

著名德语专业期刊《Java aktuell》精选了天谋科技解决方案专家、IT-OT 域资深专家 Christofer Dutz 的文章《Verteilte Datensammlung - Zeitserien-Daten mit Apache TsFile und Apache IoTDB》,其中详细介绍了 Apache TsFile 和 Apache IoTDB 技术在时序数据管理中的创新,对于 IoTDB 和 TsFile 如何应对自动化领域数据管理挑战进行了深入解析。
以下为翻译内容全文。
1. 前言
目前,人工智能和机器学习是无处不在的流行语。在物联网领域尤其如此,那里有一股真正的“淘金热”,而起到最关键作用的成分一定是:数据。乍一看,数据可用性不应该构成重大障碍,但魔鬼往往在细节中。在 POC 流程中中没有问题的数据,在传输或系统扩展过程中可能经常失败。
大多数传统数据库根本无法处理物联网环境中经常出现的庞大数据量,因为设备和测点的数量都可以迅速达到数万甚至数百万,数据采集的频率也通常很高。更糟糕的是有时没有适配的宽带互联网连接长期可用,而乱序数据,也就是“晚产生、先到了”的数据,可能是压垮大多数系统的最后一根稻草。
在本文中,我将解析 Apache IoTDB 和 Apache TsFile 是如何针对这些痛点进行开发的,以及为什么它们是能够解决物联网数据管理挑战的产品。
2. Apache IoTDB 的起源
清华大学软件学院王建民院长领导的团队在项目公关过程中,多次遇到前述介绍中的各类问题。因此,他和他的团队于 2011 年创立了 IoTDB 项目,这是一个针对物联网数据管理用例优化的数据库解决方案。自 2018 年 11 月以来,该项目成为 Apache 软件基金会旗下项目,自 2020 年以来,它毕业成为了全球 Top-Level 项目,并拥有庞大且不断增长的国际社区。
2023 年 10 月,Apache IoTDB PMC 投票决定将 Apache IoTDB 拆分为两个项目:Apache IoTDB 和 Apache TsFile。此举承认了 IoTDB 项目一直由两部分组成,因此如果未来几周或几个月项目架构有一些变化,请不要感到惊讶。
3. 写入数据的新方法
IoTDB 与其他数据库系统最大的区别可能在于存储引擎和存储格式与查询引擎是分离的。因此原则上,数据写入过程与稍后执行的分析过程可能发生在不同的系统中。
TsFile 存储格式包含了迄今为止来自 IoTDB 的最多专利,因为这是 IoTDB 中涵盖了许多开创性工作的部分。它允许无损数据存储,压缩率高达 95%(1:20)。如果不需要无损存储,压缩可以将数据存储空间占用减少 99%(1:100)。在这种格式中处理“稀疏数据”——并非所有数据都能从设备传感器上报,可能产生缺失的数据——也非常高效。
