

12 月 3 日,2023 IoTDB 用户大会在北京成功举行,收获强烈反响。本次峰会汇集了超 20 位大咖嘉宾带来工业互联网行业、技术、应用方向的精彩议题,多位学术泰斗、企业代表、开发者,深度分享了工业物联网时序数据库 IoTDB 的技术创新、应用效果,与各行业标杆用户的落地实践、解决方案,并共同探讨时序数据管理领域的行业趋势。
我们邀请到德国普戈曼公司 CEO Julian Feinauer 博士参加此次大会,并做主题报告——《Apache IoTDB 在德国工业和关键基础设施中的应用》。以下为中文翻译全文。
非常感谢主持人的热情介绍,也感谢大会主办方邀请我在这里发言,很荣幸能够在本次大会上进行演讲。我将尽量放慢语速、清晰地讲述,希望大家都能理解我的发言。
我来自德国,所以打算谈谈德国的工业。我们听到了许多关于 Apache IoTDB 的用户案例,这些案例都来自中国,因为 IoTDB 在中国已经相当受欢迎。而我将分享两个我们在德国通过 IoTDB 实现的具体用例。
那么我要讲些什么呢?首先,我将简要介绍德国的数字化进程。对我来说,看到中国企业如何实现数字化是令人印象深刻的,而我将谈一下德国工业通常实现数字化的方式。然后,我将简要介绍我们正在开发的 Open MAchine Platform 框架,以在应用中集成 IoTDB。最后,我将介绍两个用户案例,一个是在德国铁路的燃料电池的应用,另一个是在汽车行业的铸造领域的应用。
