

12 月 3 日、4日,2022 Apache IoTDB 物联网生态大会在线上圆满落幕。大会上发布 Apache IoTDB 的分布式 1.0 版本,并分享 Apache IoTDB 实现的数据管理技术与物联网场景实践案例,深入探讨了 Apache IoTDB 与物联网企业如何共建活跃生态,企业如何与开源社区紧密配合,实现共赢。
我们邀请到东方国信分布式数据库事业部时序数据库负责人,Apache IoTDB PMC 王超参加此次大会,并做主题演讲——《Apache IoTDB 在东方国信的商业化及应用》。以下为内容全文。
大家好,我是来自东方国信的王超,下面由我来给大家分享一下 Apache IoTDB 在东方国信的商业化及应用。
我的分享内容主要有五个部分,第一部分的话是简单介绍一下我们公司。第二部分的话是介绍一下我们基于 Apache IoTDB 打造的时序数据库 CirroData-TimeS。第三部分介绍一下我们在社区的一些工作。第四部分介绍一下我们使用时序数据库的一些案例。第五部分分享一下我们对开源、商业还有公益的一些理解。
01 公司简介
下面我先来简单介绍一下我们公司。我们公司全称是北京东方国信科技股份有限公司,它是成立于 1997 年,并于 2011 年成功上市。目前的话有 18 个全资子公司,业务范围覆盖了全球 46 个国家和地区。当前在全国 31 个省都有分支机构,有近万人的研发和服务团队。
东方国信是一个大数据服务提供商,以大数据+布局的多个行业,它涉及到通信、工业、城市、金融、公共安全、旅游、媒体、医疗、农业和保险等 10 个行业。再来简单介绍一下我自己,目前的话我是在东方国信的分布式数据库事业部担任时序数据库负责人。目前也是 Apache IoTDB 社区的 PMC 成员。