TsFile 文件不仅包含实际的时间序列数据,还包含模式信息。这种存储方式理论上允许 IoTDB 管理无上限数量的设备上报的数据,并为每个设备维护无限数量的数据列,而不会牺牲性能。相比其他已建立的解决方案通常在这两个维度中的一个或两个受到限制,IoTDB 明显存在优势。
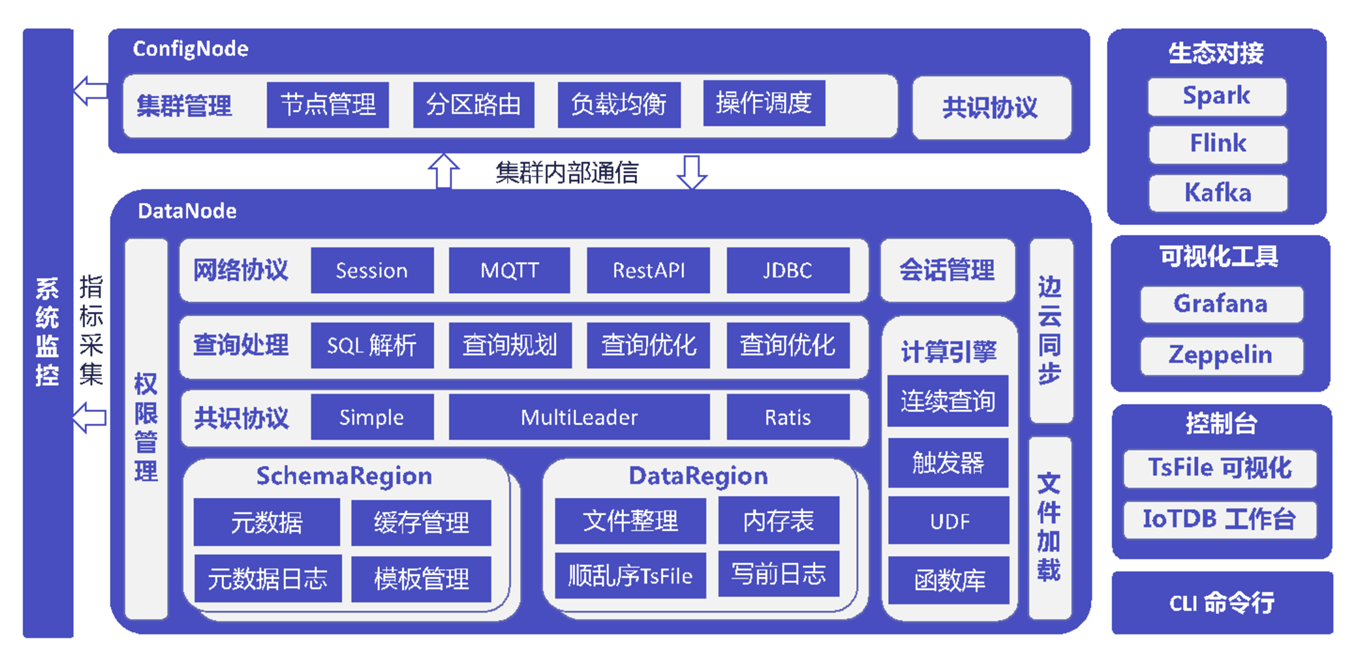
尽管 IoTDB 可以作为分布式系统运行,但它也可以作为常规数据库使用,这可能是最常见的使用方式。在这种情况下,IoTDB 可以作为数据存储和数据分析的核心组件。
有几种方法可以将数据导入 IoTDB 系统:
CLI
Session API
JDBC
MQTT
考虑到性能和可用功能方面,Session API 是导入首选。用户可以使用他们所需编程语言的 IoTDB 客户端进行数据导入。目前可用的语言有:
Java
Go
Python
Rust
C++
C#
而 JDBC 驱动程序可能是集成到现有解决方案时最简单的选择。
对我来说,目前最令人兴奋的数据导入方法是作为 MQTT 客户端向 IoTDB 提供数据。虽然 IoTDB 目前能够直接处理 JSON 格式的 MQTT 消息,但用户必须确保这些消息符合 IoTDB 系统的格式,因此上传数据的系统必须为接入 IoTDB 做好明确准备。而我目前正在研究使用 Sparkplug-B 适配器扩展 IoTDB,这能将 IoTDB 集成到现代工业解决方案中,且无需额外配置,因为 Sparkplug B 直接提供了必要的模式信息。同时,因为 Sparkplag-B 使用 Protobuf 进行有效载荷传输,也就使得传输过程比使用简单的 JSON 高效得多。Sparkplug B 已支持某些控件类型,但通常仍处于测试阶段。不过,我相信基于这项技术的解决方案将很快传播,因为它们解决了许多问题,例如 OPC-UA 带来的问题。
我想实现的第二个令人兴奋的数据导入方法是为已有的自动化系统(如 TwinCAT、Codesys、Step7)实现一个基于 C++ TsFile 的库,允许直接在控制系统上写入数据。自动化工程师可以将所需参数作为程序的一部分写入本地 TsFile,然后通过 MQTT 将其发送到 IoTDB 服务器。目前,PLC 的数字图像通常通过轮询来创建,而由于采样问题,采样频率必须始终是测量信号频率的倍数,因此许多采样请求会以近似所需的信号被发送到控制器。与传统方法相比,新方法具有显著的优势,因为它可以大大减轻 PLC 和网络的负担。此外,目前在轮询,即定期从外部客户端读取数据时,用户无法确保 PLC 不用暂停处理读取请求以执行实际 PLC 程序,然后再继续处理请求。在这种情况下,返回的信息也就不一定再适用了。因此,新方法还可以解决“周期同步数据”的问题,因为在这种情况下,关注的数据将始终在一个周期内写入。