01 德国数字化进程
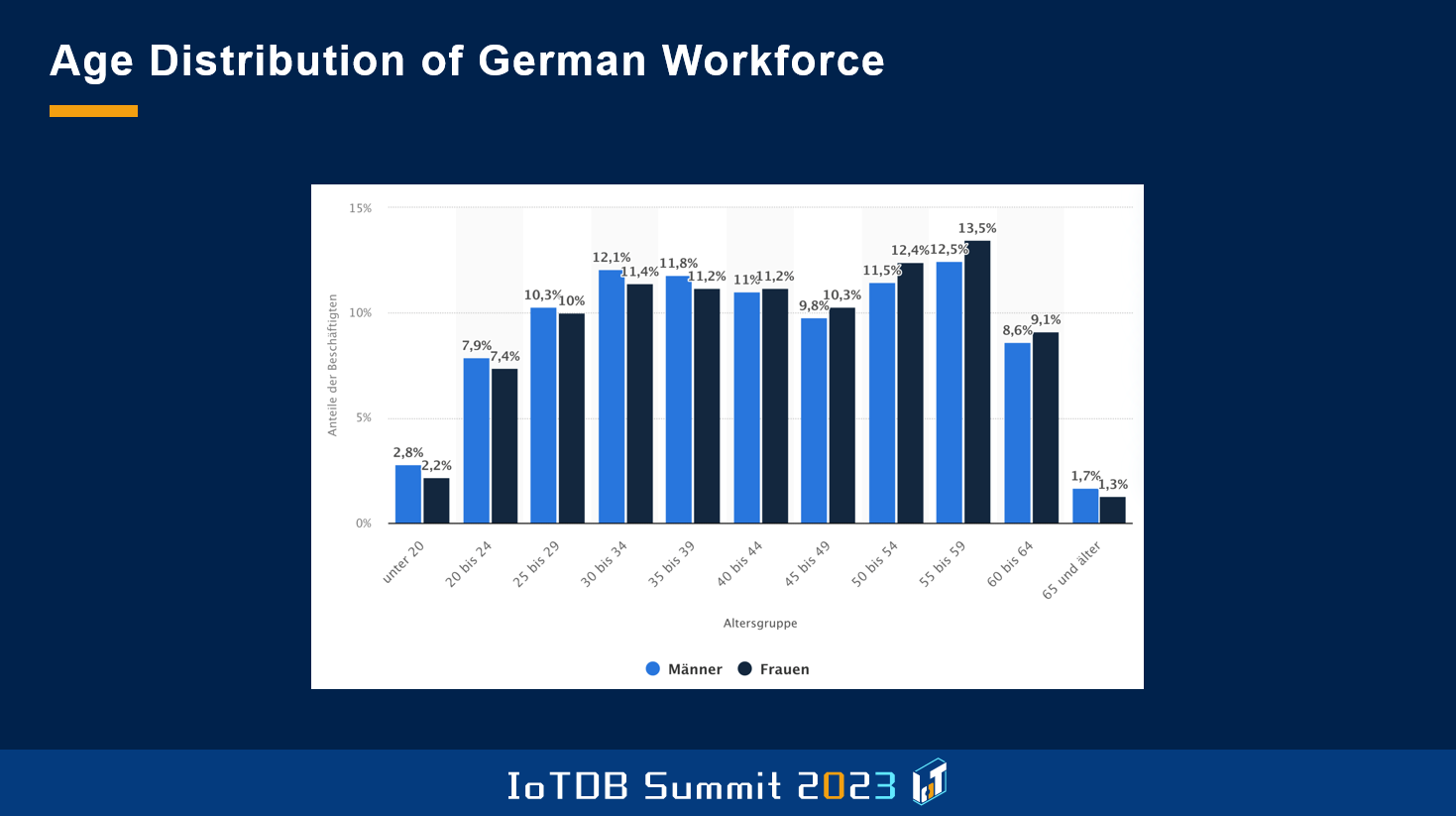
那么在德国,我们的数字化发展目前处于什么阶段呢?这张图是德国劳动力的年龄分布,可以看到,这张图的重心略微偏向右侧。德国劳动力的平均年龄为 45 岁,此外这些人通常并不非常具有 IT 经验,这对我们引入新技术造成了一定的负担。
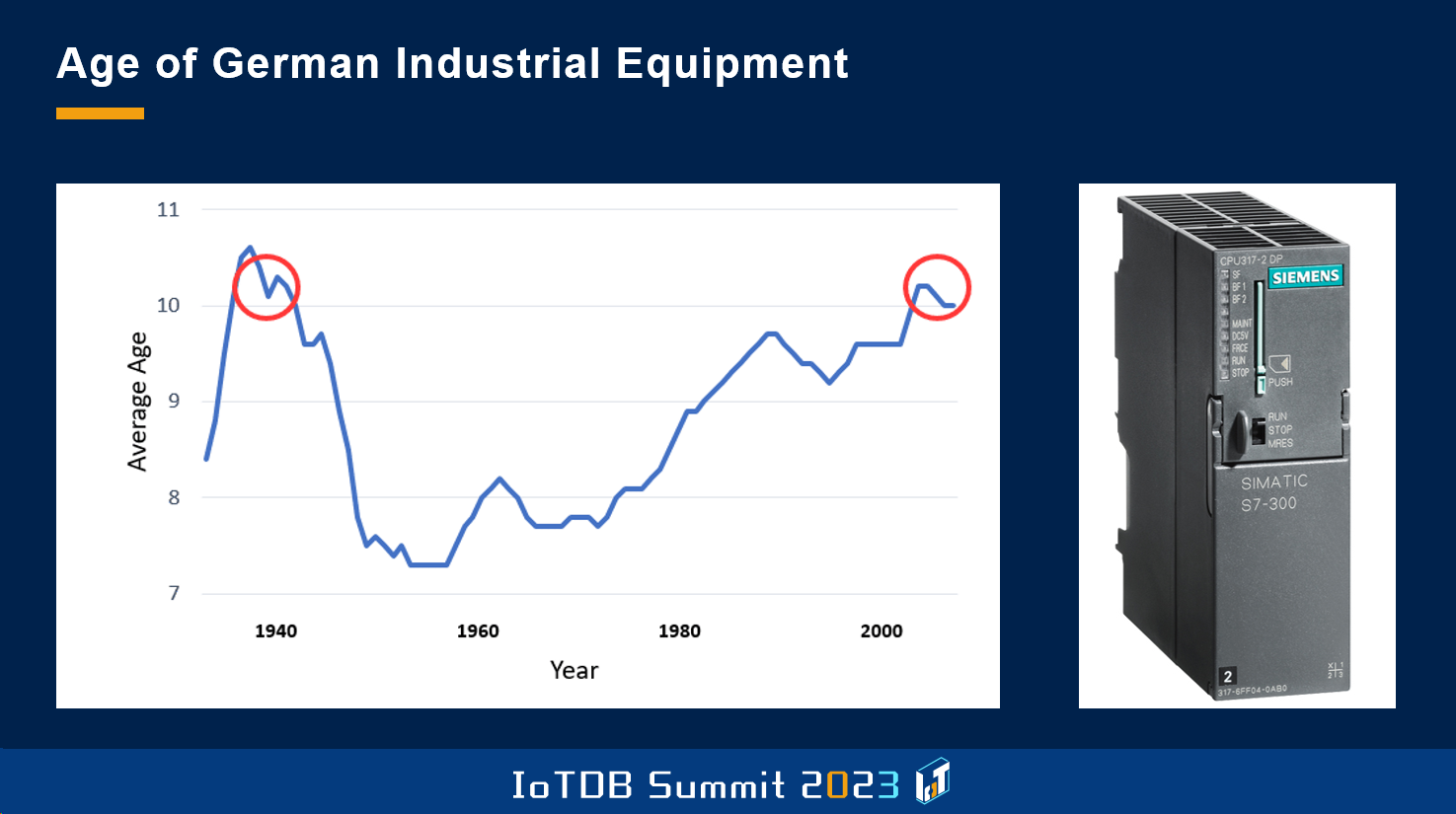
这张图表是德国工厂中典型设备的年龄。德国工厂设备的平均年龄超过 11 年,因此我们的设备资产相当陈旧,这带来的不利因素是这些设备中的控制系统也一样非常老旧。举一个比较典型的例子,右图是西门子 S7-300 设备,它在德国的工厂设备中非常常见。所以要配合这些设备,收集工厂设备的数据是非常困难的。
最后,对我来说最有趣的一点是看到中国工业中,有很多案例在专注于深度挖掘工业数据的价值,因为德国许多企业并没有专门的数据科学家或能够处理这些原始数据的人。因此,我们通常不得不对数据进行很多的聚合操作,以便设备的操作员、班组领导或工厂经理能够获取并理解数据信息,这是德国企业常见的做法。图中给出了一些典型示例,展示了我们通常会提供的结果样式,其中包括有关吞吐量、工厂效率等方面的一些数字。