02 东方国信时序数据库 CirroData-TimeS
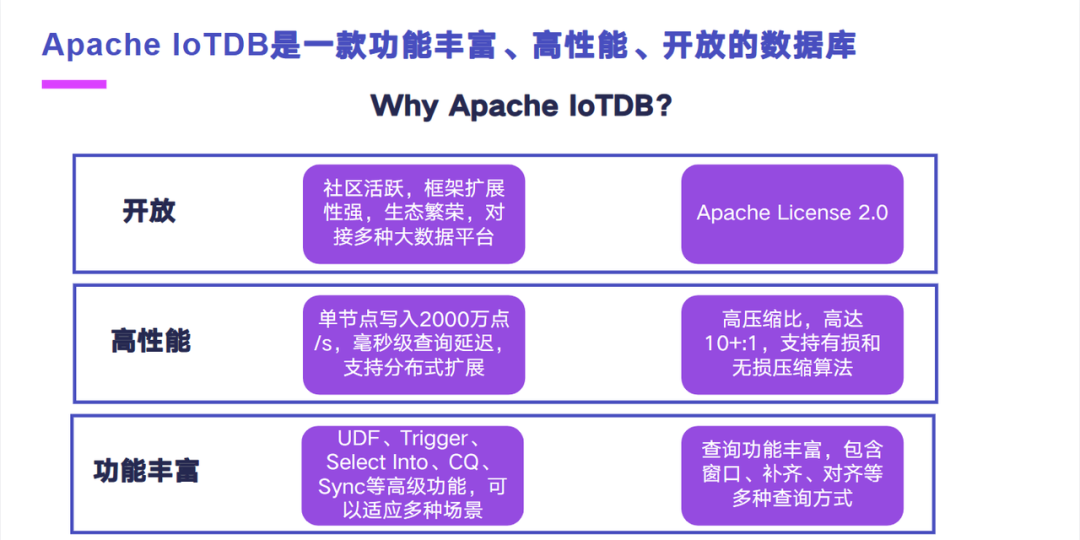
好,接下来我来介绍一下我们基于 Apache IoTDB 打造的商业化时序数据库 CirroData-TimeS。在介绍我们时序数据库之前,我先来分享一下我们为什么会使用 Apache IoTDB。这个是因为经过一些调研,对比分析市面上的一些开源数据库,我们发现 Apache IoTDB 相对于其他的开源时序数据库具有典型的三个特征,第一,开放,第二,高性能,第三,功能丰富,能满足我们绝大部分的场景。开放主要体现在两个方面,第一,社区开放。第二,license 开放。社区开放主要体现在它的社区非常活跃,而且社区对新人或者是新的开发者都比较友好,代码框架灵活性比较高,扩展性强,生态比较繁荣,能对接很多大数据平台。license 开放这一块是因为 Apache IoTDB 采用的是 Apache License 2.0 的软件许可,这个对于商业化来说是非常友好的。
高性能这一块的话主要体现在两个方面。第一块的话是它的读写高性能,第二块的话是它的压缩低成本。读写高性能这一块主要是体现在以写入单节点能达到 2000 万点每秒,查询的延迟的话是毫秒级别的,并且支持分布式的性能扩展。在压缩这一块具有比较高的压缩比,高达 10 比 1 的压缩比,支持多种无损和有损的压缩算法。
功能丰富这一块体现在两方面,第一方面的话是它的高级功能比较丰富,第二块的话是查询功能比较丰富。高级功能丰富这一块体现在它支持用户自定义函数,触发器写回,连续查询,云边同步等多种功能,能支持多种业务场景。查询丰富这一块体现在它包含多种查询方式,包括时间窗口,对齐,补齐等等。
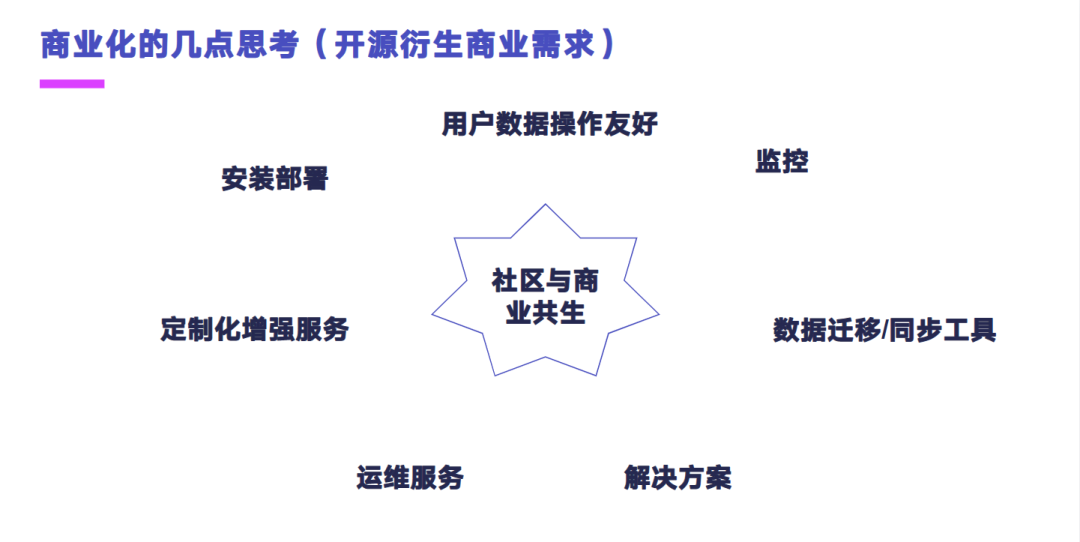