由于 Apache IoTDB 完全用 Java 实现,因此也可以将 IoTDB 嵌入到现有的 Java 应用程序中。例如当 IoTDB 需要远程配置时,并不总是可以直接登录或通过 SSH 登录进行必要的更改。如果 IoTDB 可以通过嵌入的应用程序进行配置,这一点将尤其有用并提供巨大的优势。Timecho 天谋科技在博世力士乐 ctrlX 应用商店的应用程序中成功使用了这种方法,用户可以通过自定义 UI 直接更改数据库配置,而无需操作配置文件。
4. 多种数据访问选择
IoTDB 支持的客户端类型很多,因为已经为其他系统构建了许多集成:
CLI
Session API
JDBC
Apache Flink
Apache Hadoop
Apache Hive
Apache Spark
Apache Zeppelin
Grafana
Flink、Hadoop、Hive 和 Spark 等插件可以直接访问 TsFile,并在响应的集群中分发查询功能。用户甚至可以直接从 Grafana 商店安装 Grafana 插件,从而无缝访问 IoTDB。
除了常见的时间序列操作(例如基于时间戳的聚合操作),IoTDB 还支持多种用户自定义函数(UDF),可以非常方便的实现数据异常检测等功能。如果缺少某些没有涵盖其中的功能,用户还可以随时自定义新的 UDF。因为篇幅原因,此处就不列出所有可用的 UDF 了,可以在 IoTDB 项目网站上找到所有函数的详细列表。
5. 适用物联网场景
能够以分布式方式写入数据并高效地存储和转发数据,使得 TsFile 非常适合在物联网数据产生的地方直接采集数据。特别是对于分布式系统(如风电场、太阳能园区等),这大大简化了部署过程,因为数据可以临时存储在本地,然后以压缩批次的形式传输。如有必要,这些批次也可以适应数据传输技术,例如在使用 LoRaWAN 时,可以确保最大限度地利用可用带宽。
此外,在移动系统(如火车、轮船、飞机、卡车等)中,TsFile 支持的采集方式也非常有用,因为这类场景通常无法保证稳定的网络连接。在这种情况下,数据可以暂时存储,直到火车驶出隧道、船只到达港口或卡车驶出死区并重新建立连接。
即使使用支持千兆以上数据传输的工业以太网连接,在本地缓冲数据并以 TsFile 进行批量传输也可以带来许多优势。如前所述,许多自动化网络可能因过多的定期数据轮询而过载,通过主动从 PLC 写入压缩的聚合数据,可以显著减少这种过载。
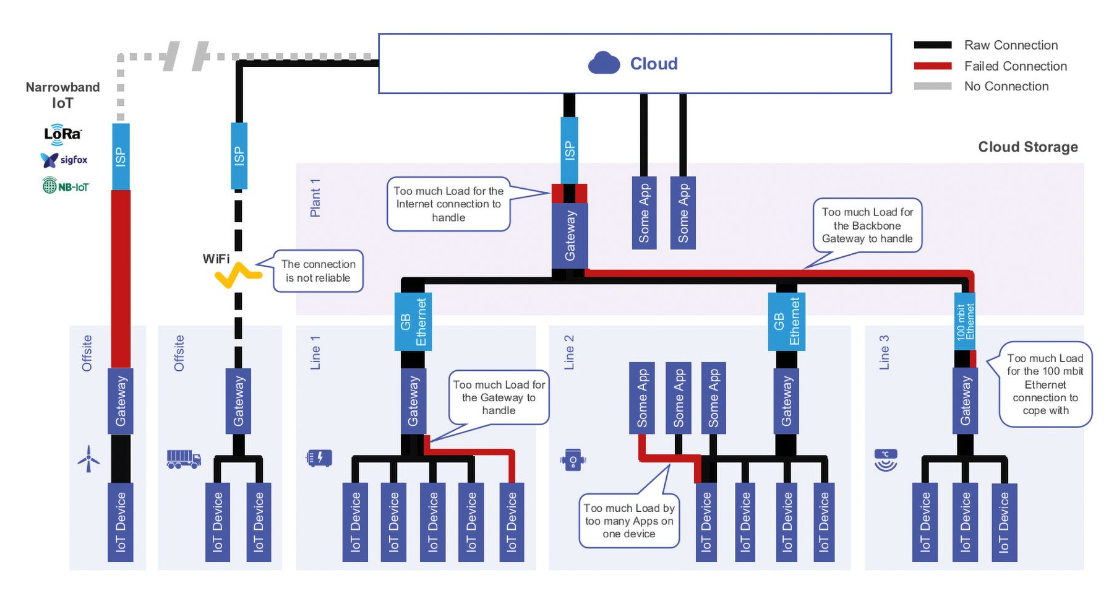
6. 高扩展性
IoTDB 可以在一个集群中运行,多个服务器或云节点可以组成一个 IoTDB 集群。由于数据和模式信息分布存储在 TsFile 上,IoTDB 查询引擎在集群运行中允许高并行处理,从而实现了无与伦比的查询性能。
IoTDB 也允许自动聚合时间序列数据,从而节省更多空间。例如,可以完全保留当月的数据,但删除或聚合特定的数据点,以便以分钟而不是毫秒的较低时间频率保留它们。你永远可以基于 IoTDB 实现更适配的存储方法。