02 工业应用实践
这也就引出了我接下来想说的。在德国,我们不太关注原始数据,有时候原始数据量也没有那么大。对我们而言,更重要的是对数据进行良好的全栈集成,以便我们能够向客户及其公司提供我刚才所说的信息,即从数据收集结果到计算的指标和 KPI,这对于他们更高效地运行、管理工厂非常重要。
通常,在构建这类解决方案时,大家应该已经意识到了,我们需要一些基本的系统。我们需要用户管理系统、资产管理系统,当然还有数据管理系统。对于时间序列数据,我们需要有效的分析系统或指标计算体系。并且我刚刚提到,对于我们来说,为专业人员和那些不会每天查看这类信息的普通员工都提供清晰的可视化呈现是相当重要的。

因为我们现在可能还处于传统应用开发的阶段,接触 IoTDB 的开发人员通常并不是数据库专家。他们可能是普通的开发人员、网络开发人员,以及后端开发人员等等。鉴于 Django 在网络开发领域比较受欢迎,我们最初开发的成果之一就是一个名为 Django_IoTDB 的框架,它使得 IoTDB 与 Django 的集成更加便捷,你不需要成为 IoTDB 和时序数据查询语言的专家也可以使用 IoTDB。
我们建立了一个抽象层,使得读取数据变得非常容易,并无需完全理解数据库语句的语法,比如 "group by" 是如何工作的等等。因此,这让开发人员可以更容易、更直观地基于 IoTDB 编写应用程序。

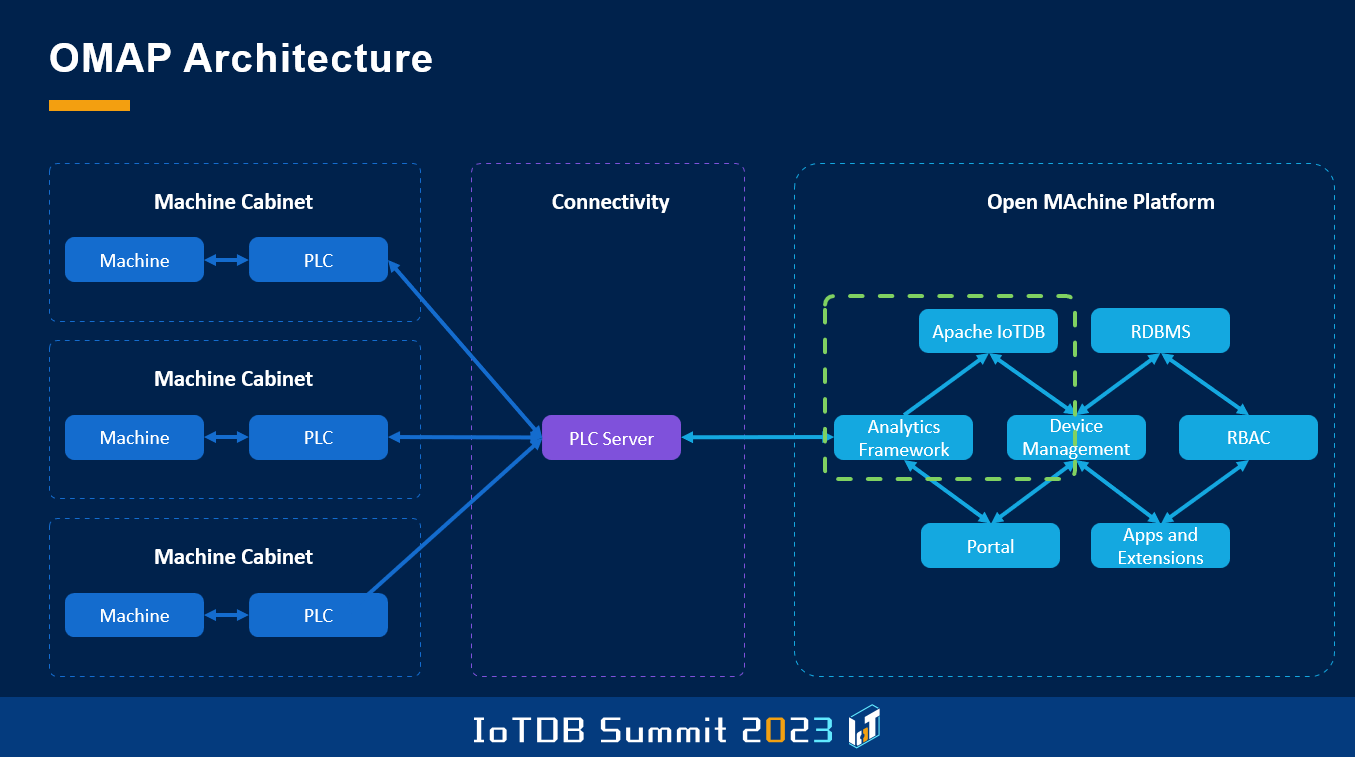
我们开发的另一个框架称为 Open MAchine Platform(OMAP),旨在解决我之前谈到的问题,即我们需要建立一些基本的系统作为使用 IoTDB 的前提,包括用户管理系统、资产管理系统等等。因此,这个框架基本上是我们启动基于 IoTDB 项目的基础。

