选设备为 ln 组 wf01 工厂 wt01 设备; 所选时间序列是该设备下的第一列,即电源状态。 SQL 语句要求在" 2017-11-01T00:05:00.000"和"2017-11-01T00:12:00.000"的时间点之间选择状态传感器值。
结果如下所示:
+-----------------------------+------------------------+
| Time|root.ln.wf01.wt01.status|
+-----------------------------+------------------------+
|2017-11-01T00:06:00.000+08:00| false|
|2017-11-01T00:07:00.000+08:00| false|
|2017-11-01T00:08:00.000+08:00| false|
|2017-11-01T00:09:00.000+08:00| false|
|2017-11-01T00:10:00.000+08:00| true|
|2017-11-01T00:11:00.000+08:00| false|
+-----------------------------+------------------------+
Total line number = 6
It costs 0.003s
- 示例 3:
SLIMIT子句与GROUP BY子句结合
SQL 语句:
select max_value(*) from root.ln.wf01.wt01 group by ([2017-11-01T00:00:00, 2017-11-07T23:00:00),1d) slimit 1 soffset 1
含义:
+-----------------------------+-----------------------------------+
| Time|max_value(root.ln.wf01.wt01.status)|
+-----------------------------+-----------------------------------+
|2017-11-01T00:00:00.000+08:00| true|
|2017-11-02T00:00:00.000+08:00| true|
|2017-11-03T00:00:00.000+08:00| true|
|2017-11-04T00:00:00.000+08:00| true|
|2017-11-05T00:00:00.000+08:00| true|
|2017-11-06T00:00:00.000+08:00| true|
|2017-11-07T00:00:00.000+08:00| true|
+-----------------------------+-----------------------------------+
Total line number = 7
It costs 0.000s
- 示例 4:
SLIMIT子句与LIMIT子句结合
SQL 语句:
select * from root.ln.wf01.wt01 limit 10 offset 100 slimit 2 soffset 0
含义:
所选设备为 ln 组 wf01 工厂 wt01 设备; 所选时间序列是此设备下的第 0 列至第 1 列(第一列编号为第 0 列)。 SQL 语句子句要求返回查询结果的第 100 至 109 行(第一行编号为 0 行)。
结果如下所示:
+-----------------------------+-----------------------------+------------------------+
| Time|root.ln.wf01.wt01.temperature|root.ln.wf01.wt01.status|
+-----------------------------+-----------------------------+------------------------+
|2017-11-01T01:40:00.000+08:00| 21.19| false|
|2017-11-01T01:41:00.000+08:00| 22.79| false|
|2017-11-01T01:42:00.000+08:00| 22.98| false|
|2017-11-01T01:43:00.000+08:00| 21.52| false|
|2017-11-01T01:44:00.000+08:00| 23.45| true|
|2017-11-01T01:45:00.000+08:00| 24.06| true|
|2017-11-01T01:46:00.000+08:00| 22.6| false|
|2017-11-01T01:47:00.000+08:00| 23.78| true|
|2017-11-01T01:48:00.000+08:00| 24.72| true|
|2017-11-01T01:49:00.000+08:00| 24.68| true|
+-----------------------------+-----------------------------+------------------------+
Total line number = 10
It costs 0.009s
结果集排序(ORDER BY 子句)
时间对齐模式下的排序
IoTDB的查询结果集默认按照时间对齐,可以使用ORDER BY TIME的子句指定时间戳的排列顺序。示例代码如下:
select * from root.ln.** where time <= 2017-11-01T00:01:00 order by time desc;
执行结果:
+-----------------------------+--------------------------+------------------------+-----------------------------+------------------------+
| Time|root.ln.wf02.wt02.hardware|root.ln.wf02.wt02.status|root.ln.wf01.wt01.temperature|root.ln.wf01.wt01.status|
+-----------------------------+--------------------------+------------------------+-----------------------------+------------------------+
|2017-11-01T00:01:00.000+08:00| v2| true| 24.36| true|