好,再来介绍一下我们基于 Apache IoTDB 做的商业化的一些思考。为什么我们会打造自己的商业化版本呢?主要的还是因为有一些客户需求推动了,客户的需求主要有四点。第一点是有的公司它会有自己定制化的这种需求,并不是特别通用的。而数据库他作为一个通用型的软件的话,它一般会考虑比较通用性的需求,因此这些公司的话可能它需要一些商业化定制的一些需求支持。第二就是不同的公司他的节奏是不一样的,比如它的业务可能发展得比较快,而社区的节奏的话可能跟不上他业务的发展,这个时候他的公司可能就需要有一些快速开发的需求。第三块是有的公司他需要一整套的解决方案,而不只是一款数据库,因此需要商业化集成的一些支持。第四个是有一些公司他对系统的运行状态要求比较高,但他又不是系统的开发者,因此需要比较专业的运维服务支持的能力。基于上面四类的需求,我们决定打造商业化的版本。
基于商业化的版本的话,我们做了七点增强。覆盖主要是体现在第一,安装部署这方面,做到可视化的一键部署,对于运维来说是非常友好的。第二块的话是用户操作方面比较友好,用户不需要熟悉 SQL 语句就能做数据的查询分析。第三块的话是监控,能够看到系统的运营状态,还有系统的数据情况。第四块的话是数据同步和迁移的工具,这个主要是从一些旧的系统里面把数据迁移到新版的时序库里面来。第五块的话是一整套解决方案,联合我们公司内部的一些产品打造一整套解决方案,用来满足用户的业务需求。第六块的话是运维服务,这一块我们可以提供相对专业的运维服务,我们公司在全国 31 个省都有分支结构,可以提供比较全面的运维知识。第七块的话是能做一些定制化的增强服务。
下面我来介绍一下我们基于以上几点思考的话做的一些功能增强。第一块的话是可视化的集群管理工具,主要是用来做一些集群的一些管理,比如包括集群或者单机的一键安装部署,还有配置的可视化的调整,扩缩容,节点状态检测,升级回滚,版本源管理等等。

