

历经 2023 年的“千模大战”后,大模型的风也在今年刮到了时间序列领域。
从最初的时序数据分析应用到如今的时序大模型,时序数据分析迎来哪些发展历程,国内外有哪些时序大模型玩家,各个时序大模型应用效果又如何?
本文将一一解答……
01 演进历程
时序大模型无疑是一个新兴领域。
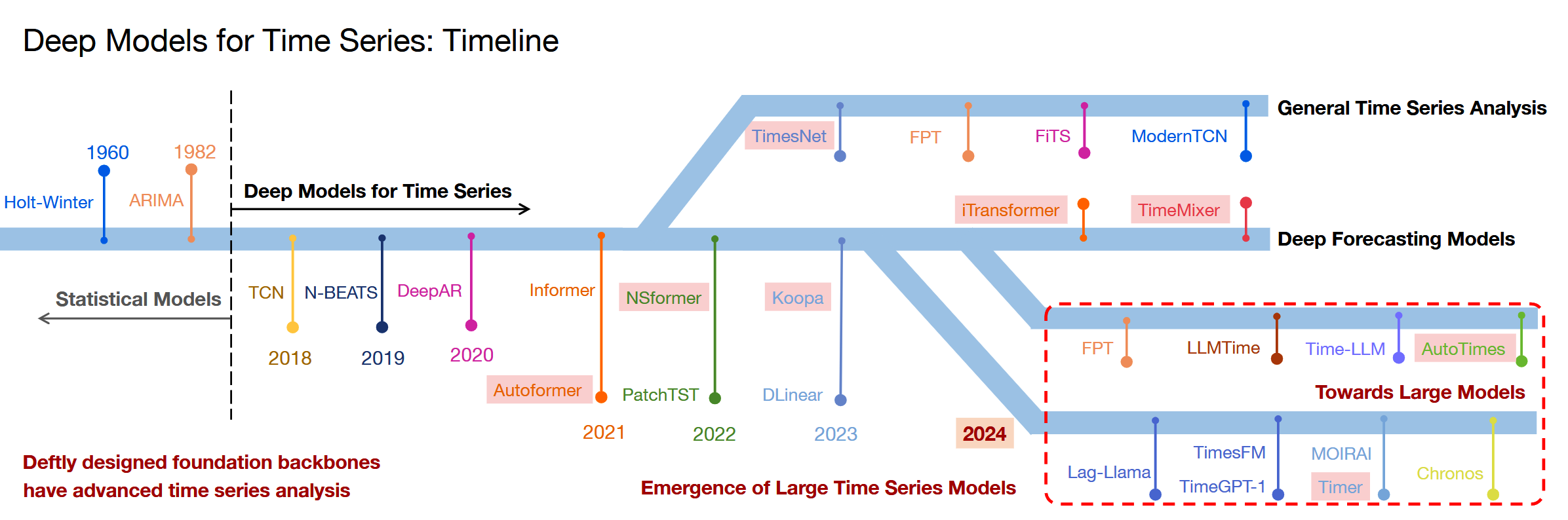
2018 年以前,业内更多还是采用统计模型来分析时序数据。2018 年之后,针对时间序列的深度模型研究开始蓬勃发展,并出现了一般时间序列分析与深度预测模型两类成果:
一般时间序列分析主要基于经典统计学方法,如自回归滑动平均、趋势分析、状态空间模型以及谱分析等等。这些方法通过数学公式描述时间点之间的相互关系,分析时间序列的组成逻辑,或者建模时间序列的生成过程。
深度预测模型则通过设计神经网络结构,从海量数据中学习复杂模式和特征,进一步解决传统时序分析技术难以处理的若干挑战,比如海量数据建模、复杂时序变化、多变量关联、分析模型的泛化性等等。
然而,时间序列的多样性、非平稳等特性,对深度学习方法的模型容量和泛化能力提出了严峻挑战。同时,依赖数据驱动训练的深度学习模型,仅能应用于单一场景与任务,制约了其在丰富现实场景中的有效应用。
因此,到了 2024 年,时序分析模型领域出现了一个新的分支——时序大模型,该技术在模型通用性、下游任务适应性、可扩展性、预测准确性等方向实现进一步突破。
具体而言,目前针对时序大模型的研究主要有两个方向:
第一个方向是大型语言模型(LLM)的应用。这类模型在自然语言处理(NLP)任务中表现出色,现在也被转用于分析时序数据,以利用其卓越的模式识别和预测能力。
第二个方向是原生时序大模型的研发。这类模型专门针对时序数据特性量身设计,考虑了时间序列数据的连续性、周期性、时间依赖性等关键属性,能够提供更为精确、高效的分析预测。
02 典型成果
在时序大模型的发展历程中,众多具有全球影响力的企业扮演着不可或缺的角色,部分企业开发的时序大模型如下:
TimesFM:由 Google 开源,是一种预训练的仅解码器基础模型,优化了对上下文长度最多 512 个时间点和任何时间跨度的单变量时间序列预测。
MOIRAI:由 Salesforce 开源,通用模型设计使预训练模型有能力进行多变量时间序列预测,具备零样本预测能力。
Chronos:由 Amazon 开源,通过对时间序列数据进行标记,并使用交叉熵损失函数在这些标记化的序列上训练语言模型。
TimeGPT-1:Nixtla 研发,可以实现 API 调用。其利用历史值窗口生成预测,通过添加本地位置编码丰富输入信息,且允许用户利用自己的数据对于模型进行微调。
除了上述由国外互联网大厂主导的成果,还有来自高校及开发者研发的时序大模型,例如:
MOMENT:通过在大量公共时间序列数据上进行掩码序列预测任务,进行模型预训练。
Lag-Llama:为单变量概率预测而构建的模型,使用数据滞后期等先验知识编码时间序列数据,并提升模型泛化能力。