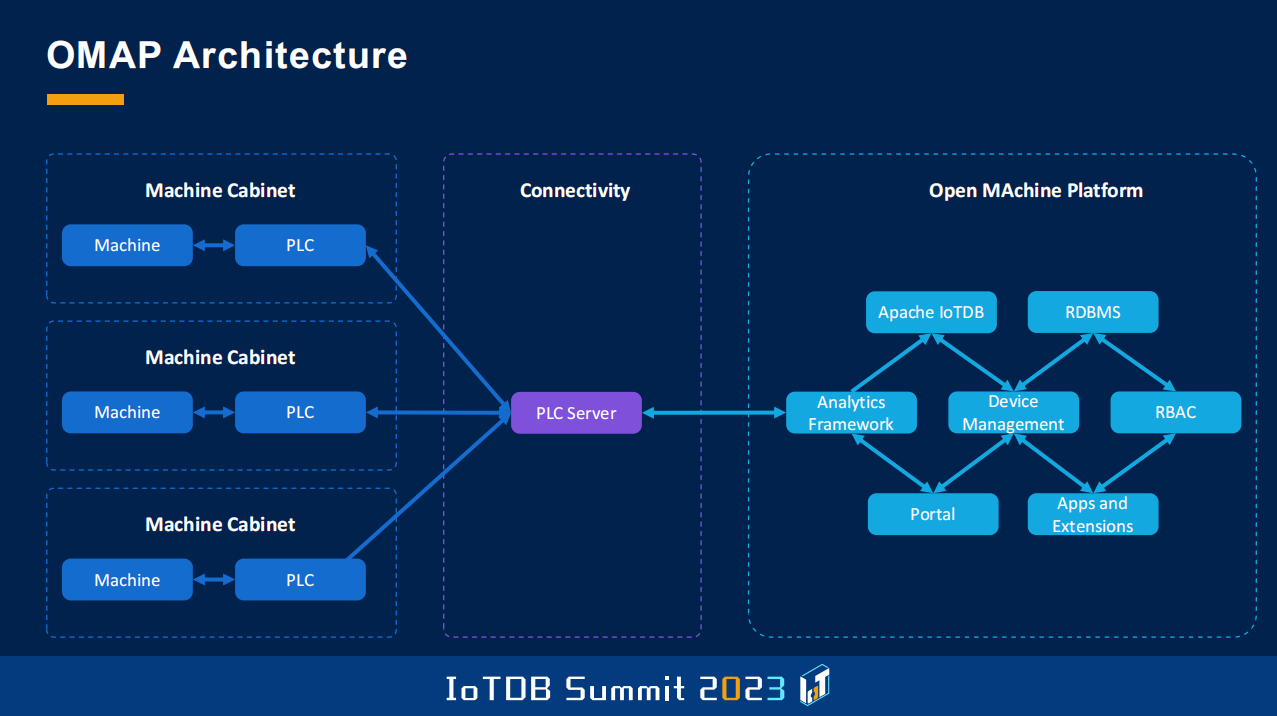
这里可以看到我们开发解决方案的整体架构。对我们来说这个被称为 PLC 服务器的模块非常重要,它基于另一个国际开源项目 Apache PLC4X。此时此刻,另一个分论坛应该正在介绍这个项目。我们使用 PLC4X 来收集来自不同设备的数据。在右侧可以看到 OMAP 的架构,它基于几个模块。对我们而言,基于角色的访问控制、设备管理、数据分析等模块非常重要,此外 OMAP 还包括应用程序与扩展模块。
当我们开始开发解决方案,或其他使用该框架的用户(由于它是开源的)开发解决方案时,整个架构都是免费的,用户可以根据其在特定领域,或在应用场景中的具体需求进行解决方案开发。
03 应用案例一:BZ-NEA 铁路能源项目
现在我将介绍第一个案例,它基于我刚刚展示的架构,是与德国铁路公司合作的一个名为 BZ-NEA 的项目。
德国铁路公司(Deutsche Bahn)在某种程度上类似于中国国家铁路集团有限公司。这是一家国有企业,负责与火车和轨道设施有关的所有事务,包括客运、货运以及所有与车站、铁轨等相关的基础设施管理。

两年前,德国铁路公司启动了一个名为 BZ-NEA 的项目,旨在用燃料电池替代目前由化石燃料驱动的备用发电机。德国铁路系统和它们重要开关的所在地区大都非常偏远,因此为了防止能源系统出现问题,会部署备用发电机为开关供电,以确保铁路系统仍能正常工作。随着我们朝着碳中和的方向发展,用燃料电池替代这些备用发电机就成为了一个重要目标。