|2017-11-01T00:00:00.000+08:00| v2| true| 25.96| true|
|1970-01-01T08:00:00.002+08:00| v2| false| null| null|
|1970-01-01T08:00:00.001+08:00| v1| true| null| null|
+-----------------------------+--------------------------+------------------------+-----------------------------+------------------------+
设备对齐模式下的排序
当使用ALIGN BY DEVICE查询对齐模式下的结果集时,可以使用ORDER BY子句对返回的结果集顺序进行规定。
在设备对齐模式下支持4种排序模式的子句,其中包括两种排序键,DEVICE和TIME,靠前的排序键为主排序键,每种排序键都支持ASC和DESC两种排列顺序。
ORDER BY DEVICE: 按照设备名的字典序进行排序,排序方式为字典序排序,在这种情况下,相同名的设备会以组的形式进行展示。ORDER BY TIME: 按照时间戳进行排序,此时不同的设备对应的数据点会按照时间戳的优先级被打乱排序。ORDER BY DEVICE,TIME: 按照设备名的字典序进行排序,设备名相同的数据点会通过时间戳进行排序。ORDER BY TIME,DEVICE: 按照时间戳进行排序,时间戳相同的数据点会通过设备名的字典序进行排序。
为了保证结果的可观性,当不使用
ORDER BY子句,仅使用ALIGN BY DEVICE时,会为设备视图提供默认的排序方式。其中默认的排序视图为ORDER BY DEVCE,TIME,默认的排序顺序为ASC,
即结果集默认先按照设备名升序排列,在相同设备名内再按照时间戳升序排序。
当主排序键为DEVICE时,结果集的格式与默认情况类似:先按照设备名对结果进行排列,在相同的设备名下内按照时间戳进行排序。示例代码如下:
select * from root.ln.** where time <= 2017-11-01T00:01:00 order by device desc,time asc align by device;
执行结果:
+-----------------------------+-----------------+--------+------+-----------+
| Time| Device|hardware|status|temperature|
+-----------------------------+-----------------+--------+------+-----------+
|1970-01-01T08:00:00.001+08:00|root.ln.wf02.wt02| v1| true| null|
|1970-01-01T08:00:00.002+08:00|root.ln.wf02.wt02| v2| false| null|
|2017-11-01T00:00:00.000+08:00|root.ln.wf02.wt02| v2| true| null|
|2017-11-01T00:01:00.000+08:00|root.ln.wf02.wt02| v2| true| null|
|2017-11-01T00:00:00.000+08:00|root.ln.wf01.wt01| null| true| 25.96|
|2017-11-01T00:01:00.000+08:00|root.ln.wf01.wt01| null| true| 24.36|
+-----------------------------+-----------------+--------+------+-----------+
主排序键为Time时,结果集会先按照时间戳进行排序,在时间戳相等时按照设备名排序。
示例代码如下:
select * from root.ln.** where time <= 2017-11-01T00:01:00 order by time asc,device desc align by device;
执行结果:
+-----------------------------+-----------------+--------+------+-----------+
| Time| Device|hardware|status|temperature|
+-----------------------------+-----------------+--------+------+-----------+
|1970-01-01T08:00:00.001+08:00|root.ln.wf02.wt02| v1| true| null|
|1970-01-01T08:00:00.002+08:00|root.ln.wf02.wt02| v2| false| null|
|2017-11-01T00:00:00.000+08:00|root.ln.wf02.wt02| v2| true| null|
|2017-11-01T00:00:00.000+08:00|root.ln.wf01.wt01| null| true| 25.96|
|2017-11-01T00:01:00.000+08:00|root.ln.wf02.wt02| v2| true| null|
|2017-11-01T00:01:00.000+08:00|root.ln.wf01.wt01| null| true| 24.36|
+-----------------------------+-----------------+--------+------+-----------+
当没有显式指定时,主排序键默认为Device,排序顺序默认为ASC,示例代码如下:
select * from root.ln.** where time <= 2017-11-01T00:01:00 align by device;
结果如图所示,可以看出,ORDER BY DEVICE ASC,TIME ASC就是默认情况下的排序方式,由于ASC是默认排序顺序,此处可以省略。
+-----------------------------+-----------------+--------+------+-----------+
| Time| Device|hardware|status|temperature|
+-----------------------------+-----------------+--------+------+-----------+
|2017-11-01T00:00:00.000+08:00|root.ln.wf01.wt01| null| true| 25.96|
