

运维工作中有大量重复的模式:登录服务器、看日志、查资源、定位问题、写修复方案。这些操作本身不难,但需要经验来决定“下一步该查什么”,需要耐心来逐条翻阅日志,需要细心来确保方案不遗漏。
如果有一个助手,你只需要告诉它“服务挂了,查一下原因”,它就能自己 SSH 上去翻日志、查系统状态、逐层排查,最后给你一个根因分析和修复方案——这就是本文要介绍的工作模式。
本文以 Claude Code 为例,介绍如何用本地 AI Agent 进行远程服务器运维。前半部分是方法论和教程,后半部分附一个完整的时序数据库 IoTDB 运维真实案例。
01 基本原理
AI Agent 运行在你的本地机器上。它没有什么魔法,只是通过 SSH 在远程服务器上执行命令,然后阅读输出、分析结果、决定下一步该做什么。
你的描述 → AI Agent(本地) → ssh remote "命令" → 远程服务器
↑ |
└── 分析输出,决定下一步 ←─┘它和人类工程师做的事情一样,只是:
不会遗漏:它会系统性地检查每一个可能的方向;
并行执行:无依赖的检查命令同时发出,不用一条一条等;
不会疲劳:翻几百行日志对它来说和翻十行一样。
02 前置准备
(1) 安装 Claude Code
确保本地已安装 Claude Code CLI。
(2) 配置 SSH 免密登录
这是最关键的前提。Agent 通过 SSH 执行远程命令,如果每次都需要输入密码,它就无法自主工作。
你只需要告诉 Agent 三个信息:远程服务器的 IP 和用户名、你要用哪个本地密钥、你希望在 SSH Config 中给它取什么别名。然后 Agent 会自动完成配置。
Agent 会自动读取你现有的 SSH Config、检查密钥文件、编辑配置文件。唯一需要你手动做的是执行一次公钥部署命令(因为首次连接需要输入密码)。
(3) 权限边界
有一个重要的问题:Agent 能做什么,不能做什么?
Agent 以你配置的 SSH 用户身份登录远程服务器。它能做的事情取决于该用户的权限。
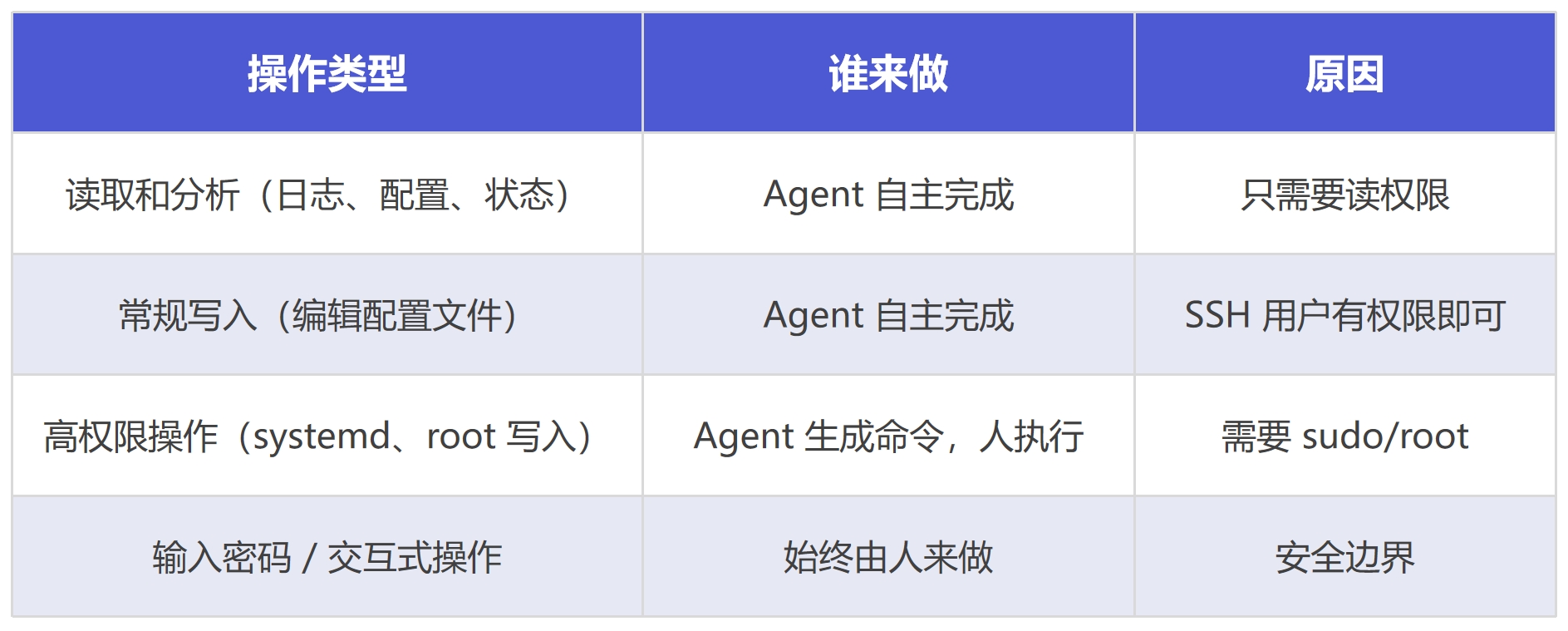
这不是 Agent 的缺陷,而是合理的安全设计。
03 使用方式