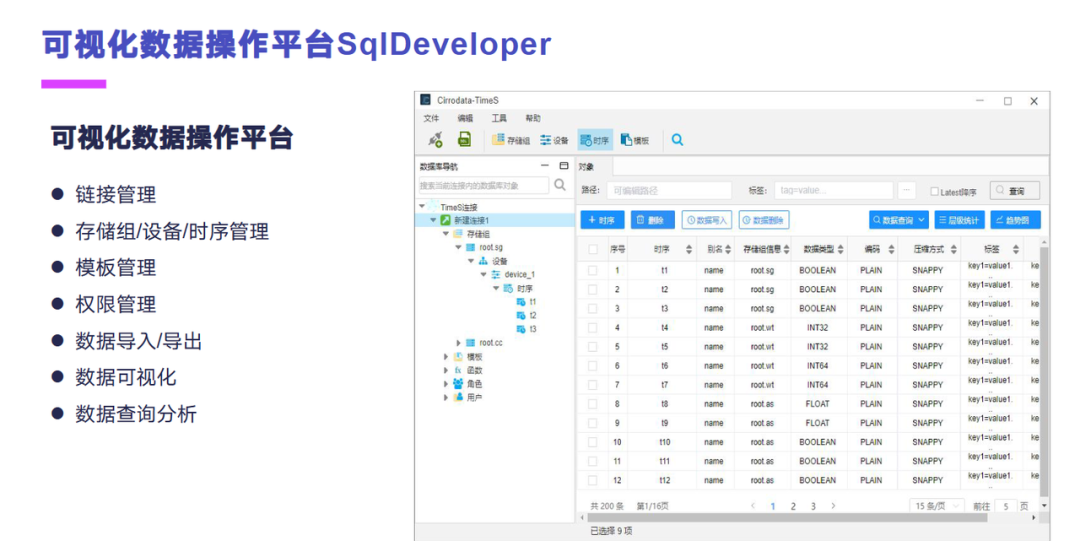
下面这个是一个可视化的数据操作平台,SqlDeveloper,为什么我会做这个东西呢?主要是因为有一些用户跟我们提一些需求,他们不想学习我们的这种 SQL 语法,只想做一些更简单的一些分析。数据库其实基本上还是面向于开发人员的,对于业务人员来说还是有一些门槛,他们需要了解一下 SQL 语法。因此我们为了降低业务人员对数据分析需要提供一套友好的数据操作页面,不用了解 SQL 语法就能分析查看数据。因此我们打造了一款可视化的数据操作平台,它主要是有以下几个功能,包括链接管理,存储组/设备/时序的一些管理,模板的一些管理,权限的管理,数据导入/导出,数据的可视化,还有数据的查询分析。
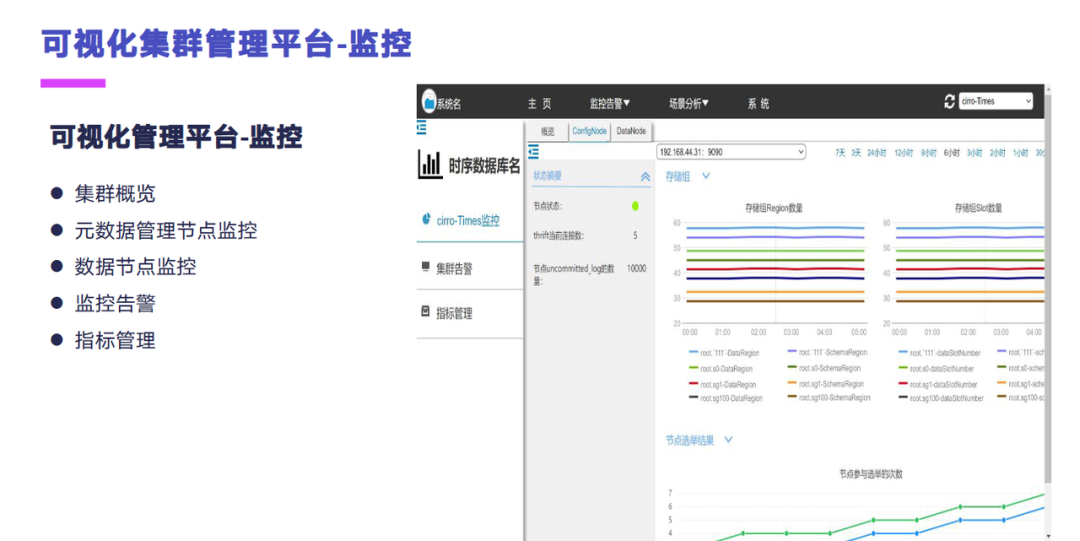
这个是我们的一个监控平台,其实它还是在可视化的管理平台上面做的。这个可以看到一些集群的概况,然后还有元数据节点的一些管理,数据节点的一些管理,包括监控报警,指标的一些管理。
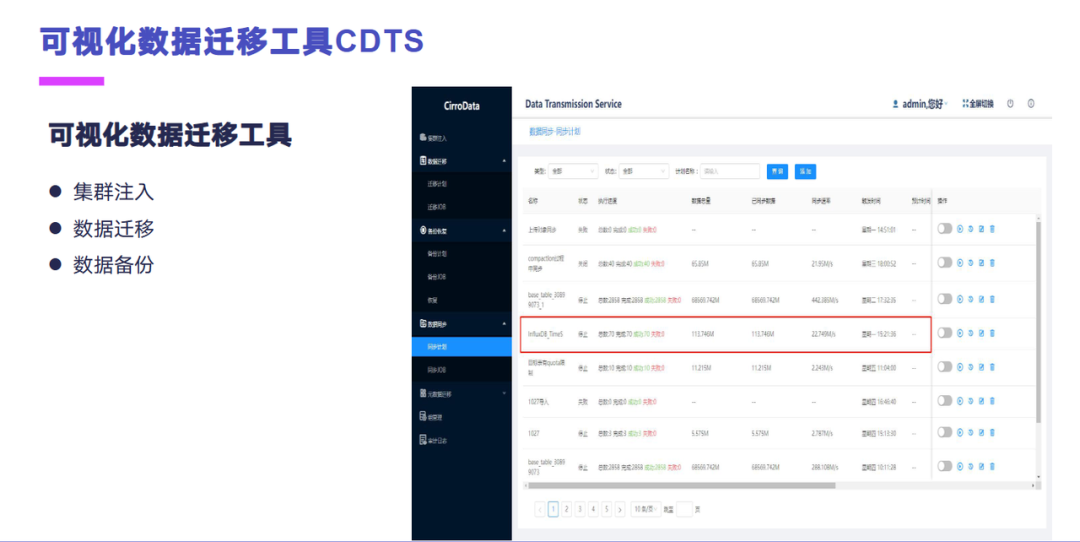
下面是我们的一个可视化的数据迁移工具 CDTS,这个的话是可以跟可视化集群管理平台联动,从管理平台导入集群的一些信息。数据迁移主要是一些旧的数据文件和系统数据导入到时序库里面,还有做一些数据备份的一些功能。这个就是数据迁移的话,它支持这种并发的迁移,能达到比较好的一个速度。
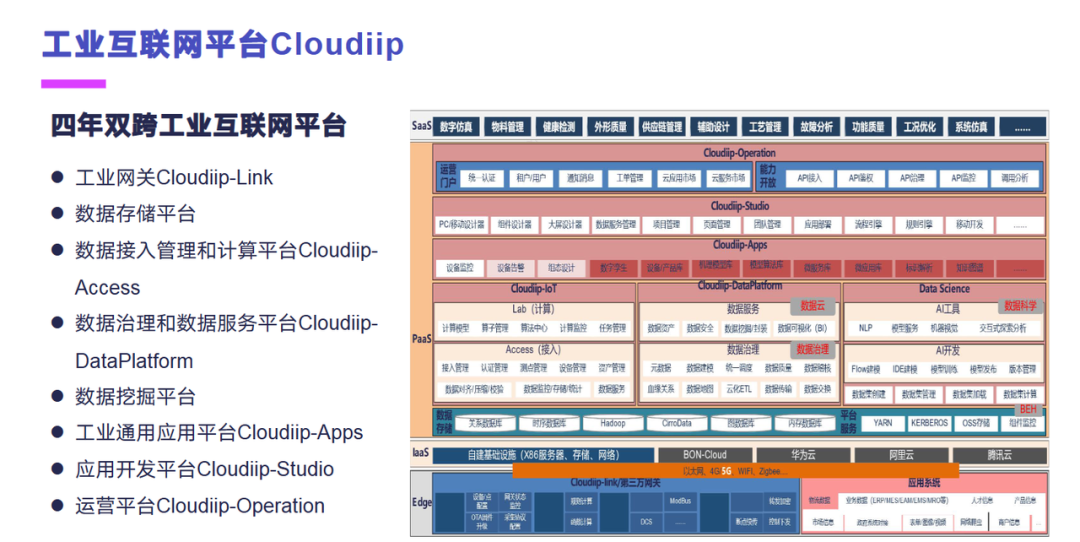