ForecastPFN:旨在解决零样本时间序列预测问题,通过在预定趋势和季节性生成的合成数据上进行训练,来分析未来数据趋势。
国内对时序大模型的技术研发也愈加深入,并已经自研出在泛化性、可扩展性、预测表现上等方面表现优异的时序大模型,其中的代表便是开源原生时序大模型 Timer。
Timer 模型和时序数据库 IoTDB 一样,发源于清华大学软件学院,针对时间序列领域,拥有基于大规模预训练的丰富知识库,具备可观的分析能力和对真实世界数据的理解能力。通过依靠显著的少样本能力对特定任务进行微调,Timer 模型被赋予了强大的通用能力,能够处理多样化的下游任务。
目前,Timer 模型已经内置在 IoTDB 的 AINode 中,用户能够在 IoTDB 中非常方便地进行调用。得益于 Timer 模型的优异性能,IoTDB 可以有效地为时序预测、数据填补、异常检测等工业场景提供解决方案。
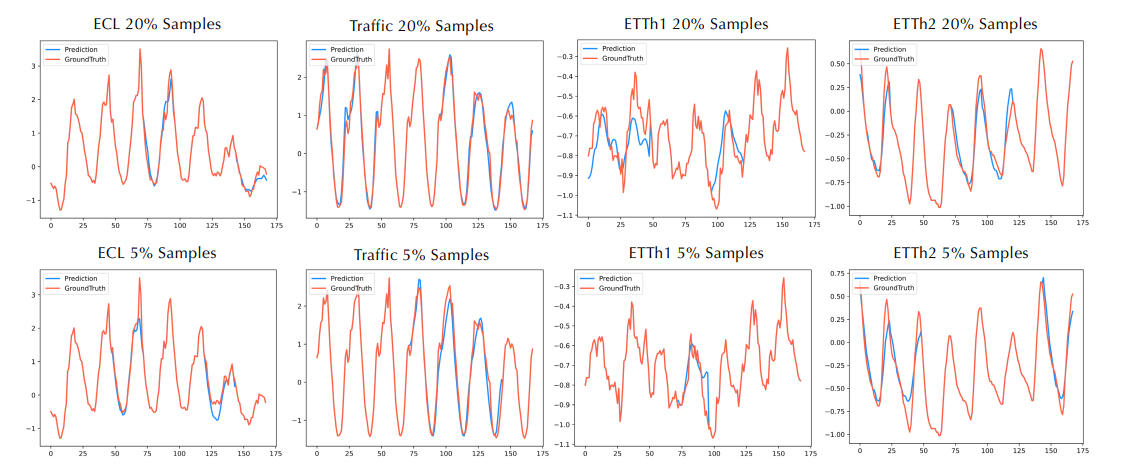
Timer 模型的部分极低样本使用率下的微调结果
来源:ICML 2024 论文《Timer: Generative Pre-trained Transformers Are Large Time Series Models》
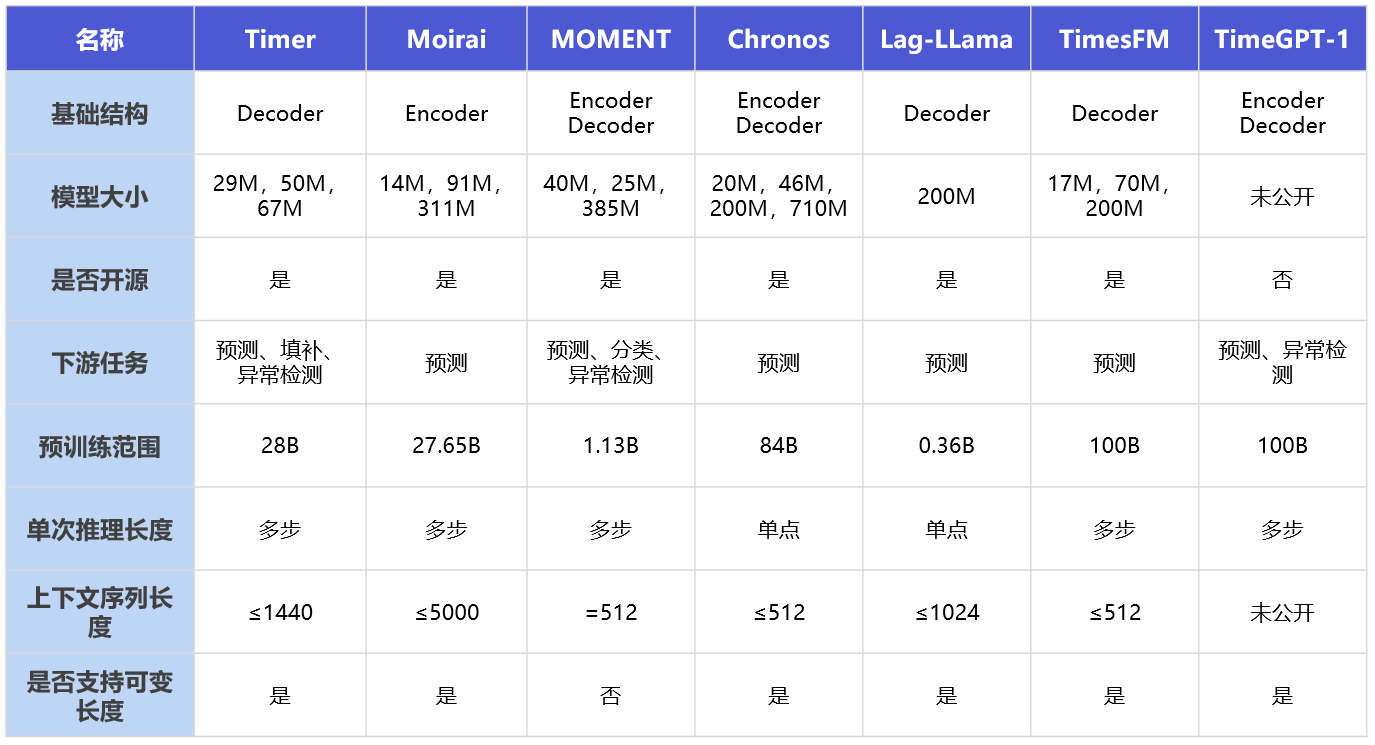
上述提到的时序大模型,其结构、模型特点、支持应用场景等重点特征如下:
03 性能对比