|2017-11-01T00:01:00.000+08:00|root.ln.wf01.wt01| null| true| 24.36|
|1970-01-01T08:00:00.001+08:00|root.ln.wf02.wt02| v1| true| null|
|1970-01-01T08:00:00.002+08:00|root.ln.wf02.wt02| v2| false| null|
|2017-11-01T00:00:00.000+08:00|root.ln.wf02.wt02| v2| true| null|
|2017-11-01T00:01:00.000+08:00|root.ln.wf02.wt02| v2| true| null|
+-----------------------------+-----------------+--------+------+-----------+
同样,可以在聚合查询中使用ALIGN BY DEVICE和ORDER BY子句,对聚合后的结果进行排序,示例代码如下所示:
select count(*) from root.ln.** group by ((2017-11-01T00:00:00.000+08:00,2017-11-01T00:03:00.000+08:00],1m) order by device asc,time asc align by device
执行结果:
+-----------------------------+-----------------+---------------+-------------+------------------+
| Time| Device|count(hardware)|count(status)|count(temperature)|
+-----------------------------+-----------------+---------------+-------------+------------------+
|2017-11-01T00:01:00.000+08:00|root.ln.wf01.wt01| null| 1| 1|
|2017-11-01T00:02:00.000+08:00|root.ln.wf01.wt01| null| 0| 0|
|2017-11-01T00:03:00.000+08:00|root.ln.wf01.wt01| null| 0| 0|
|2017-11-01T00:01:00.000+08:00|root.ln.wf02.wt02| 1| 1| null|
|2017-11-01T00:02:00.000+08:00|root.ln.wf02.wt02| 0| 0| null|
|2017-11-01T00:03:00.000+08:00|root.ln.wf02.wt02| 0| 0| null|
+-----------------------------+-----------------+---------------+-------------+------------------+
任意表达式排序
除了IoTDB中规定的Time,Device关键字外,还可以通过ORDER BY子句对指定时间序列中任意列的表达式进行排序。
排序在通过ASC,DESC指定排序顺序的同时,可以通过NULLS语法来指定NULL值在排序中的优先级,NULLS FIRST默认NULL值在结果集的最上方,NULLS LAST则保证NULL值在结果集的最后。如果没有在子句中指定,则默认顺序为ASC,NULLS LAST。
对于如下的数据,将给出几个任意表达式的查询示例供参考:
+-----------------------------+-------------+-------+-------+--------+-------+
| Time| Device| base| score| bonus| total|
+-----------------------------+-------------+-------+-------+--------+-------+
|1970-01-01T08:00:00.000+08:00| root.one| 12| 50.0| 45.0| 107.0|
|1970-01-02T08:00:00.000+08:00| root.one| 10| 50.0| 45.0| 105.0|
|1970-01-03T08:00:00.000+08:00| root.one| 8| 50.0| 45.0| 103.0|
|1970-01-01T08:00:00.010+08:00| root.two| 9| 50.0| 15.0| 74.0|
|1970-01-01T08:00:00.020+08:00| root.two| 8| 10.0| 15.0| 33.0|
|1970-01-01T08:00:00.010+08:00| root.three| 9| null| 24.0| 33.0|
|1970-01-01T08:00:00.020+08:00| root.three| 8| null| 22.5| 30.5|
|1970-01-01T08:00:00.030+08:00| root.three| 7| null| 23.5| 30.5|
|1970-01-01T08:00:00.010+08:00| root.four| 9| 32.0| 45.0| 86.0|
|1970-01-01T08:00:00.020+08:00| root.four| 8| 32.0| 45.0| 85.0|
|1970-01-01T08:00:00.030+08:00| root.five| 7| 53.0| 44.0| 104.0|
|1970-01-01T08:00:00.040+08:00| root.five| 6| 54.0| 42.0| 102.0|
+-----------------------------+-------------+-------+-------+--------+-------+
当需要根据基础分数score对结果进行排序时,可以直接使用
select score from root.** order by score desc align by device
会得到如下结果
+-----------------------------+---------+-----+
| Time| Device|score|
+-----------------------------+---------+-----+
|1970-01-01T08:00:00.040+08:00|root.five| 54.0|
|1970-01-01T08:00:00.030+08:00|root.five| 53.0|