这个是我们的一个工业互联网平台,它是一整套解决方案,这是连续四年上榜国家双跨工业互联网平台前五名的工业的产品。覆盖数据采集、数据传输、数据存储、数据计算、数据建模、数据可视化、运营管理等多个方面的功能,提供一整套工业数据采集、存储、价值挖掘的解决方案。
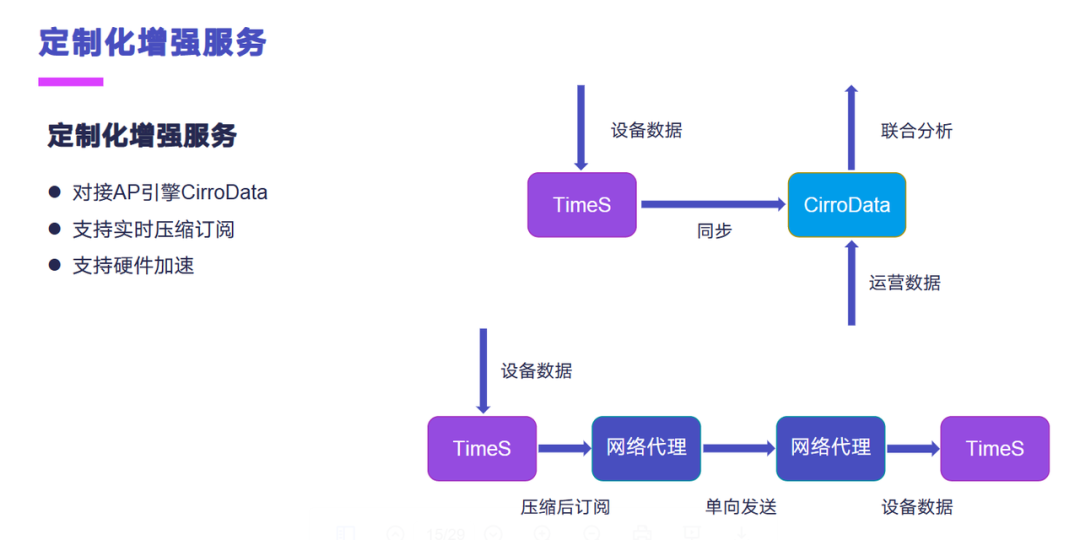
还有最后一个定制化的增强服务。我们主要做了三块,第一块的话是对接我们的 AP 引擎 CirroData,这个是因为时序数据库它主要是承载的数据的接入,还有一些实时处理,但是做一些历史分析之类的,它可能能力稍微有点弱。因此有一些用户他需要把时序数据导入到数仓里面,然后加上一些运营的数据做一些联合分析,开发了这个功能,把时序库的一些数据能定期的同步到数仓里面做联合分析。
第二块是支持实时压缩订阅,实时压缩订阅它面向的是这样的一个场景,数据需要实时同步场侧和中心侧,然后场侧和中心侧是具有单向网闸,数据只能从一端单向传到另外一端,并且带宽比较有限。这个时候我们就做了一个实时压缩订阅的一个功能,这个是在场侧时序库接过来的数据之后,我们进行这种压缩,然后实时发送到网络代理侧。网络代理单向发送到中心侧的网络代理,中心侧的网络代理接收到数据之后,然后按指定的协议解析数据包,解析完了之后再插入到中心侧的时序库里面。这个我们做完之后大概是压缩了 8 倍左右,相对于原始的这种数据,有效的降低了它的网络成本。
最后一块的话是我们跟硬件合作了一个硬件加速的一个功能开发。这个是与一个硬件厂商进行合作,适配他们的硬件加速卡来提升系统的性能,与不使用该加速卡的进行对比会有 11% 左右的性能提升,并且会降低 4% 左右的 CPU 使用率,后续也会贡献到社区。
03 社区贡献
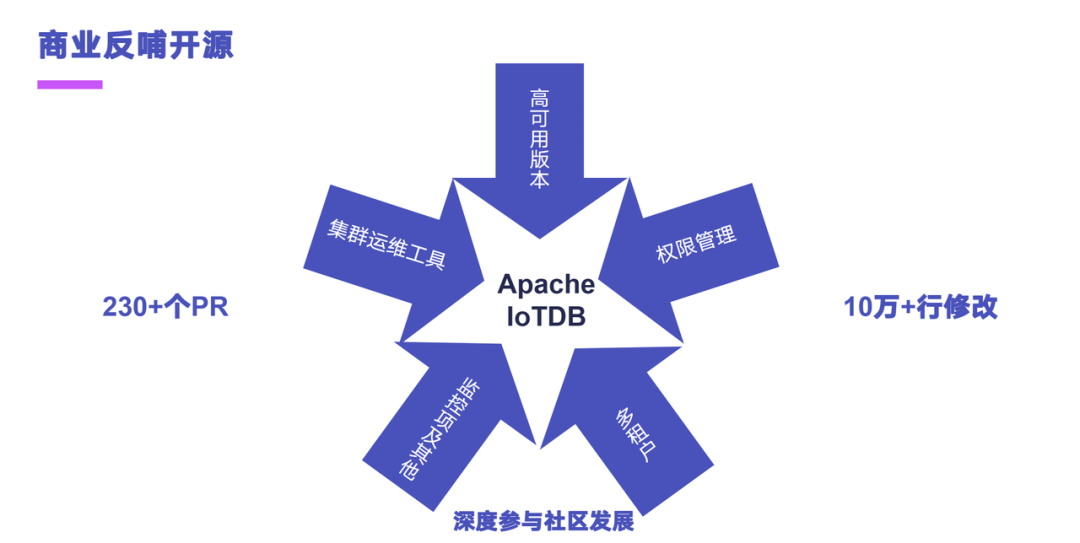