(1) 排查问题
你只需要用自然语言描述问题,不需要指定任何具体命令。
“xxx 服务器上的数据库挂了,查一下原因”,Agent 会自行决定排查策略。
典型的排查流程是分层推进的:

每一层的结果会决定是否需要进入下一层。Agent 不是机械地跑完所有命令,而是根据分析结果动态调整方向。
(2) 执行变更
对于修复方案,你同样只需要描述目标:“给这个服务配置开机自启动”。
Agent 会自动收集信息(启动脚本、进程参数、安装路径),设计方案(技术选型、依赖关系),生成完整可执行的命令(一次复制就能跑)。
(3) 多轮对话
Agent 的上下文是连续的。你可以先让它排查问题,再基于排查结果让它修复——它会记住之前发现的所有信息,不需要你重复说明。
(4) 适用与不适用场景

04 实战案例:IoTDB 服务异常排查与修复
以下是一次真实的运维操作记录,展示了从配置 SSH 访问到排查问题到最终修复的完整过程。
背景
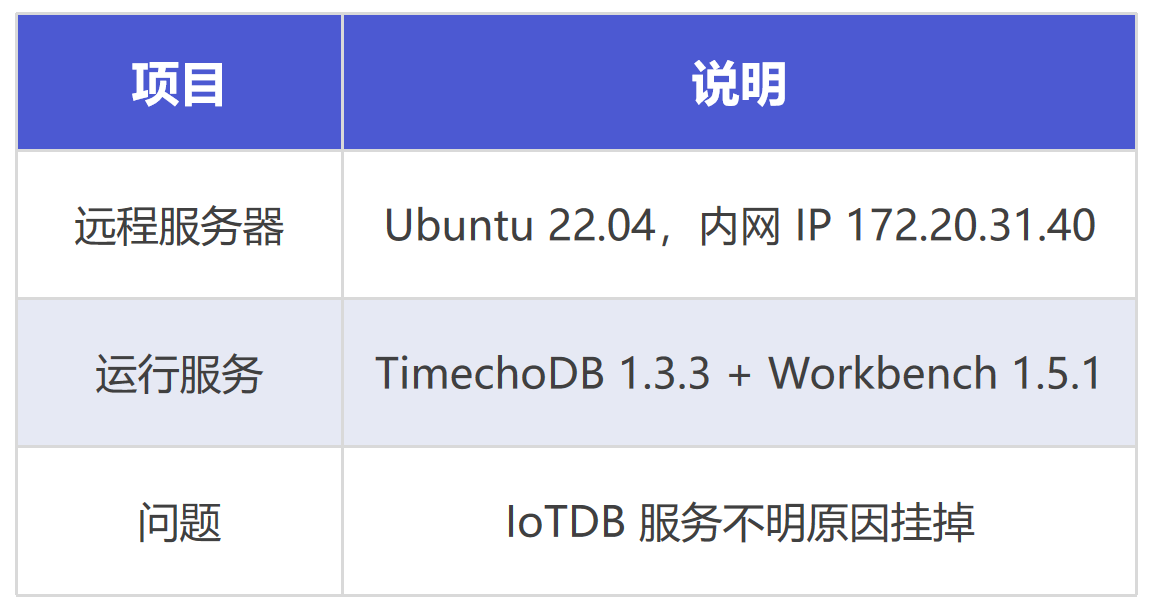
阶段一:配置 SSH 访问
🧒🏻人的输入:在 ~/.ssh/config 中配置 timecho-iotdb,其 IP 为 172.20.31.40,用户名为 ubuntu,设置基于本地的 ~/.ssh/id_bolt.pub 来免密登录。
仅此一句话,没有给出任何具体命令。
🤖Agent 自主完成:
读取 ~/.ssh/config,了解现有配置风格;
执行 ls ~/.ssh/id_bolt*,确认密钥文件存在;
编辑 SSH Config,追加 Host 配置(保持与现有条目一致的缩进风格);
生成一条公钥部署命令,交给人执行。
📌人工介入:仅一处 —— 执行公钥部署命令并输入密码。
阶段二:排查服务异常
🧒🏻人的输入:timecho-iotdb 机器上安装了 IoTDB,但是自己死了。排查原因。
仅此一句。人没有指定查什么日志、看什么文件、用什么命令。以下所有步骤均由 Agent 自行决策和执行,全程零人工干预。
第 1 轮:进程 + 日志(3 条命令并行)
Agent 自行决定同时检查进程状态、DataNode 日志、ConfigNode 日志。
