

在工业级时序预测场景中,精准的趋势研判往往是业务决策的重要依据。然而,传统单变量预测模式很难完整描述真实系统中的复杂关系。
例如在电力系统中,电价不仅与历史价格序列相关,还受到温度、风速、节假日以及能源结构等多种因素影响。在制造、交通和能源等领域,类似的多变量耦合关系普遍存在。
因此,随着时序数据规模与复杂度的持续提升,预测能力正在从单一算法问题,逐渐演变为数据系统与模型能力协同的问题。
在基于时序数据库 IoTDB 开发的企业级产品 TimechoDB 2.0.8 中,我们重点完成了 AINode 智能分析节点的能力升级,使数据库能够直接支持 Transformer 架构时序模型的部署与推理,并提供协变量预测任务框架。
这意味着企业可以在数据库内部集成不同类型的时序基础模型,实现从数据管理到预测分析的一体化运行。
01 什么是协变量与协变量预测?
想要更好地理解协变量预测能力,需要先厘清两个基本概念。
协变量
协变量是指与待预测目标变量高度相关、能够为预测提供参考信息的关联变量。例如在电价预测场景中,温度、风速、是否节假日等因素都会对电价波动产生影响,因此都可以作为协变量参与建模。
协变量预测
区别于传统单变量预测模式,协变量预测通过融合目标变量历史数据、协变量历史数据以及部分已知的未来协变量信息,对未来趋势进行联合建模。
在这种预测方式中,模型不再只依赖单一时间序列,而是通过多维数据之间的动态关系进行推理,从而更好地反映真实业务系统的运行规律。
借助协变量信息,预测模型能够突破单一数据维度的限制,使预测结果更加贴近真实场景,在许多工业应用中能够显著提升预测精度与稳定性。
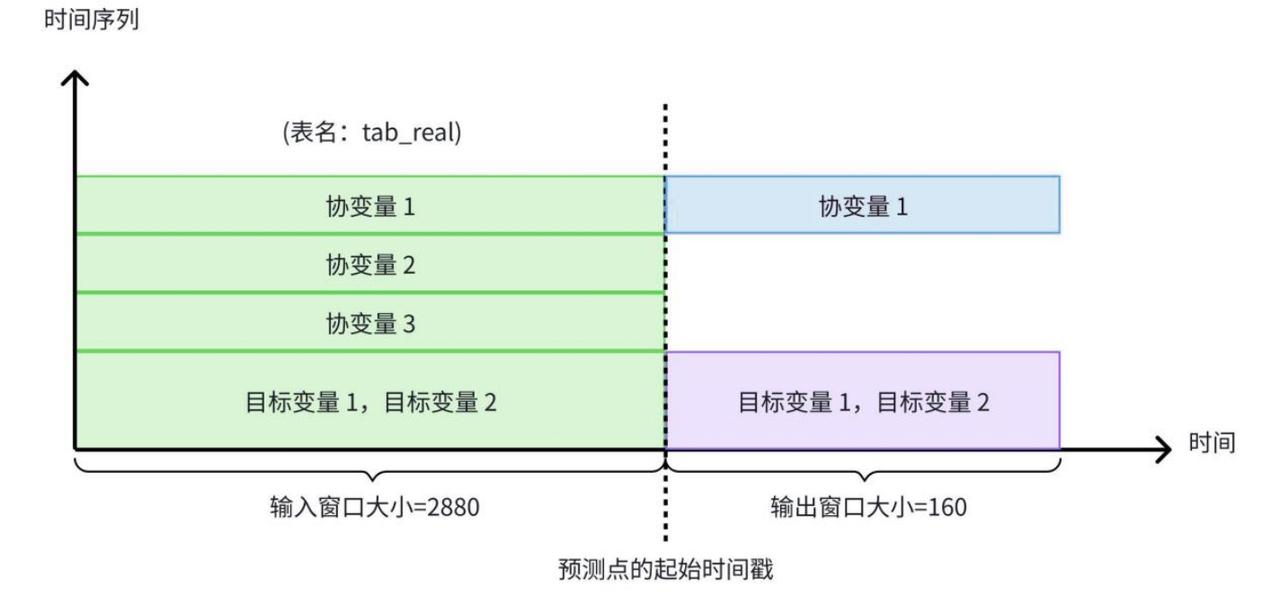