|1970-01-01T08:00:00.000+08:00| root.one| 50.0|
|1970-01-02T08:00:00.000+08:00| root.one| 50.0|
|1970-01-03T08:00:00.000+08:00| root.one| 50.0|
|1970-01-01T08:00:00.000+08:00| root.two| 50.0|
|1970-01-01T08:00:00.010+08:00| root.two| 50.0|
|1970-01-01T08:00:00.010+08:00|root.four| 32.0|
|1970-01-01T08:00:00.020+08:00|root.four| 32.0|
|1970-01-01T08:00:00.020+08:00| root.two| 10.0|
+-----------------------------+---------+-----+
当想要根据总分对结果进行排序,可以在order by子句中使用表达式进行计算
select score,total from root.one order by base+score+bonus desc
该sql等价于
select score,total from root.one order by total desc
得到如下结果
+-----------------------------+--------------+--------------+
| Time|root.one.score|root.one.total|
+-----------------------------+--------------+--------------+
|1970-01-01T08:00:00.000+08:00| 50.0| 107.0|
|1970-01-02T08:00:00.000+08:00| 50.0| 105.0|
|1970-01-03T08:00:00.000+08:00| 50.0| 103.0|
+-----------------------------+--------------+--------------+
而如果要对总分进行排序,且分数相同时依次根据score, base, bonus和提交时间进行排序时,可以通过多个表达式来指定多层排序
select base, score, bonus, total from root.** order by total desc NULLS Last,
score desc NULLS Last,
bonus desc NULLS Last,
time desc align by device
得到如下结果
+-----------------------------+----------+----+-----+-----+-----+
| Time| Device|base|score|bonus|total|
+-----------------------------+----------+----+-----+-----+-----+
|1970-01-01T08:00:00.000+08:00| root.one| 12| 50.0| 45.0|107.0|
|1970-01-02T08:00:00.000+08:00| root.one| 10| 50.0| 45.0|105.0|
|1970-01-01T08:00:00.030+08:00| root.five| 7| 53.0| 44.0|104.0|
|1970-01-03T08:00:00.000+08:00| root.one| 8| 50.0| 45.0|103.0|
|1970-01-01T08:00:00.040+08:00| root.five| 6| 54.0| 42.0|102.0|
|1970-01-01T08:00:00.010+08:00| root.four| 9| 32.0| 45.0| 86.0|
|1970-01-01T08:00:00.020+08:00| root.four| 8| 32.0| 45.0| 85.0|
|1970-01-01T08:00:00.010+08:00| root.two| 9| 50.0| 15.0| 74.0|
|1970-01-01T08:00:00.000+08:00| root.two| 9| 50.0| 15.0| 74.0|
|1970-01-01T08:00:00.020+08:00| root.two| 8| 10.0| 15.0| 33.0|
|1970-01-01T08:00:00.010+08:00|root.three| 9| null| 24.0| 33.0|
|1970-01-01T08:00:00.030+08:00|root.three| 7| null| 23.5| 30.5|
|1970-01-01T08:00:00.020+08:00|root.three| 8| null| 22.5| 30.5|
+-----------------------------+----------+----+-----+-----+-----+
在order by中同样可以使用聚合查询表达式
select min_value(total) from root.** order by min_value(total) asc align by device
得到如下结果
+----------+----------------+
| Device|min_value(total)|
+----------+----------------+
|root.three| 30.5|
| root.two| 33.0|
| root.four| 85.0|
| root.five| 102.0|
| root.one| 103.0|
+----------+----------------+
当在查询中指定多列,未被排序的列会随着行和排序列一起改变顺序,当排序列相同时行的顺序和具体实现有关(没有固定顺序)
select min_value(total),max_value(base) from root.** order by max_value(total) desc align by device
得到结果如下
·
+----------+----------------+---------------+
| Device|min_value(total)|max_value(base)|
+----------+----------------+---------------+
| root.one| 103.0| 12|
| root.five| 102.0| 7|
| root.four| 85.0| 9|
| root.two| 33.0| 9|