ssh timecho-iotdb "ps aux | grep -i iotdb | grep -v grep"
ssh timecho-iotdb "tail -200 .../logs/log_datanode_all.log"
ssh timecho-iotdb "tail -200 .../logs/log_confignode_all.log"🤖Agent 分析:进程存在但刚启动于 11:55,说明之前确实挂过。需要查上一次崩溃的原因。
第 2 轮:错误日志 + OOM + JVM Crash(4 条命令并行)
基于上一轮结果,Agent 自行决定从多个方向排查崩溃原因。
ssh timecho-iotdb "cat .../logs/log_datanode_error.log"
ssh timecho-iotdb "cat .../logs/log_confignode_error.log"
ssh timecho-iotdb "dmesg -T | grep -i 'oom|kill|out of memory'"
ssh timecho-iotdb "find ... -name 'hs_err*'"🤖Agent 分析:ShutdownHook 报错“Fail to connect to any config node”—— 是被外力强杀的。无 OOM,无 JVM crash dump。排除服务自身问题。
第 3 轮:历史日志 + 系统资源(2 条命令并行)
ssh timecho-iotdb "zcat .../log-datanode-all-20260413.log.gz | tail -100"
ssh timecho-iotdb "free -h && df -h /data"🤖Agent 分析:内存 16G 空闲 13G,磁盘 492G 用了 17G,资源充裕。日志在 4 月 13 日正常运行后突然中断。
第 4 轮:系统重启记录(3 条命令并行)
ssh timecho-iotdb "last reboot | head -10"
ssh timecho-iotdb "uptime"