下图是德国铁路中备用发电机的外观示例。这是一个发电机在非常偏远地区的例子,因此在这种环境部署备用发电机是一项必要的措施。

也许大家已经有所了解,与我们使用了一百多年的内燃机相比,燃料电池是一种相当复杂的技术。我们必须管理不同种类的介质,并持续关注多种操作参数,以便实现燃料电池运行的实时监控。
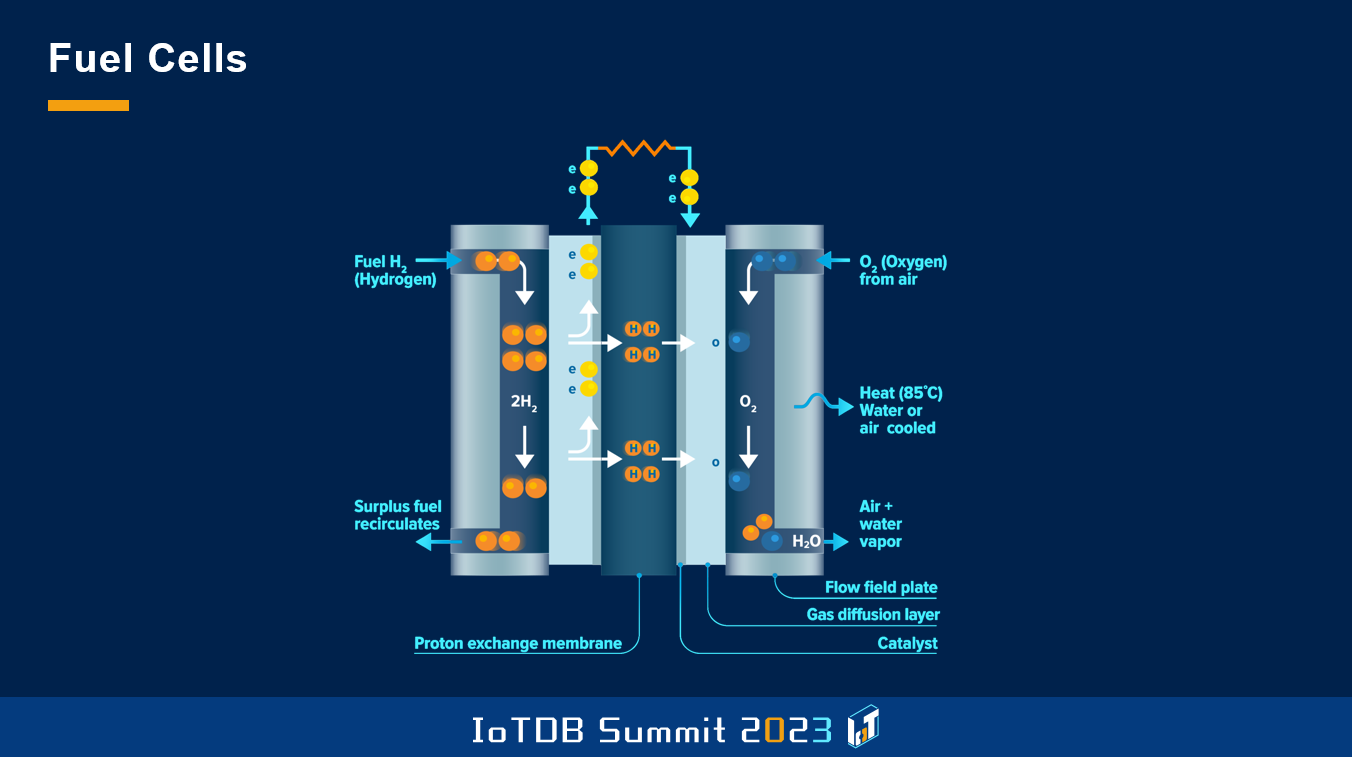
这张图是 BZ-NEA 项目中一个燃料电池的示例。从外观上看,它也比基于常规内燃机的备用发电机复杂得多。

在我深入介绍解决方案的细节之前,我想提及对于这个项目的另一个关注点。大家可能知道,德国有很多有关数据保护的法规,比如 GDPR,但在这个案例中还有另一种重要的法规,称为 KRITIS。KRITIS 可以理解为关键基础设施,所以对于用于关键基础设施的所有软件,德国都有特殊的法规。而德国的铁路系统就被视为关键基础设施,因此我们必须满足对于安全的特殊要求。