接下来我再来介绍一下我们的团队在社区的一些工作。我们从 2020 年参与社区到现在将近三年了,累计提交了 230 个 PR,然后共计有 10 万多行的代码修改,主要覆盖了有五个方面,高可用的版本,权限管理,多租户,集群运维工具,监控项还有其他的一些东西。
我们深度参与了 0.12 高可用的版本,这个版本是基于 RAFT 的协议的分区副本复制方案,具有高可用特性,能保障线上环境更加稳定可靠。我们主要参与的工作有副本一致性算法的一些优化,分布式元数据的一些管理,还有查询的重定向,控制和数据流的分离。
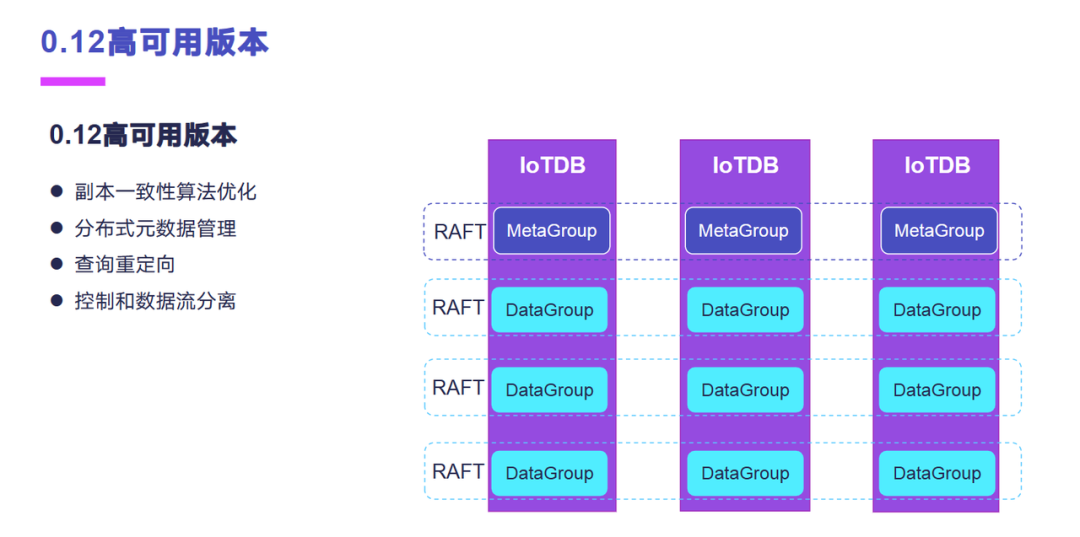
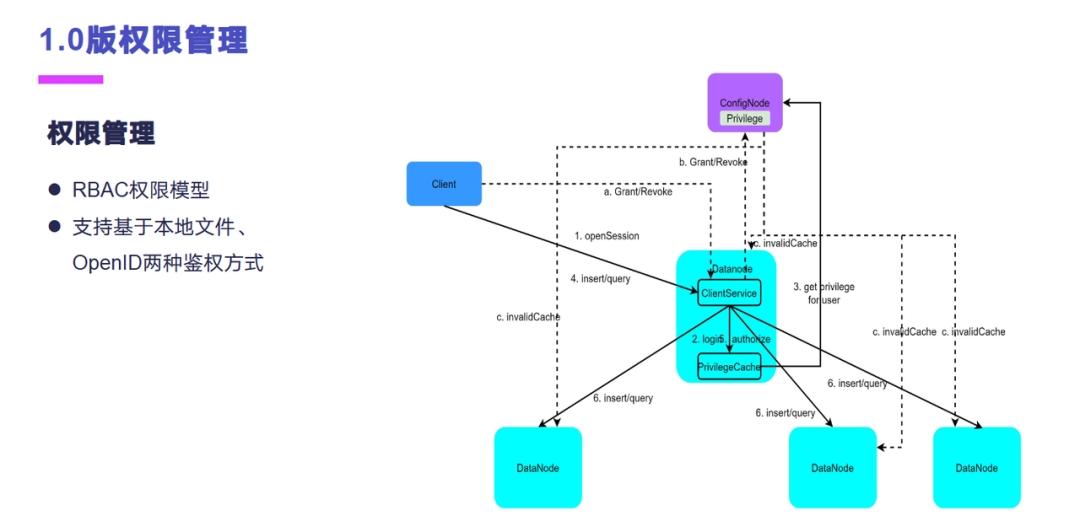
权限管理这一块我们参与了1.0版本的权限管理。权限管理的话实际上是基于角色的权限模型,目前的话是支持本地文件和 OpenID 两种认证模式。权限数据默认情况是存放在控制节点上面的,客户端访问数据节点之后,数据节点会有缓存,控制节点的权限数据在本地进行权限控制,尽量降低对控制节点的一些负载。
这是我们做了一个多租户的一个功能。这个功能主要是我们遇到的一个面向于集团的场景,他们会有多个厂使用总部的一套环境,每个厂只给分配一定的资源,防止对其他厂的一些影响。我们主要实现了两大类资源的一些限制功能,包括空间的一些配合,还有吞吐的一些配合。空间配合主要是面向数据库租户的,支持对磁盘空间、时间序列个数、设备个数的限制。吞吐配合主要是面向于用户的,支持对读写多维度的限制,例如请求大小、请求次数、请求使用的 CPU 和内存资源等,面向的对象是用户,作用范围可以是单机的,也可以是集群的。这个目前的话还没有提交到社区,后面的话我们也会提交到社区。

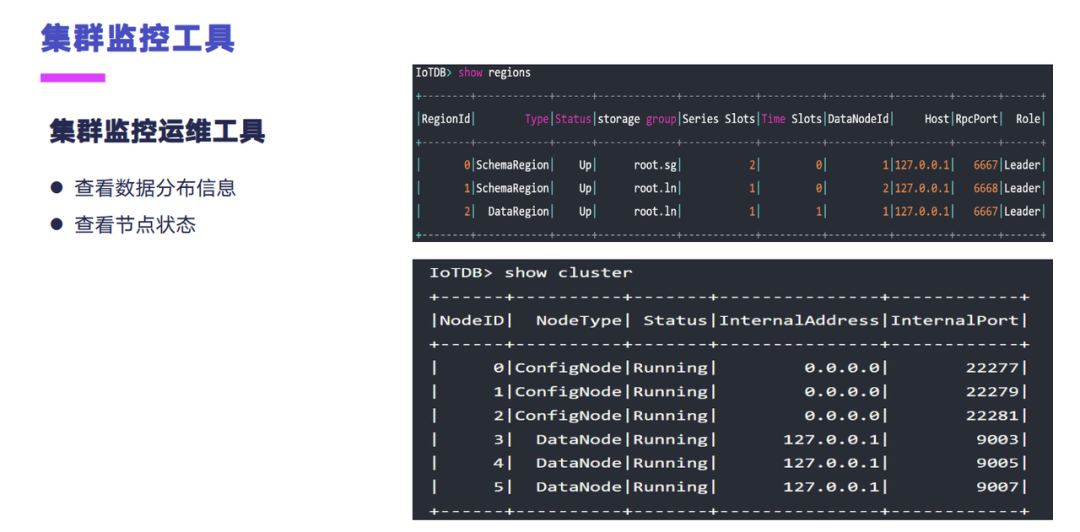