协变量预测任务结构示意图:使用目标变量 1~2 的历史数据、协变量 1~3 的历史数据、协变量 1 的未来数据(绿色数据),预测目标变量 1 、2(紫色数据)
02 AINode:数据库原生智能分析节点
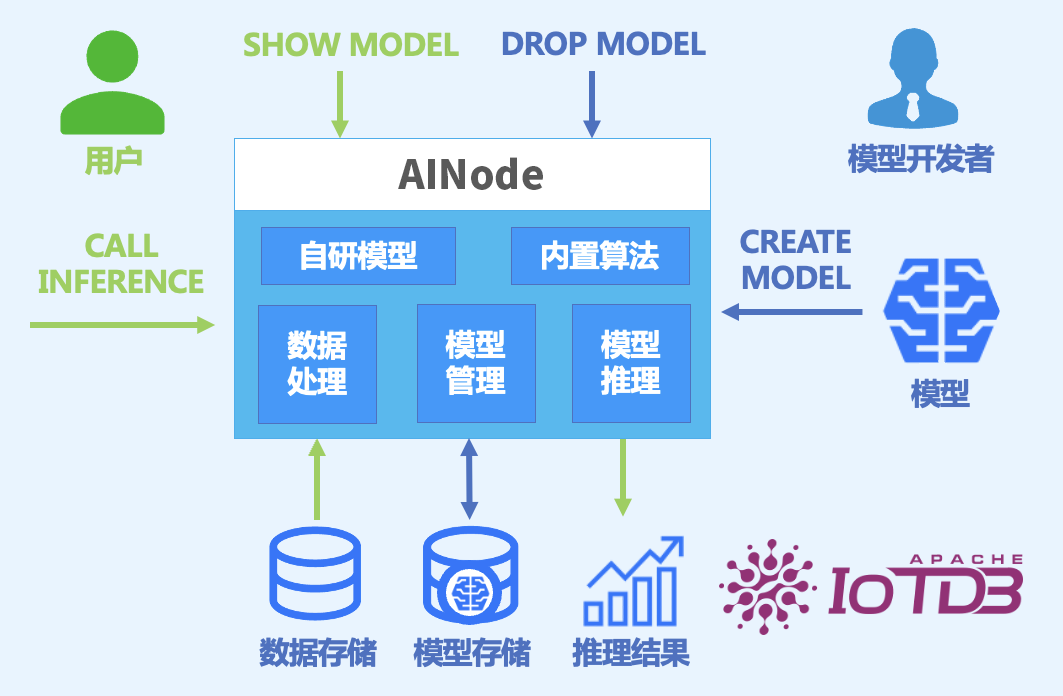
为了让预测能力更好地融入数据系统,TimechoDB 在 2.0.8 版本中重点升级了 AINode(AI Node)智能分析节点。
AINode 的目标是让数据库不仅能够管理数据,也能够承担模型部署与推理任务,使预测分析能力可以直接在数据库体系内运行。
在这一版本中,AINode 提供了统一的模型接入机制,使数据库能够部署不同类型的 Transformer 架构时序模型,例如 Timer 系列模型、Chronos 系列模型以及 Moirai 等开源时序基础模型,也包括企业自定义训练的预测模型。
模型训练过程可在数据库外完成,以便进行灵活的自定义调整;而模型部署、推理执行以及任务调度则由数据库统一管理。
通过这种方式,预测任务可以直接在数据库内部完成数据读取、模型调用以及结果生成,从而避免传统预测流程中频繁的数据导出和系统切换。
这种架构也使数据库逐渐从单纯的数据管理系统,向能够支持数据与智能协同运行的基础设施演进。
03 SQL 原生预测调用
在许多预测工具中,协变量通常需要以参数形式手动传入,例如在 SQL 中逐个填写协变量数值或通过字符串拼接输入。这种方式不仅操作流程繁琐,也容易因为参数输入错误而导致预测任务失败。
TimechoDB 对协变量输入逻辑进行了优化,支持通过 SQL 直接查询数据库中的数据作为协变量输入,使预测任务能够自然融入用户日常的数据查询流程。