下面是这个项目系统的架构图。大家可能发现了,它看起来与我之前展示的架构很相似。不同之处是 PLC4X 被 MQTT 代替了,因为在这个场景下,德国各地的所有站点都是直接通过 PLC 发送数据的。在该图的右侧有一个连接器,可以将数据直接写入到 Apache IoTDB 中,这个架构与之前展示的通用架构的另一个主要区别,就是 Apache IoTDB 与基于角色的访问控制模块之间存在直接连接。
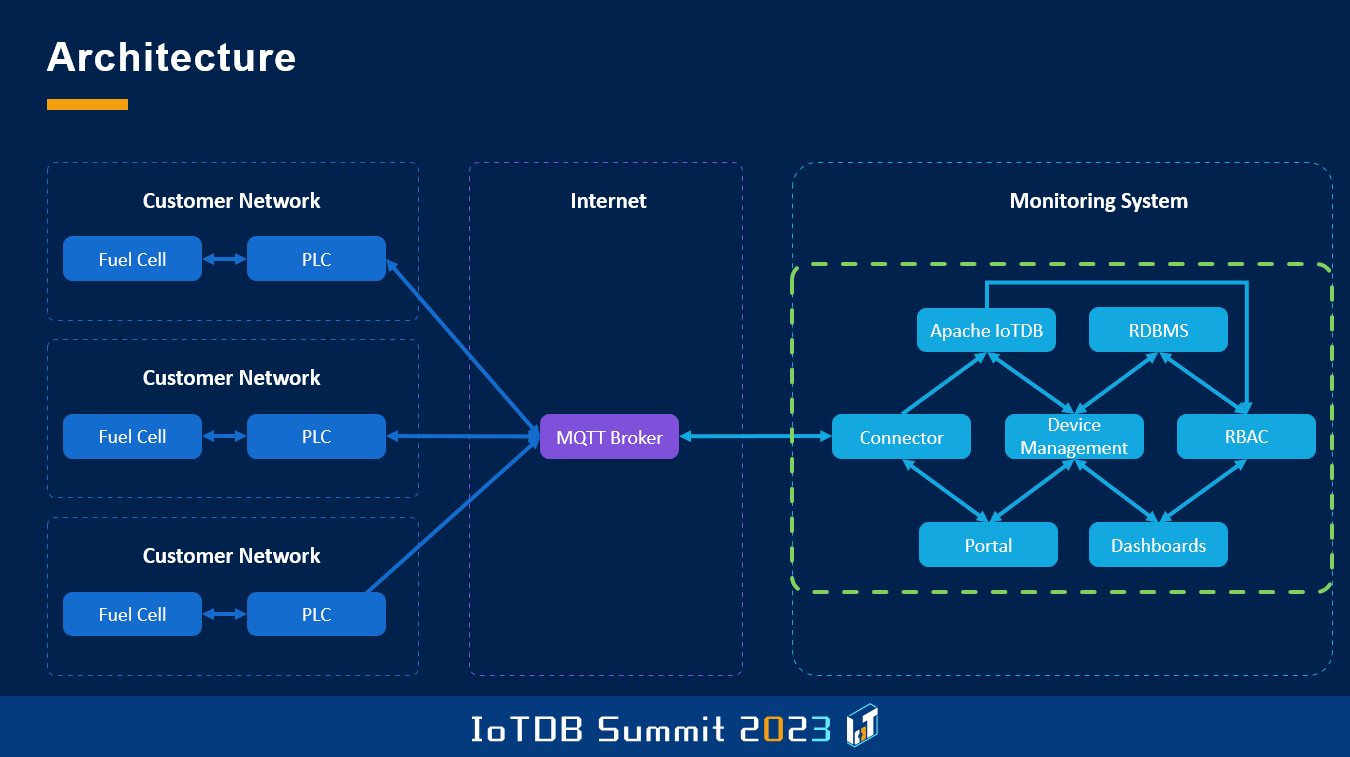
这里的前端架构基本上与我们今天看到的许多应用程序非常相似,即我们写入数据,消费数据或以多种不同的方式展示数据。但由于我们有特殊的法规,我们不能只在前端进行用户管理,然后在后端查询数据,而是必须在数据库层级直接提供用户管理服务。
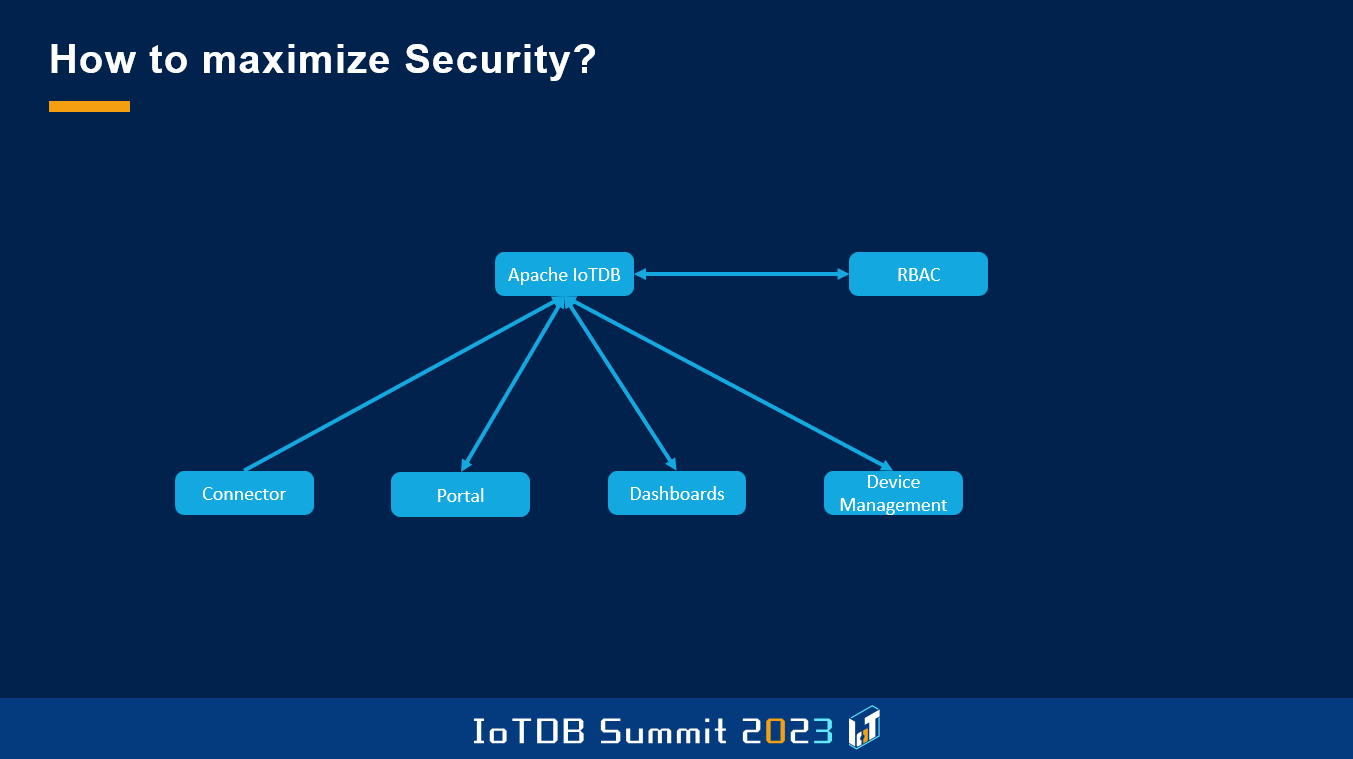