ssh timecho-iotdb "last -x | head -20"🤖Agent 分析:确认服务器在 2026-04-13 12:38 重启。IoTDB 最后日志在 12:34。
第 5 轮:追查重启原因(2 条命令并行)
ssh timecho-iotdb "journalctl -b -1 --no-pager | tail -50"
ssh timecho-iotdb "ls /var/log/unattended-upgrades/"🔍Agent 最终结论:IoTDB 不是自己崩溃的。journalctl 日志在重启前突然中断,无 shutdown 命令、无 kernel panic、无自动更新。主机名 i-lcmcddxs 是云平台实例 ID,判定为云平台宿主机维护导致虚拟机被强制重启。建议配置 systemd 自启动。
📌人工介入:零。从第一条命令到最终结论,人没有执行任何操作。
阶段三:配置自启动
🧒🏻人的输入:给 IoTDB 配置自启动。做一个升级标记。可视化控制台 Workbench 也要自启动。
三个要求,一句话,没有指定用什么技术方案。
🤖Agent 自主完成:
查看启动脚本内容,了解启动方式;
执行 find 定位 Workbench 安装路径(无人工介入);
从 /proc/pid/cmdline 提取 Workbench 完整启动参数;
设计依赖链:ConfigNode → DataNode(等 15 秒)→ Workbench;
生成 3 个 systemd service 文件,顶部写升级提醒注释;
生成升级标记文件 SYSTEMD_SERVICES_README.md;
生成 daemon-reload + enable 命令。
📌人工介入:仅一处 —— 以 root 身份执行 Agent 生成的命令。
案例小结
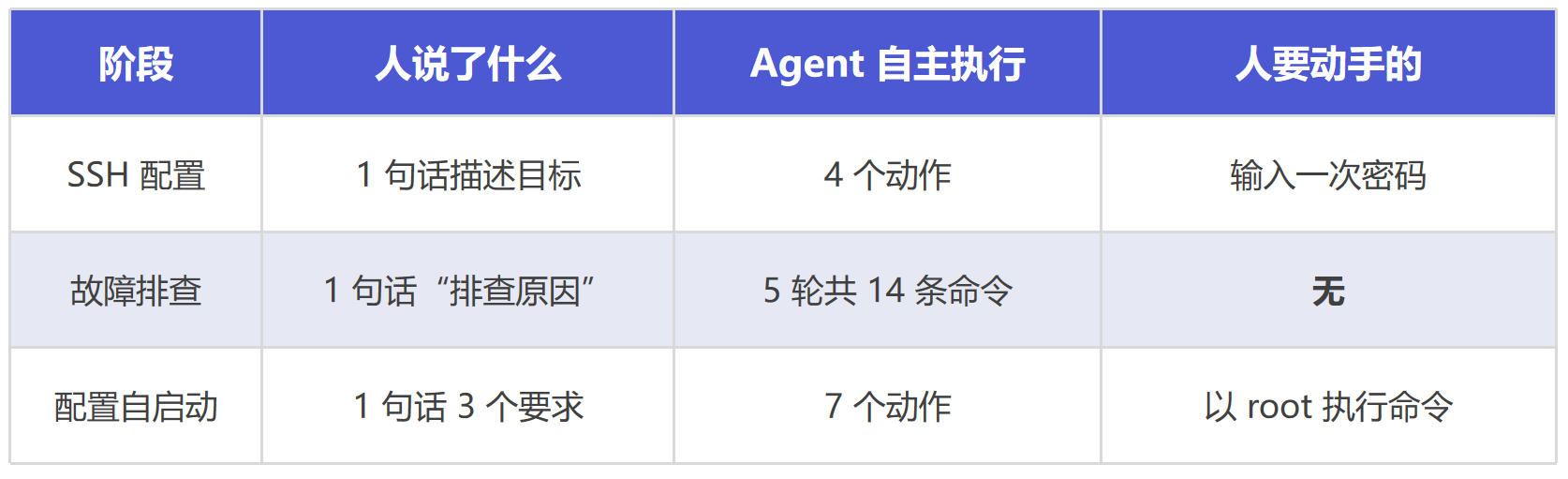
整个过程中,人总共说了 3 句话。Agent 自主执行了 20+ 条远程命令,完成了从故障定位到修复方案的全流程。人工介入仅发生在需要密码输入和 root 权限的环节。
更多内容推荐:
• 下载开源时序数据库 IoTDB
• 咨询 TimechoDB