这个是我们做的一个集群监控运维工具。这个是 1.0 版本上面提供的,主要是用来查看数据的分布信息,还有节点的状态,方便于运维人员还有开发人员排查问题的时候能查看到数据的,还有经营、节点的一些状态。
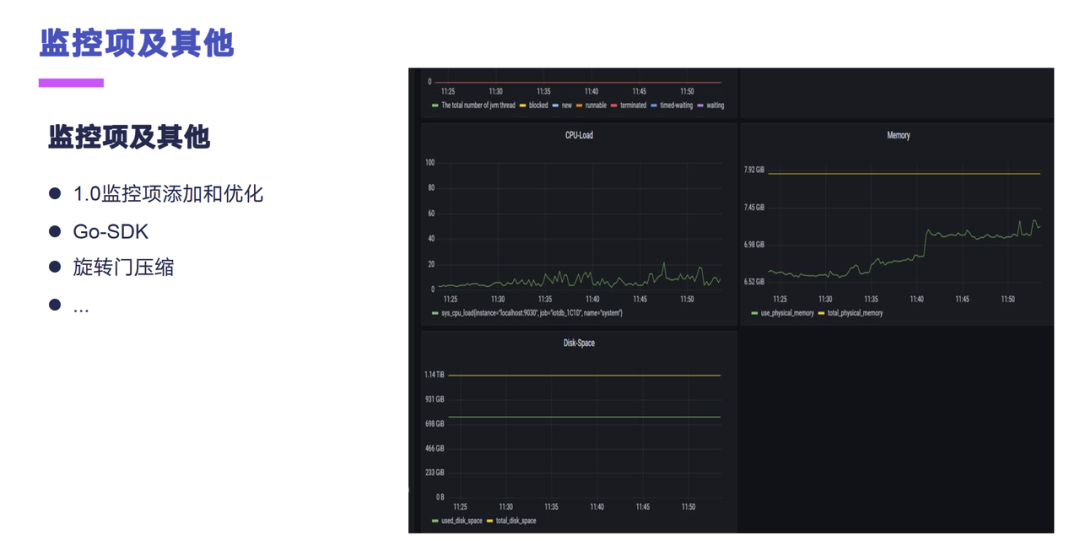
这个是我们做的关于监控项相关的,就是 1.0 版本的话它有一些监控项,我们做了一些监控项的一些添加,还有一些优化。在之前其实我们还参与过 Apache IoTDB Go-SDK 的一些开发,还有旋转门开发等等其他的一些开发。
04 应用案例分享
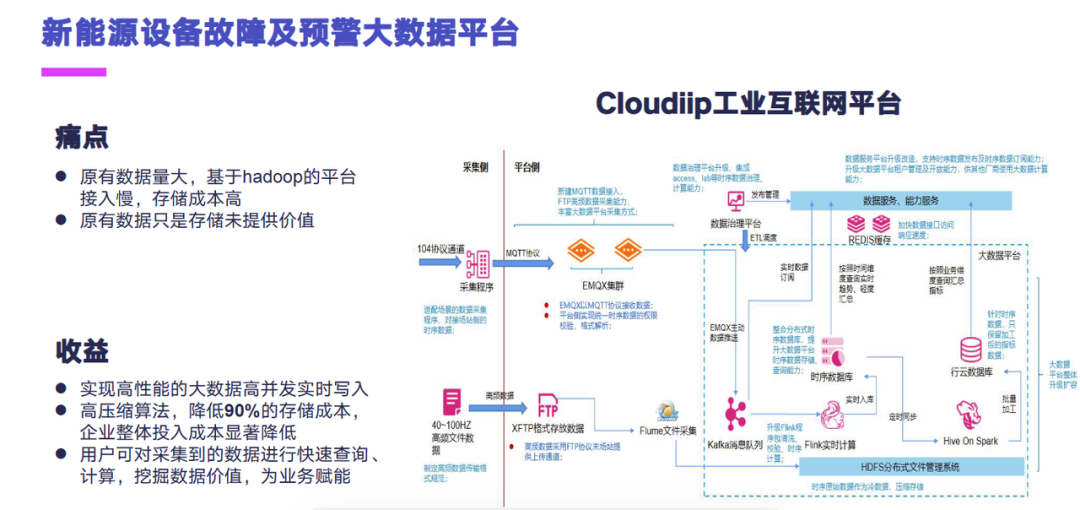
下面我来给大家简单的分享一下我们使用 Apache IoTDB 的一些案例。第一个案例是一个新能源设备故障及预警大数据平台,这个它原来的痛点是数据量比较大,之前是基于 Hadoop 的平台接入比较慢,存储成本比较高,原有的数据只有存储没有提供价值。而后面采用我们 Cloudiip 工业互联网平台之后,它实现的数据的大数据高并发的实时写入。然后因为主要还是时序类的数据,这个数据的话存入到时序库里面,能降低 90% 的存储成本,企业整体投入成本显著降低,用户可以对采集到数据进行快速的查询计算,挖掘数据价值,为业务进行赋能。
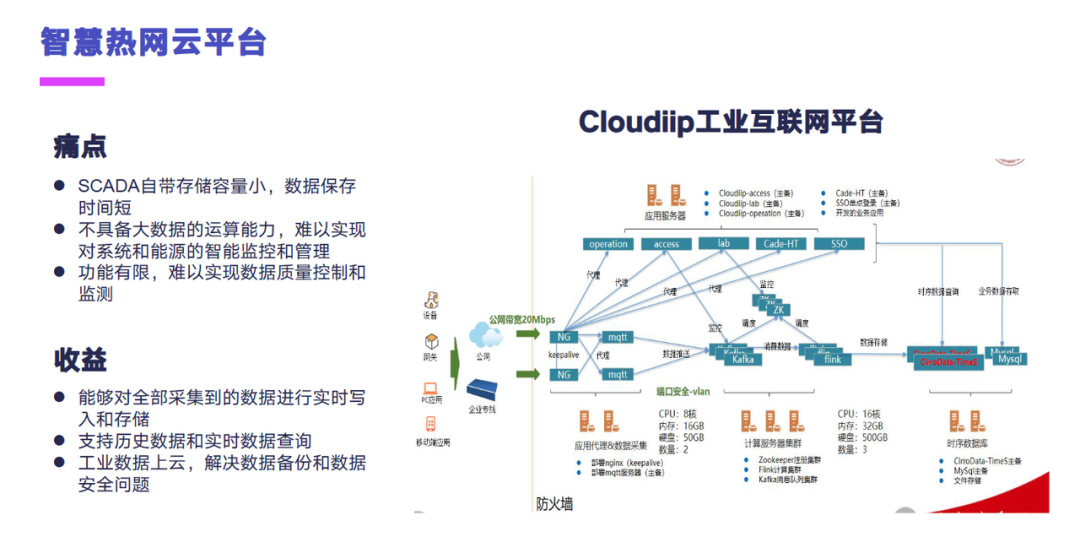
这个是一个智慧热网云平台,它原来的话是直接采用 SCADA 存储数据,并没有进行历史数据积累,然后不具备大数据的运算能力,难以实现对系统和能源的智能监控和管理。原来的系统的话功能比较有限,难以实现数据质量控制和监测。后面也是采用了我们 Cloudiip 工业互联网平台,能够对全部采集到的数据进行实时写入和存储,支持历史数据和实时数据的查询分析,然后数据上云之后,解决了数据备份和数据安全的一些问题。