在 IoTDB 中有一个组件,我不知道这个组件是否有名,叫做“可插拔权限组件”。通过这个组件,用户可以为权限创建自定义的实现。每当在 IoTDB 中执行读取或写入操作时,该模块都会检查发送该请求的用户是否对此设备或时间序列具有相应的权限。IoTDB 的这个组件默认使用基于文件系统的解决方案,而我们在此基础之上,提供了一个名为 OpenIdTokenAuthorizer 的实现。
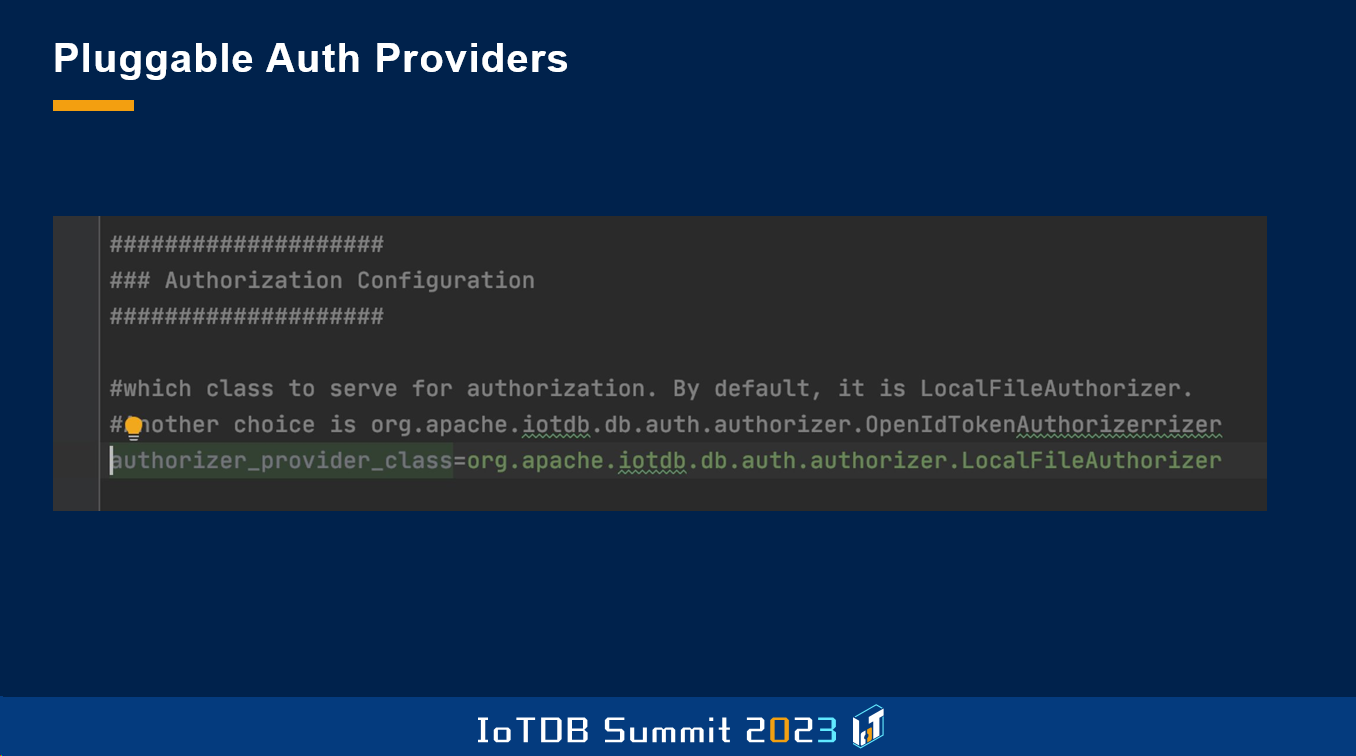
这里可以看到一个实现示例。如果有一个来自前端的请求,它将携带 OpenID Token 或 JSON Web Token,我们会将这个 Token 同步到数据库。然后在数据库层级上,我们会设置代码读取 Token、识别用户,并检查该用户的权限,以确认其是否有权执行请求的操作。这为我们提供了一种以很小的运维成本,满足这些非常严格的法规要求的可能性。