|root.three| 30.5| 9|
+----------+----------------+---------------+
Order by device, time可以和order by expression共同使用
select score from root.** order by device asc, score desc, time asc align by device
会得到如下结果
+-----------------------------+---------+-----+
| Time| Device|score|
+-----------------------------+---------+-----+
|1970-01-01T08:00:00.040+08:00|root.five| 54.0|
|1970-01-01T08:00:00.030+08:00|root.five| 53.0|
|1970-01-01T08:00:00.010+08:00|root.four| 32.0|
|1970-01-01T08:00:00.020+08:00|root.four| 32.0|
|1970-01-01T08:00:00.000+08:00| root.one| 50.0|
|1970-01-02T08:00:00.000+08:00| root.one| 50.0|
|1970-01-03T08:00:00.000+08:00| root.one| 50.0|
|1970-01-01T08:00:00.000+08:00| root.two| 50.0|
|1970-01-01T08:00:00.010+08:00| root.two| 50.0|
|1970-01-01T08:00:00.020+08:00| root.two| 10.0|
+-----------------------------+---------+-----+
查询对齐模式(ALIGN BY DEVICE 子句)
在 IoTDB 中,查询结果集默认按照时间对齐,包含一列时间列和若干个值列,每一行数据各列的时间戳相同。
除按照时间对齐外,还支持以下对齐模式:
- 按设备对齐
ALIGN BY DEVICE
按设备对齐
在按设备对齐模式下,设备名会单独作为一列出现,查询结果集包含一列时间列、一列设备列和若干个值列。如果 SELECT 子句中选择了 N 列,则结果集包含 N + 2 列(时间列和设备名字列)。
在默认情况下,结果集按照 Device 进行排列,在每个 Device 内按照 Time 列升序排序。
当查询多个设备时,要求设备之间同名的列数据类型相同。
为便于理解,可以按照关系模型进行对应。设备可以视为关系模型中的表,选择的列可以视为表中的列,Time + Device 看做其主键。
示例:
select * from root.ln.** where time <= 2017-11-01T00:01:00 align by device;
执行如下:
+-----------------------------+-----------------+-----------+------+--------+
| Time| Device|temperature|status|hardware|
+-----------------------------+-----------------+-----------+------+--------+
|2017-11-01T00:00:00.000+08:00|root.ln.wf01.wt01| 25.96| true| null|
|2017-11-01T00:01:00.000+08:00|root.ln.wf01.wt01| 24.36| true| null|
|1970-01-01T08:00:00.001+08:00|root.ln.wf02.wt02| null| true| v1|
|1970-01-01T08:00:00.002+08:00|root.ln.wf02.wt02| null| false| v2|
|2017-11-01T00:00:00.000+08:00|root.ln.wf02.wt02| null| true| v2|
|2017-11-01T00:01:00.000+08:00|root.ln.wf02.wt02| null| true| v2|
+-----------------------------+-----------------+-----------+------+--------+
Total line number = 6
It costs 0.012s
设备对齐模式下的排序
在设备对齐模式下,默认按照设备名的字典序升序排列,每个设备内部按照时间戳大小升序排列,可以通过 ORDER BY 子句调整设备列和时间列的排序优先级。
详细说明及示例见文档 结果集排序。
查询写回(INTO 子句)
SELECT INTO 语句用于将查询结果写入一系列指定的时间序列中。
应用场景如下:
- 实现 IoTDB 内部 ETL:对原始数据进行 ETL 处理后写入新序列。
- 查询结果存储:将查询结果进行持久化存储,起到类似物化视图的作用。
- 非对齐序列转对齐序列:对齐序列从0.13版本开始支持,可以通过该功能将非对齐序列的数据写入新的对齐序列中。
语法定义
整体描述
selectIntoStatement
: SELECT
resultColumn [, resultColumn] ...
INTO intoItem [, intoItem] ...
FROM prefixPath [, prefixPath] ...
[WHERE whereCondition]
[GROUP BY groupByTimeClause, groupByLevelClause]
[FILL {PREVIOUS | LINEAR | constant}]
[LIMIT rowLimit OFFSET rowOffset]
[ALIGN BY DEVICE]
;
intoItem
: [ALIGNED] intoDevicePath '(' intoMeasurementName [',' intoMeasurementName]* ')'
;
INTO 子句
INTO 子句由若干个 intoItem 构成。
每个 intoItem 由一个目标设备路径和一个包含若干目标物理量名的列表组成(与 INSERT 语句中的 INTO 子句写法类似)。
其中每个目标物理量名与目标设备路径组成一个目标序列,一个 intoItem 包含若干目标序列。例如:root.sg_copy.d1(s1, s2) 指定了两条目标序列 root.sg_copy.d1.s1 和 root.sg_copy.d1.s2。
INTO 子句指定的目标序列要能够与查询结果集的列一一对应。具体规则如下:
- 按时间对齐(默认):全部
intoItem包含的目标序列数量要与查询结果集的列数(除时间列外)一致,且按照表头从左到右的顺序一一对应。 - 按设备对齐(使用
ALIGN BY DEVICE):全部intoItem中指定的目标设备数和查询的设备数(即FROM子句中路径模式匹配的设备数)一致,且按照结果集设备的输出顺序一一对应。
为每个目标设备指定的目标物理量数量要与查询结果集的列数(除时间和设备列外)一致,且按照表头从左到右的顺序一一对应。
下面通过示例进一步说明:
- 示例 1(按时间对齐)
IoTDB> select s1, s2 into root.sg_copy.d1(t1), root.sg_copy.d2(t1, t2), root.sg_copy.d1(t2) from root.sg.d1, root.sg.d2;
+--------------+-------------------+--------+
| source column| target timeseries| written|
+--------------+-------------------+--------+
| root.sg.d1.s1| root.sg_copy.d1.t1| 8000|
+--------------+-------------------+--------+
| root.sg.d2.s1| root.sg_copy.d2.t1| 10000|
+--------------+-------------------+--------+
| root.sg.d1.s2| root.sg_copy.d2.t2| 12000|
+--------------+-------------------+--------+
| root.sg.d2.s2| root.sg_copy.d1.t2| 10000|
+--------------+-------------------+--------+
Total line number = 4
It costs 0.725s
该语句将 root.sg database 下四条序列的查询结果写入到 root.sg_copy database 下指定的四条序列中。注意,root.sg_copy.d2(t1, t2) 也可以写做 root.sg_copy.d2(t1), root.sg_copy.d2(t2)。
可以看到,INTO 子句的写法非常灵活,只要满足组合出的目标序列没有重复,且与查询结果列一一对应即可。
CLI展示的结果集中,各列的含义如下:
source column列表示查询结果的列名。target timeseries表示对应列写入的目标序列。written表示预期写入的数据量。
- 示例 2(按时间对齐)
IoTDB> select count(s1 + s2), last_value(s2) into root.agg.count(s1_add_s2), root.agg.last_value(s2) from root.sg.d1 group by ([0, 100), 10ms);
+--------------------------------------+-------------------------+--------+
| source column| target timeseries| written|
+--------------------------------------+-------------------------+--------+
| count(root.sg.d1.s1 + root.sg.d1.s2)| root.agg.count.s1_add_s2| 10|
+--------------------------------------+-------------------------+--------+
| last_value(root.sg.d1.s2)| root.agg.last_value.s2| 10|
+--------------------------------------+-------------------------+--------+
Total line number = 2
It costs 0.375s
该语句将聚合查询的结果存储到指定序列中。
- 示例 3(按设备对齐)
IoTDB> select s1, s2 into root.sg_copy.d1(t1, t2), root.sg_copy.d2(t1, t2) from root.sg.d1, root.sg.d2 align by device;
+--------------+--------------+-------------------+--------+
| source device| source column| target timeseries| written|
+--------------+--------------+-------------------+--------+
| root.sg.d1| s1| root.sg_copy.d1.t1| 8000|
+--------------+--------------+-------------------+--------+
| root.sg.d1| s2| root.sg_copy.d1.t2| 11000|
+--------------+--------------+-------------------+--------+
| root.sg.d2| s1| root.sg_copy.d2.t1| 12000|
+--------------+--------------+-------------------+--------+
| root.sg.d2| s2| root.sg_copy.d2.t2| 9000|
+--------------+--------------+-------------------+--------+
Total line number = 4
It costs 0.625s
该语句同样是将 root.sg database 下四条序列的查询结果写入到 root.sg_copy database 下指定的四条序列中。但在按设备对齐中,intoItem 的数量必须和查询的设备数量一致,每个查询设备对应一个 intoItem。
按设备对齐查询时,
CLI展示的结果集多出一列source device列表示查询的设备。
- 示例 4(按设备对齐)
IoTDB> select s1 + s2 into root.expr.add(d1s1_d1s2), root.expr.add(d2s1_d2s2) from root.sg.d1, root.sg.d2 align by device;