特别是在工业生产中,数据库在企业里的多个层级上运行是很常见的。在生产线上,工厂运行所需的所有数据都将被收集和存储。在多条生产线上,数据通常会被转发到包含产品所有数据的更高级别的数据库,包括产品组的所有数据。再高一级,所有工厂的数据将被收集整合至云环境数据库进行存储。
这些分层数据存储方法真正落地时,应该很少能够实现。过去,我总能用一支铅笔、一张纸和一个计算器将所有工厂的所有数据从云环境中保存下来,而无需浪费大量预算。但现在,直接或通过中间实例传输和永久保留公司所有的数据根本不可能。几乎没有任何公司会拥有保存所有数据所必要的互联网连接或服务器容量,否则其成本将远远超过收益。以最细颗粒度存储所有层级上报的所有数据也意义不大,由于聚合计算量大、速度慢,在大多数系统中成本高昂,因此采样频率通常会降低。然而,上文提及的采样问题就会再现,导致存储数据的必要性也大大降低。
在这方面,IoTDB 可以从另一个角度,运用前面提到的自动聚合功能。例如,IoTDB 允许在生产工厂附近运行一个实例,该实例以最高频率存储所有数据,从而让企业能够快速准确地做出关于这部分业务的决策。在下一个更高的级别,IoTDB 的另一个实例会存储多个工厂的数据,但是这里的数据已经被过滤和聚合。不必要的数据将被省略,高频数据将以较低的频率进行聚合。虽然工厂仍在以毫秒为单位进行数据采样工作,但在这个更高的层级上,以秒或分钟为单位的数据通常足以支持企业做出正确的决策。这就确保了在企业每个层级,数据都保持必要的颗粒度,而不会产生不必要的成本或无法解决的问题。
7. 基准测试
公开信息表明,IoTDB 并不回避与其他时序数据库系统的比较。2023 年 9 月中旬,独立测试机构“benchANT”发布了对 Apache IoTDB 的性能分析对比结果,也证实了这一点。与所有其他经过相同测试的数据库相比,Apache IoTDB 在所有测试维度上都具备领先优势。benchANT 组织在一篇题为《Apache IoTDB:时序数据库的全新领导者》的博客文章中详细描述了测试结果。
其中,IoTDB 与德国应用环境中成熟的数据库解决方案,InfluxDB 和 TimescaleDB 的比较特别有趣:

benchANT 基准测试结果
8. 总结
我相信 Apache IoTDB 和 Apache TsFile 是解决当前海量时序数据处理难题的理想选择。最重要的是,我对这个解决方案的易用性感到非常兴奋。它只需要下载二进制包、解压并运行“sbin/start-standalone.sh”(或“.bat”)脚本,不需要集群或特殊的操作系统配置,也不需要任何其他依赖项,一个简单的 Java VM 就足以使用一个功能强大的时序数据库。就我个人而言,这两个项目都是我计划使用开源和现代 IT 解决方案和方法应对自动化行业挑战的重点。
更多内容推荐:
• 了解如何使用 IoTDB 企业版