04 应用案例二:Smart Core 车厂项目
现在我将介绍第二个案例,名为智能核心(Smart Core),是一个铸造车间的项目。我认为这个案例会很有趣,因为它涉及到德国汽车工业,这个行业的一举一动通常都令人瞩目。
这个项目是在一个宝马生产 8 缸发动机气缸体的铸造车间。通常,在每个铸造厂中都有一个被称为核心车间的地方,这个车间是制造所谓的砂芯的,稍后我将详细介绍。作为发动机气缸体的零部件具有非常复杂的内部结构,用于冷却液或电缆连通等等,因此这些零部件只能在使用砂芯的情况下高效生产。

这是这类车间砂芯的一个实例,它们在制模过程中被放置在零件内。在制模完成后,砂芯被拿走,留下零件中的孔洞。对于熟悉低压铸造的人来说,这是一个标准的步骤。

这是一个非常有趣的过程,因为它非常复杂。在一条铸造生产线上,我们有多达 10 台图中这样的设备,被称为射芯机,也就是是生产砂芯的设备,而这些设备有超过 200 个传感器。
同时,这类机器的制芯过程中,包括物理过程和化学过程,既涉及化学反应,同时还受到温度和压力等物理因素的较大影响。而且,这些过程的时间跨度均不相同,从砂被注入模具时的微秒级,一直到砂的处理和冷却过程可能需要数秒甚至数小时。
在这个过程中,我们对所有这些时间序列数据进行汇总,然后使用这些传感器上报的原始值进行聚合,生成有助于提高工厂运营效率的指标。

这个案例的架构图如前所示,依旧基于 OMAP 平台。其中有 PLC 服务器,以及一个分析框架模块,负责处理从 PLC 获取的所有数据,并进行必要的计算,以生成客户需要的度量指标。我认为这是一个德国工业中相当标准的 IoTDB 应用场景了。
这其中,可能最有趣的部分发生在图表标出的这一区域。目前,我们使用 Apache Flink 作为流处理框架,这也是一个相当普遍的模式。但随着 Apache IoTDB 的发展,我们正在尝试迁移到一种基于用户自定义函数 UDF、连续查询和触发器的方法,这将实现在数据库内部完成所有时间序列分析任务,从而可以简化我们的应用架构。
这些图片我之前展示过,体现出的是我们进行数据分析的结果。基于我们从传感器和 PLC 获取的数据信息,我们可以计算生产率和与质量相关的指标等等。我们还能够生成一些有关制造过程的报告,用于质量检查和质量控制。
汽车行业中的另一个重要关注方向是生产成本。生产成本是汽车高效制造的关键部分,所以宝马进行了相当深入的计算。在汽车制模过程中将使用很多种介质,包括水、压缩空气、能源、砂和一些化学添加剂。到目前为止,这个项目刚刚对一周内使用的材料量和生产的零件数量进行了整体统计。
现在,我们也可以在每个单独的汽车制模环节中深入挖掘这些数据,比如某种类型的砂芯更有可能制造失败、更容易破裂,因为它质地更脆弱或者设计更复杂。这也将导致它可能消耗更多的砂,或者导致使用它的其中一些汽车更容易报废。这是一类非常重要的分析,所以我们每天都会生成这些报告,以了解哪个订单、哪个零件、哪个砂芯消耗了多少能源、介质等等,然后这些信息将被用于严格的制造成本计算。
我们实现的另一件事是,通过从设备上报并读取的参数,我们可以了解到设备上装备了哪些工具、砂芯的质量以及砂芯的具体加工方法。因此,我们可以利用这个系统来控制后续的生产流程。例如,我们可以仅基于数据,自动生成供 SAP 系统、ERP 系统和仓库使用的订单信息,而无需额外的集成应用层。因为我们已经通过数据,了解了砂芯的类型和质量,所以可以自动指令仓库在何处存储它们,以及在何时提供它们等等。
05 Summary 总结
到此,我可以来做个总结。很遗憾,我不得不说,与我在其他国家以及这次中国之行的最后一天所看到的情况相比,德国的数字化转型进程仍然较慢。这源于我所谈到的各种原因,或许还涉及一些心态问题,但这确实也与我们的工业有着悠久的传统有关。这是一件好事,但另一方面,这意味着我们的设备资产有时可能较为陈旧,使得将它们整合到数字化流程中变得更加困难。
另一点是,正如我之前讲的,即使是德国的公司,甚至是汽车领域,大多也还没能建立自己的数据分析团队,而是更专注于非常传统的工厂管理,这就给我们这样的数据管理从业人员带来了一些负担。如果我们想向他们介绍 IoTDB,那么我们不能只是提供给他们一个数据库,说:“嘿,这是一个很好的数据库,你可以将你的数据存储在里面”,而是必须覆盖全生命周期,从数据采集、分析到指标评估,提供一个完整的解决方案。
另外,德国的工业应用需要的数据量并不是很大,因为我们无法收集所有设备的所有数据,特别是旧的设备。另一方面,我们进行分析所需的数据粒度也不是很高,因此对于这类应用来说,我们肯定没有将 IoTDB 的性能极限发挥出来。
以及,集成应用非常非常重要。因此,我们还构建了上述提到的这些框架,以帮助其他公司基于 IoTDB 构建他们自己的解决方案,而无需一遍又一遍地编写相同的样板文件代码。
我想要强调的另一个重要方面是,IoTDB 的通用性与灵活性使其几乎适用于任何应用场景,包括这里提到的德国关键基础设施领域的应用场景。而且,IoTDB 作为开源项目,这也加强了它的适用性,对我们非常有帮助。
总的来说,这就是我的演讲内容,最后我想分享一个小信息。正如我之前所说,我讲到的这个铸造流程来自宝马。因此,如果你驾驶的是一辆 4 缸或 8 缸发动机的宝马汽车,很有可能你的发动机的数据就被存储在某个 Apache IoTDB 的实例中。我想这个小信息应该是一个不错的结语,谢谢!

更多内容推荐:
• 了解更多 IoTDB 应用案例
• 回顾 IoTDB 2023 大会全内容