+--------------+--------------+------------------------+--------+
| source device| source column| target timeseries| written|
+--------------+--------------+------------------------+--------+
| root.sg.d1| s1 + s2| root.expr.add.d1s1_d1s2| 10000|
+--------------+--------------+------------------------+--------+
| root.sg.d2| s1 + s2| root.expr.add.d2s1_d2s2| 10000|
+--------------+--------------+------------------------+--------+
Total line number = 2
It costs 0.532s
该语句将表达式计算的结果存储到指定序列中。
使用变量占位符
特别地,可以使用变量占位符描述目标序列与查询序列之间的对应规律,简化语句书写。目前支持以下两种变量占位符:
- 后缀复制符
:::复制查询设备后缀(或物理量),表示从该层开始一直到设备的最后一层(或物理量),目标设备的节点名(或物理量名)与查询的设备对应的节点名(或物理量名)相同。 - 单层节点匹配符
${i}:表示目标序列当前层节点名与查询序列的第i层节点名相同。比如,对于路径root.sg1.d1.s1而言,${1}表示sg1,${2}表示d1,${3}表示s1。
在使用变量占位符时,intoItem与查询结果集列的对应关系不能存在歧义,具体情况分类讨论如下:
按时间对齐(默认)
注:变量占位符只能描述序列与序列之间的对应关系,如果查询中包含聚合、表达式计算,此时查询结果中的列无法与某个序列对应,因此目标设备和目标物理量都不能使用变量占位符。
(1)目标设备不使用变量占位符 & 目标物理量列表使用变量占位符
限制:
- 每个
intoItem中,物理量列表的长度必须为 1。
(如果长度可以大于1,例如root.sg1.d1(::, s1),无法确定具体哪些列与::匹配) intoItem数量为 1,或与查询结果集列数一致。
(在每个目标物理量列表长度均为 1 的情况下,若intoItem只有 1 个,此时表示全部查询序列写入相同设备;若intoItem数量与查询序列一致,则表示为每个查询序列指定一个目标设备;若intoItem大于 1 小于查询序列数,此时无法与查询序列一一对应)
匹配方法: 每个查询序列指定目标设备,而目标物理量根据变量占位符生成。
示例:
select s1, s2
into root.sg_copy.d1(::), root.sg_copy.d2(s1), root.sg_copy.d1(${3}), root.sg_copy.d2(::)
from root.sg.d1, root.sg.d2;
该语句等价于:
select s1, s2
into root.sg_copy.d1(s1), root.sg_copy.d2(s1), root.sg_copy.d1(s2), root.sg_copy.d2(s2)
from root.sg.d1, root.sg.d2;
可以看到,在这种情况下,语句并不能得到很好地简化。
(2)目标设备使用变量占位符 & 目标物理量列表不使用变量占位符
限制: 全部 intoItem 中目标物理量的数量与查询结果集列数一致。
匹配方式: 为每个查询序列指定了目标物理量,目标设备根据对应目标物理量所在 intoItem 的目标设备占位符生成。
示例:
select d1.s1, d1.s2, d2.s3, d3.s4
into ::(s1_1, s2_2), root.sg.d2_2(s3_3), root.${2}_copy.::(s4)
from root.sg;
(3)目标设备使用变量占位符 & 目标物理量列表使用变量占位符
限制: intoItem 只有一个且物理量列表的长度为 1。
匹配方式: 每个查询序列根据变量占位符可以得到一个目标序列。
示例:
select * into root.sg_bk.::(::) from root.sg.**;
将 root.sg 下全部序列的查询结果写到 root.sg_bk,设备名后缀和物理量名保持不变。
按设备对齐(使用 ALIGN BY DEVICE)
注:变量占位符只能描述序列与序列之间的对应关系,如果查询中包含聚合、表达式计算,此时查询结果中的列无法与某个物理量对应,因此目标物理量不能使用变量占位符。
(1)目标设备不使用变量占位符 & 目标物理量列表使用变量占位符
限制: 每个 intoItem 中,如果物理量列表使用了变量占位符,则列表的长度必须为 1。
匹配方法: 每个查询序列指定目标设备,而目标物理量根据变量占位符生成。
示例:
select s1, s2, s3, s4
into root.backup_sg.d1(s1, s2, s3, s4), root.backup_sg.d2(::), root.sg.d3(backup_${4})
from root.sg.d1, root.sg.d2, root.sg.d3
align by device;
(2)目标设备使用变量占位符 & 目标物理量列表不使用变量占位符
限制: intoItem 只有一个。(如果出现多个带占位符的 intoItem,我们将无法得知每个 intoItem 需要匹配哪几个源设备)
匹配方式: 每个查询设备根据变量占位符得到一个目标设备,每个设备下结果集各列写入的目标物理量由目标物理量列表指定。
示例:
select avg(s1), sum(s2) + sum(s3), count(s4)
into root.agg_${2}.::(avg_s1, sum_s2_add_s3, count_s4)
from root.**
align by device;
(3)目标设备使用变量占位符 & 目标物理量列表使用变量占位符
限制: intoItem 只有一个且物理量列表的长度为 1。
匹配方式: 每个查询序列根据变量占位符可以得到一个目标序列。
示例:
select * into ::(backup_${4}) from root.sg.** align by device;
将 root.sg 下每条序列的查询结果写到相同设备下,物理量名前加backup_。
指定目标序列为对齐序列
通过 ALIGNED 关键词可以指定写入的目标设备为对齐写入,每个 intoItem 可以独立设置。
示例:
select s1, s2 into root.sg_copy.d1(t1, t2), aligned root.sg_copy.d2(t1, t2) from root.sg.d1, root.sg.d2 align by device;