一个典型的协变量预测调用示例如下:
SELECT*FROM FORECAST (
MODEL_ID =>'chronos2',
TARGETS => (-- 目标变量
SELECT TIME, target1, target2
FROM etth.tab_real
WHERE TIME < 7 ORDER BY TIME DESC)
ORDER BY TIME LIMIT 6,
HISTORY_COVS => '
SELECT TIME, cov1, cov2, cov3
FROM etth.tab_real
WHERE TIME < 7 ORDER BY TIME DESC
LIMIT 6',-- 历史协变量
FUTURE_COVS => '
SELECT TIME, cov1 FROM etth.tab_real
WHERE TIME >= 7 LIMIT 2',-- 未来协变量
OUTPUT_LENGTH => 2
)通过这种方式,目标变量与协变量数据都可以直接来自数据库查询结果,无需手动拼接输入参数,使预测任务的使用门槛大幅降低。
04 协变量预测的工业级实践
协变量预测能力不仅是理论模型能力,在真实工业场景中同样具有重要价值。
在真实电价预测任务中,我们对协变量预测方案进行了实际落地验证。该场景需要对未来电价走势进行趋势预测,而电价变化往往受到多种因素共同影响,例如气象条件、时间因素以及能源供给结构等,且极端电价趋势往往难以预测。
在实际建模过程中,业务方最初筛选出超过 100 个潜在相关协变量,经过多轮数据清洗与特征筛选,最终确定 20 余个核心协变量。这些变量大致可以分为三个类别:
时间相关变量,例如日期、星期以及节假日等;
气象相关变量,例如温度、风速、降水量和云量等;
能源相关变量,例如太阳能发电量、风电出力以及能源转化效率等。
在预测过程中,模型同时输入目标变量(电价)以及所有协变量过去 2880 个时间点(约 30 天) 的历史数据,并结合未来 160 个时间点(约 40 小时) 的已知协变量信息进行预测。
在该场景中,我们基于开源时序基础模型,自研协变量增强预测方案,并与多种基础模型进行了对比实验。
结果表明,在复杂多变量场景下,引入协变量建模能力后,预测曲线能够更准确地捕捉真实趋势变化,在峰值预测、趋势跟踪以及整体稳定性方面均优于单一基础模型。
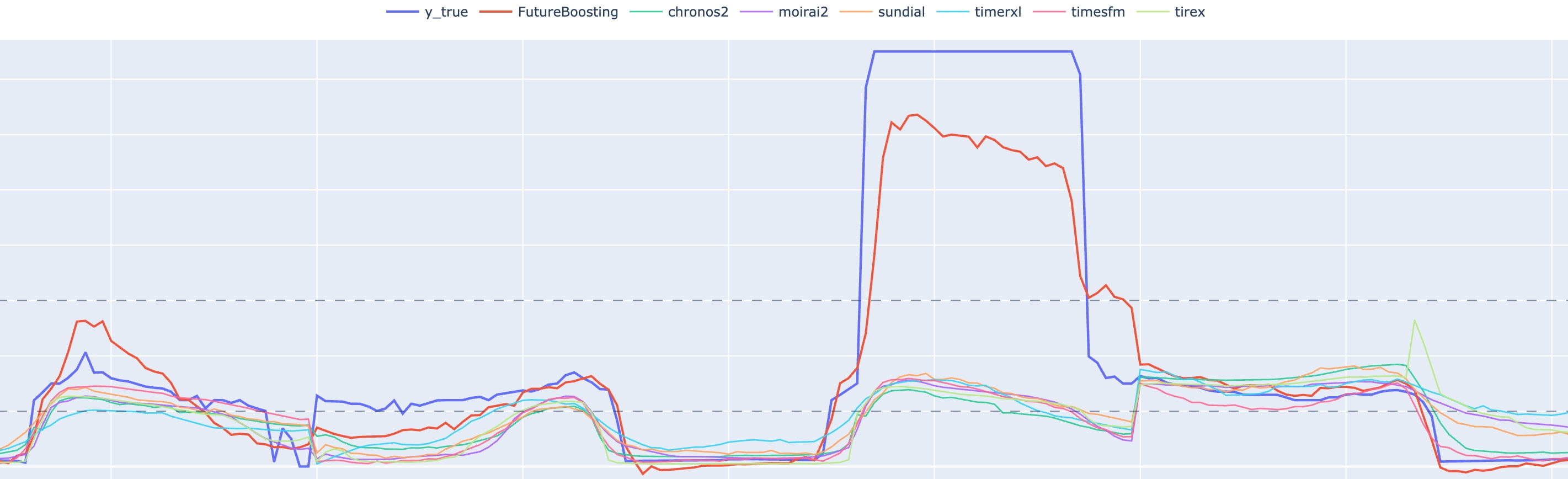
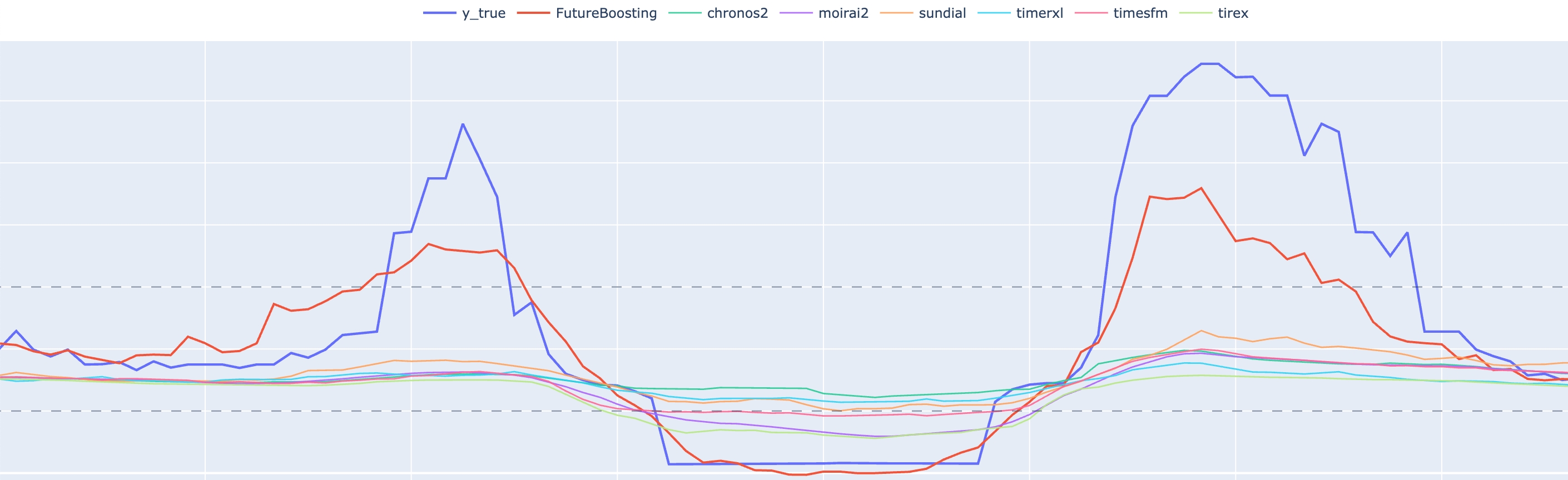
多模型预测结果对比:协变量增强模型(FutureBoosting)在关键趋势变化处能够更准确地贴近真实序列
05 总结
在 TimechoDB 2.0.8 中,我们重点完成了 AINode 能力升级,使数据库能够支持 Transformer 架构时序模型的部署与推理,并提供协变量预测任务框架。
通过这一机制,企业可以在数据库内部统一管理模型部署、预测任务调度以及数据访问,实现从数据管理到智能分析的一体化运行。
从数据管理到智能分析,数据库正在逐渐演变为时序 AI 应用的重要基础设施。随着时序基础模型能力的持续演进,数据库与模型的协同运行也将成为未来时序数据系统的重要发展方向。
更多内容推荐:
• 下载时序数据库 IoTDB 开源版
• 咨询TimechoDB