体现时序大模型性能的典型场景之一便是零样本预测任务,也就是在没有针对特定数据集进行训练的情况下,直接对时间序列进行预测。
这是因为,时序数据体量庞大、写入并发量高,完全基于历史数据训练模型是较为困难的。处理零样本预测任务将直接决定模型的泛化使用能力,需要模型具备强大的特征提取能力。
下图为在 7 个真实数据集中,多类大模型的零样本预测任务结果对比。图中的指标为 MSE(预测均方误差),该值越小,表示模型的预测值与实际观测值之间的差异越小,预测的准确性越高。
可以看到,Timer 模型在多个数据集的表现均名列前三位,在平均排名值中(模型在每个数据集上的 Top1 次数/参与比较的数据集总数),Timer 模型也取得了综合最优的水平。
值得一提的是,Timer 的性能优势不仅体现于零样本预测,还包括少样本微调、任务通用性、可扩展性、对于可变序列长度的适配性等方向。
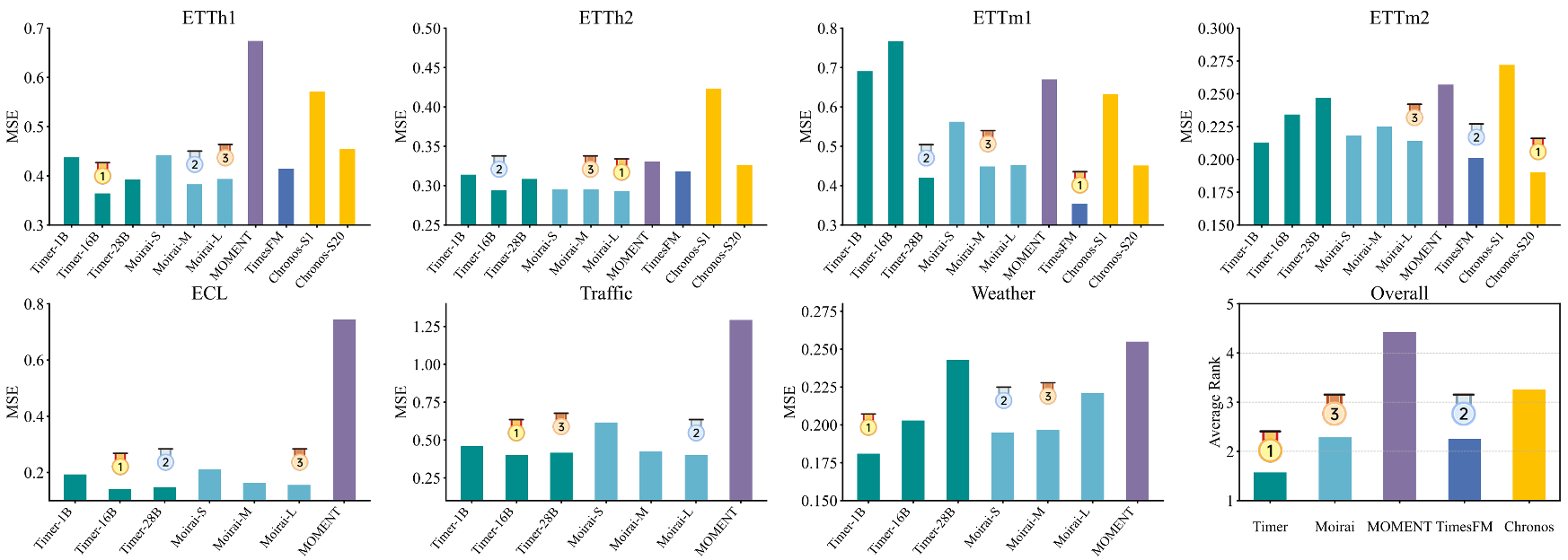
来源:ICML 2024 论文《Timer: Generative Pre-trained Transformers Are Large Time Series Models》
04 总结
伴随着越来越多研究成果的集中发布,我们能够感受到时序大模型正在迅速发展,在多个领域和应用中展现出巨大的潜力。
未来,随着技术的不断进步,预计将会有更多创新的方法和实践出现,我们期待以 Timer 模型为代表的时序大模型实现性能更大幅度的提升!
更多内容推荐:
• 了解如何使用 IoTDB 企业版