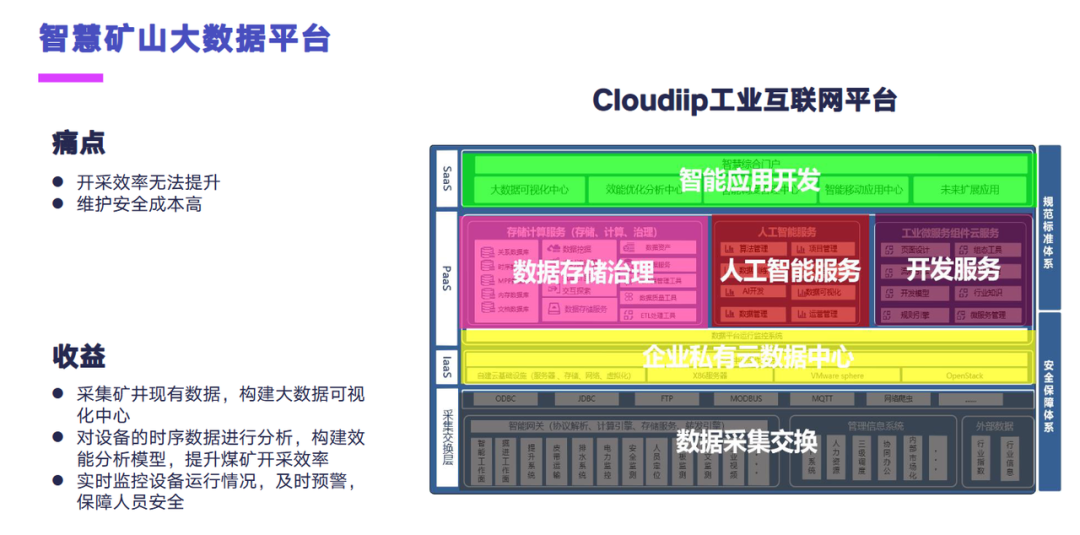
最后一个案例是智慧矿山大数据平台。这个原来主要是因为他们的煤矿里面开采的效率无法提升,然后维护安全的成本比较高。后面采用我们 Cloudiip 工业互联网平台,带来了以下几个收益。第一是采集了矿井现有的数据,构建大数据可视化的中心,能实时对数据进行查看。第二块的话是对设备的时序数据进行一些分析,构建效能分析模型,提升煤矿的开采效率,还能实时地监控设备运行状况,及时地预警,保证人员的安全。
05 总结
最后分享一下我们对开源、商业和公益的一些理解。我们认为做开源其实就是在做公益,因为做开源的话它具有两个好处,第一个就是它提供一个学习交流的平台,能让技术比较先进的一些地方,能把这种技术传播到技术稍微薄弱的一些地方。然后开源的话还能提供比较低成本的一些开源产品,让这种非信息化的一些行业,它能享受到信息化带来的一些好处,所以做开源就是在做公益。但是做开源其实对于产品来说也是有一些技术价值的,比如说它具有开放式协作的能力,用户和开发者能共同的推动产品的发展,产品迭代的速度比较快,成熟度更高。
第二,灵活性比较强,任何人都可以定制化适合自己的场景的代码来修改,来满足自己的需求。然后商业也是因为基于开源的产品总会衍生出一些定制化的一些需求,还有更高要求的服务,因此参与者可以对外提供这些软件服务来获得商业回报。但是商业也可以进行反哺开源的产品,让开源产品成熟度更高,能适用更广更深的场景,进而更广更深的场景的话也能为商业带来更多潜在的一些商业回报。
好,以上就是我的一些分享,谢谢。
更多内容推荐:
• 了解更多 IoTDB 应用案例
• 回顾 IoTDB 2022 大会全内容