该语句指定了 root.sg_copy.d1 是非对齐设备,root.sg_copy.d2是对齐设备。
不支持使用的查询子句
SLIMIT、SOFFSET:查询出来的列不确定,功能不清晰,因此不支持。LAST查询、GROUP BY TAGS、DISABLE ALIGN:表结构和写入结构不一致,因此不支持。
其他要注意的点
- 对于一般的聚合查询,时间戳是无意义的,约定使用 0 来存储。
- 当目标序列存在时,需要保证源序列和目标时间序列的数据类型兼容。关于数据类型的兼容性,查看文档 数据类型。
- 当目标序列不存在时,系统将自动创建目标序列(包括 database)。
- 当查询的序列不存在或查询的序列不存在数据,则不会自动创建目标序列。
应用举例
实现 IoTDB 内部 ETL
对原始数据进行 ETL 处理后写入新序列。
IOTDB > SELECT preprocess_udf(s1, s2) INTO ::(preprocessed_s1, preprocessed_s2) FROM root.sg.* ALIGN BY DEIVCE;
+--------------+-------------------+---------------------------+--------+
| source device| source column| target timeseries| written|
+--------------+-------------------+---------------------------+--------+
| root.sg.d1| preprocess_udf(s1)| root.sg.d1.preprocessed_s1| 8000|
+--------------+-------------------+---------------------------+--------+
| root.sg.d1| preprocess_udf(s2)| root.sg.d1.preprocessed_s2| 10000|
+--------------+-------------------+---------------------------+--------+
| root.sg.d2| preprocess_udf(s1)| root.sg.d2.preprocessed_s1| 11000|
+--------------+-------------------+---------------------------+--------+
| root.sg.d2| preprocess_udf(s2)| root.sg.d2.preprocessed_s2| 9000|
+--------------+-------------------+---------------------------+--------+
以上语句使用自定义函数对数据进行预处理,将预处理后的结果持久化存储到新序列中。
查询结果存储
将查询结果进行持久化存储,起到类似物化视图的作用。
IOTDB > SELECT count(s1), last_value(s1) INTO root.sg.agg_${2}(count_s1, last_value_s1) FROM root.sg1.d1 GROUP BY ([0, 10000), 10ms);
+--------------------------+-----------------------------+--------+
| source column| target timeseries| written|
+--------------------------+-----------------------------+--------+
| count(root.sg.d1.s1)| root.sg.agg_d1.count_s1| 1000|
+--------------------------+-----------------------------+--------+
| last_value(root.sg.d1.s2)| root.sg.agg_d1.last_value_s2| 1000|
+--------------------------+-----------------------------+--------+
Total line number = 2
It costs 0.115s
以上语句将降采样查询的结果持久化存储到新序列中。
非对齐序列转对齐序列
对齐序列从 0.13 版本开始支持,可以通过该功能将非对齐序列的数据写入新的对齐序列中。
注意: 建议配合使用 LIMIT & OFFSET 子句或 WHERE 子句(时间过滤条件)对数据进行分批,防止单次操作的数据量过大。
IOTDB > SELECT s1, s2 INTO ALIGNED root.sg1.aligned_d(s1, s2) FROM root.sg1.non_aligned_d WHERE time >= 0 and time < 10000;
+--------------------------+----------------------+--------+
| source column| target timeseries| written|
+--------------------------+----------------------+--------+
| root.sg1.non_aligned_d.s1| root.sg1.aligned_d.s1| 10000|
+--------------------------+----------------------+--------+
| root.sg1.non_aligned_d.s2| root.sg1.aligned_d.s2| 10000|
+--------------------------+----------------------+--------+
Total line number = 2
It costs 0.375s
以上语句将一组非对齐的序列的数据迁移到一组对齐序列。
相关用户权限
用户必须有下列权限才能正常执行查询写回语句:
- 所有
SELECT子句中源序列的WRITE_SCHEMA权限。 - 所有
INTO子句中目标序列WRITE_DATA权限。
更多用户权限相关的内容,请参考权限管理语句。
相关配置参数
select_into_insert_tablet_plan_row_limit参数名 select_into_insert_tablet_plan_row_limit 描述 写入过程中每一批 Tablet的最大行数类型 int32 默认值 10000 改后生效方式 重启后生效